本文提出了 LagerNVS,一种用于实时新视角合成(NVS)的编码器-解码器架构,核心利用了从预训练 3D 重建模型(VGGT)提取的隐式 3D 感知特征。该方法在不需要显式 3D 重建的情况下,实现了 SOTA 级的确定性前馈渲染,并在 RealEstate10k 等基准测试上取得了显著的性能提升。
TL;DR
LagerNVS 是一项突破性的研究,它证明了**“感知 3D,但不显式构建 3D”**是实现高质量、实时新视角合成(NVS)的最优解。通过将编码器初始化自预训练的 3D 重建网络(VGGT),并搭配高容量的“高速公路”架构,LagerNVS 在 RealEstate10k 任务中刷新了 PSNR 纪录(+1.7dB),且在 H100 上实现了 512px 解析度的 30+ FPS 实时渲染。
1. 动机:从“显式 3D”到“隐式几何”的跨越
传统 NVS 路线(如 NeRF 或 3D Gaussian Splatting)往往需要针对特定场景进行耗时的优化。虽然最近的前馈(Feed-forward)模型尝试加速这一过程,但它们要么受限于显式 3D 表示(如像素级高斯分布)导致的遮挡处理困难,要么因为严重缺乏 3D 归纳偏置(Inductive Bias)而导致画面扭曲。
核心 Insight:作者认为,即使不生成点云或体素,特征本身也应该是“懂几何”的。LagerNVS 的核心在于利用 3D 监督预训练所得的特征,将其作为 NVS 的强力起点。
2. 架构深度解析
LagerNVS 采用了Highway Encoder-Decoder架构。与传统的“瓶颈(Bottleneck)”结构不同,其信息流不会被压缩到极小的 token 集中,从而保留了极高的特征分辨率。
编码器 (The 3D-Aware Encoder)
系统并非从零训练。编码器基于 VGGT 权重初始化。虽然 VGGT 是为几何重建设计的,但其特征包含了极其丰富的深度和相机感知信息。
- 相机增强:通过 2 层 MLP 将相机参数投影为 Token,并注入特征主干,确保模型能理解拍摄视角。
- 端到端微调:不仅训练解码器,还对整个 3D Backbone 进行端到端优化,让原本“冷冰冰”的几何特征学会捕捉颜色、反射和透明度。
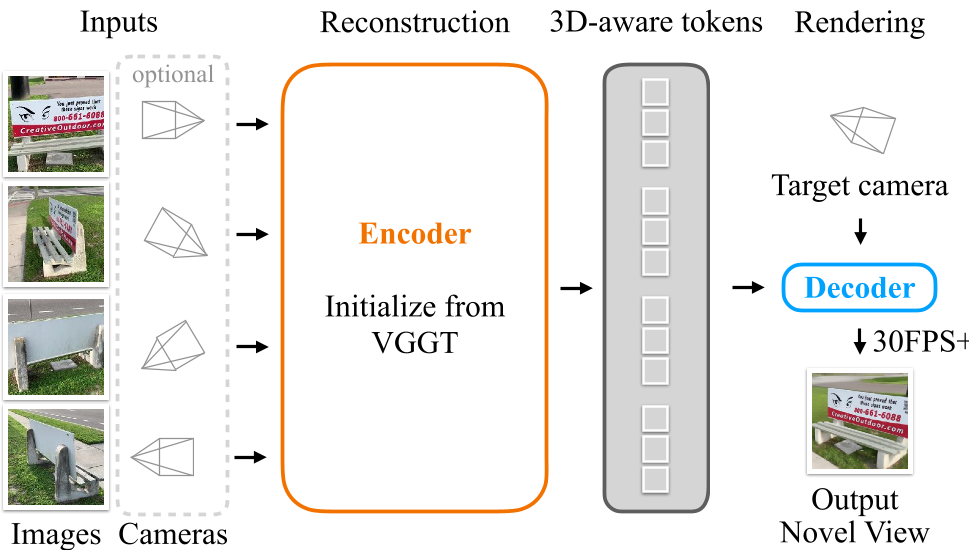
解码器 (Efficient Cross-Attention Decoder)
为了平衡质量与速度,LagerNVS 探索了多种注意力机制。最终采用双向交叉注意力 (Bidirectional Cross-attention):
- 目标相机生成 Plucker 射线图并 Token 化。
- 相机 Token 作为 Query 去检索源图特征,同时源图特征也反向感知相机位置。
- 这种设计使得渲染时间与源图像数量成线性(O(V))而非平方级增长。
3. 实验战绩对比
LagerNVS 在多个维度上展现了压倒性的优势:
- SOTA 刷榜:在 RealEstate10k 上比 LVSM 高出 1.7dB,远超以此前的 SOTA。
- 无感重建 vs 显式 3D:相比 DepthSplat(显式生成 3D 高斯),LagerNVS 在镜面反射面、细长结构(如金属栏杆)上的表现更佳,因为它避开了显式点云预测的对齐误差。

4. 泛化与外插:生成的潜力
LagerNVS 不仅限于回归(Regression)损失训练。通过将解码器重新目标化(Repurpose)为去噪扩散(Denoising Diffusion)迭代器,模型能够“幻觉”出源图中完全缺失的区域(如浴缸后的墙壁、道路转角的细节)。这种从确定性渲染到生成式渲染的平滑过渡,为未来的交互式虚拟漫游打开了大门。
5. 局限与未来展望
虽然 LagerNVS 在静态场景和实时性上表现惊艳,但在处理树叶等高频重复模式、动态人体以及鱼眼畸变镜头时仍有局限。未来的研究可能会引入视频扩散模型作为解码器,以增强视角间的时间一致性(Flicker-free)。
总结 (Takeaway): LagerNVS 告诉我们,3D 任务并不一定要有显式的 3D 表示,但必须有极致的 3D 偏置。这一“潜空间几何”的思想,极有可能成为下一代大规模元宇宙渲染的基础设施。