本文提出了 LanteRn,这是一个允许大语言模型(LMM)在隐空间进行视觉推理的框架。通过在文本生成中交织连续的视觉“思考”嵌入(Latent Thoughts),该方法在 Blink 和 V* 等感知基准测试中显著提升了细粒度推理能力。
TL;DR
当前的视觉大语言模型(LMM)大多是“视觉解析 + 文字推理”的模式。LanteRn (Latent Visual Structured Reasoning) 改变了这一现状,它允许模型在生成文本的过程中,插入连续的视觉特征向量(Latent Thoughts),直接在隐空间内进行视觉结构的“思考”。实验表明,这种方法在感知密集型任务上比纯文本 Reasoning 更有优势,且推理效率远高于像素级图像生成。
视觉推理的现状:被“语言”锁死的带宽
目前 LMM 的视觉推理面临两个极端:
- 纯文字化感知(Verbalization):将复杂的图像坐标、颜色、纹理强行压缩成文字。这就像试图用语言描述清明上河图的所有细节并进行逻辑推演,信息损耗极大。
- 像素级生成(Thinking in Pixels):在推理链中生成中间图像。这虽然保留了空间信息,但生成高清图像的计算开销巨大,且很多光影细节对于逻辑判断是完全冗余的。
LanteRn 的核心直觉:人类在思考物理问题时,脑海中会出现模糊的、抽象的概念模型,而不是一封说明信,也不是一张照片。那么,为什么不让模型直接在 Transformer 的 Hidden States 中维护这种“隐式图像”呢?
方法论:两阶段进化
LanteRn 构建在 Qwen2.5-VL 之上,通过三个特殊 Token <|lvr_start|>、<|lvr_sep|> 和 <|lvr_end|> 来控制推理模式的切换。
1. 有监督对齐 (SFT):建立视觉感官
在第一阶段,作者利用视觉编码器作为“教师”,将特定区域的特征图经过 Pooling 处理后作为 Ground Truth。模型在生成文本时,如果涉及到特定的视觉区域,必须学习在隐空间“重建”出这些特征(通过 MSE Loss 约束)。
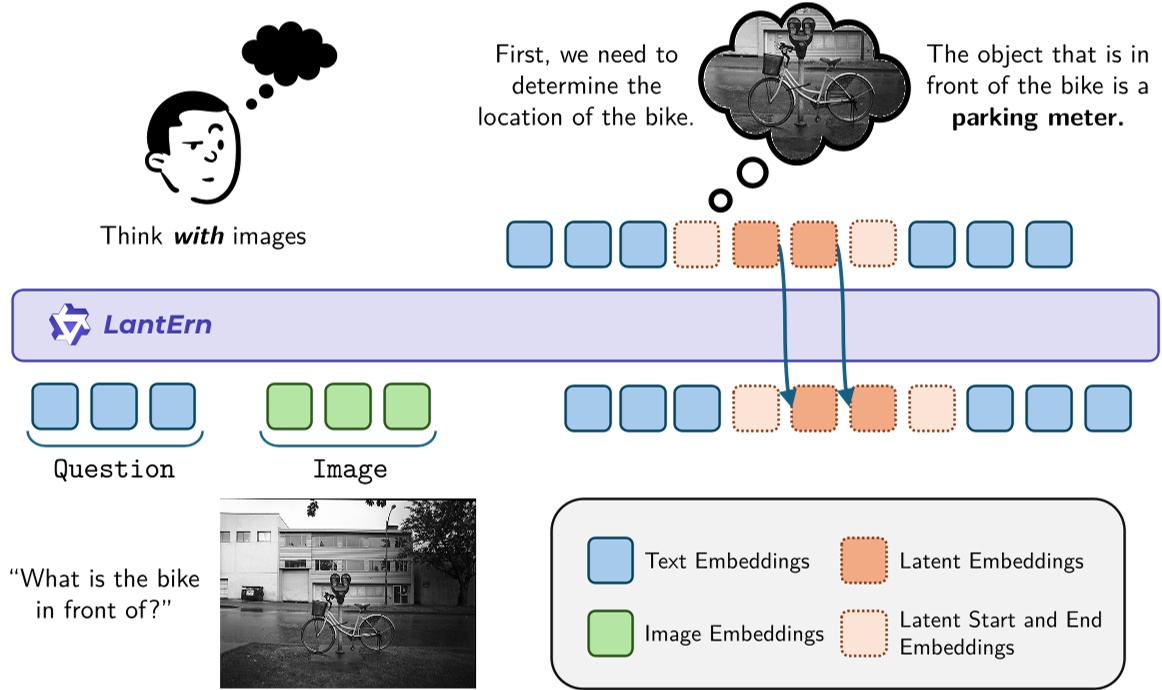 图 1:LanteRn 框架支持文本与隐式视觉表示交织推理,模型自动决定何时开启隐式推理模式。
图 1:LanteRn 框架支持文本与隐式视觉表示交织推理,模型自动决定何时开启隐式推理模式。
2. 强化学习 (RL):从“还原”到“求真”
SFT 只能教会模型“还原”图像,但无法保证还原出的特征对解题有用。为此,作者引入了 GRPO (Group Relative Policy Optimization) 强化学习:
- 混合动作空间:RL 同时优化离散的 Text Token 和连续的 Latent States。
- Latent Replay 机制:为了稳定训练,更新参数时会回放 Rollout 阶段生成的特定 Latent 向量,确保重要性采样比率的准确性。
- 奖励设计:主要驱动力是最终答案的正确性(Accuracy Reward),辅以格式奖励(Format Reward)。
实验结果:以小搏大的感知力
实验覆盖了 VisCoT, V* 和 Blink 等严苛的感知基准测试。
| 模型 | Blink (整体) | BlinkOL (定位) | BlinkRP (逻辑) | | :--- | :---: | :---: | :---: | | Qwen2.5-VL-3B | 0.65 | 0.48 | 0.81 | | LantErn-RL-8 (本文) | 0.68 | 0.54 | 0.81 |
 表 2:强化学习后的 LanteRn 在多个维度上显著超过了基线模型。
表 2:强化学习后的 LanteRn 在多个维度上显著超过了基线模型。
关键发现:RL 是发生质变的阶段。在 SFT 阶段,模型只是学会了感知对齐,而在 RL 后,模型学到了如何选择性地在隐空间中存储对任务有关键帮助的视觉信息,从而在空间定位(BlinkOL)和视觉关系处理上取得了飞跃。
深度洞察
为什么 Latent Reasoning 有效?
- 更高带宽:连续向量承载的信息密度远高于离散词表。
- 计算效率:绕过了昂贵的图像解码/编码过程,推理成本接近文本 CoT,但具备了类似图像编辑工具的中间表征能力。
- 自适应性:通过 RL,模型能够根据任务需求(如寻找隐藏物体 vs 判断物体运动方向)自发调整其隐式“视觉关注点”。
局限性与未来
目前 LanteRn 的 Latent Block 长度是固定的(如 8 或 16 个 Token)。这在处理极其复杂的视觉场景时可能存在瓶颈。未来的研究方向应该是动态 Latent 长度——让模型在遇到难题时多“想”几个视觉 Block,在简单题上快速跳过。
总结
LanteRn 为多模态模型的“慢思考”提供了一个高效的实现范式。它告诉我们,赋予 AI 视觉推理能力不见得需要让它学会“画图”,只需要让它在思考时,脑海中能留存一份准确的隐式“蓝图”即可。