本文系统研究了扩散语言模型(DLM)的激活动力学,以 LLaDA-8B 为例发现其存在独特的“层塌陷”(Layer Collapse)现象。通过识别出的超级离群值(Super-Outlier)和权重谱分析,揭示了 DLM 在压缩鲁棒性及层间冗余分布上与自回归(AR)模型的本质反转。
TL;DR
在大型语言模型(LLM)的宏大版图中,扩散语言模型(DLM)正异军突起。然而,这项研究揭示了一个惊人的事实:DLM 的内部运作逻辑与我们熟悉的自回归(AR)模型(如 Llama)截然不同。DLM 存在一种层塌陷(Layer Collapse)现象,其前几层高度冗余且受控于一个极强的超级离群值(Super-Outlier)。这种结构使得 DLM 在极低比特量化下表现出惊人的鲁棒性,但也彻底颠覆了传统的剪枝常识。
1. 发现“超级离群值”:DLM 的致命软肋与核心支柱
在 AR 模型中,离群值(Outliers)通常只出现在特定的 Token 位置。但在 LLaDA-8B 中,研究者发现了一个持久存在的超级离群值通道(Channel 3848)。
- 物理直觉:这个通道像是一个恒定的偏置(Bias),在所有 Token 位置和前一半的所有层中持续保持极高的激活强度(比次高离群值大 5 倍)。
- 毁灭性实验:如果仅仅剪掉这一个通道,LLaDA 的推理能力会瞬间崩塌,输出变成无意义的重复循环;而 Llama 剪掉最强通道后性能仅下降 4%。
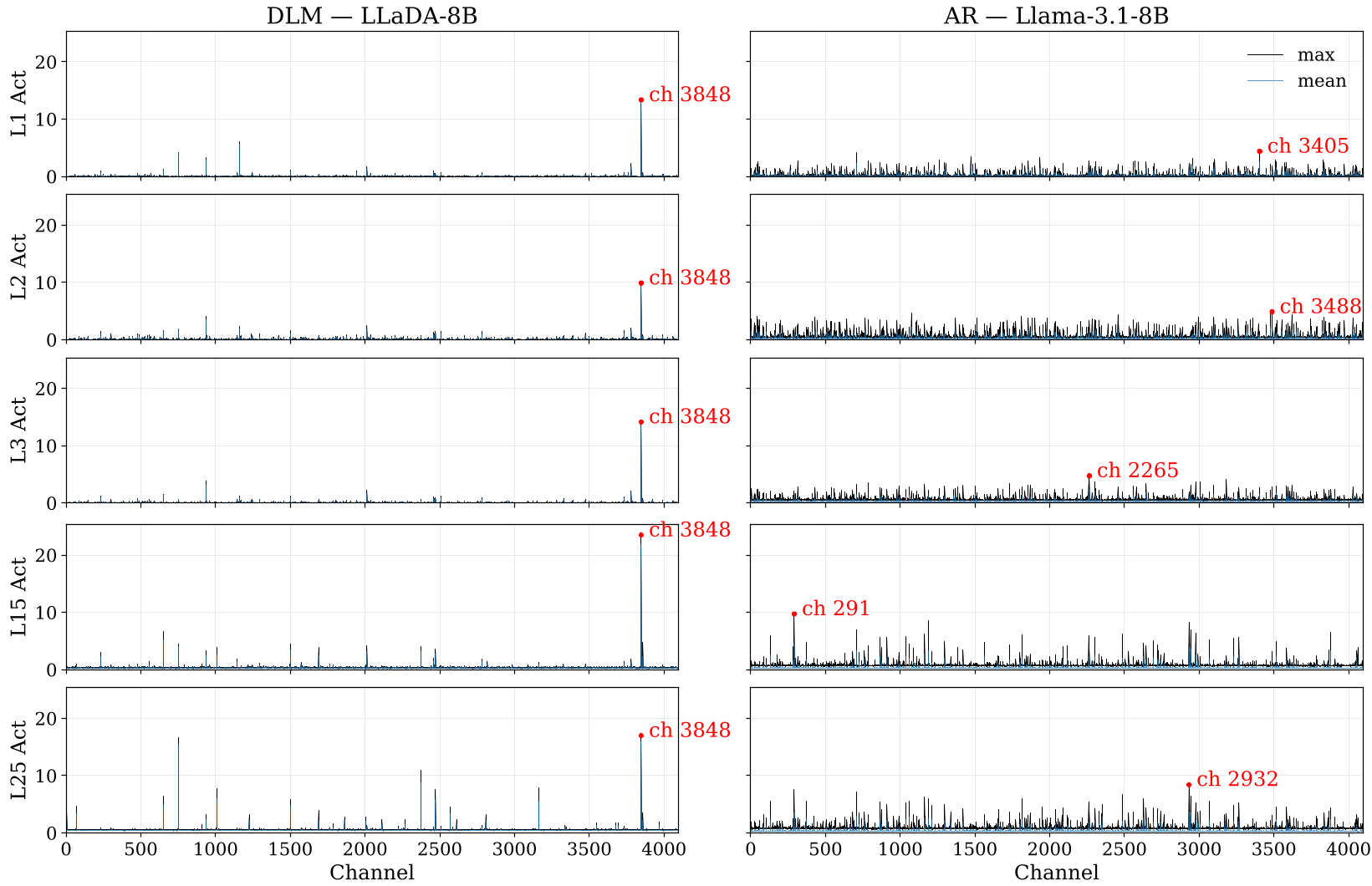 图中可见 LLaDA(左)存在一个横跨多层的统治性通道,而 Llama(右)的优势通道随层剧烈切换。
图中可见 LLaDA(左)存在一个横跨多层的统治性通道,而 Llama(右)的优势通道随层剧烈切换。
2. 层冗余的“镜像反转”
在学术界,AR 模型普遍存在“深度诅咒”:即前层表征独特,深层表征由于训练不足(Undertraining)而变得高度相似(冗余)。 DLM 却完全相反:
- 前层塌陷:LLaDA 的前 15 层表征几乎完全等价,余弦相似度极高。
- 过度训练(Overtraining):通过 Hill 估计器分析发现,DLM 前层并非因为偷懒没学好,而是因为“学过头了”,导致表征空间坍缩到了少数几个维度上。
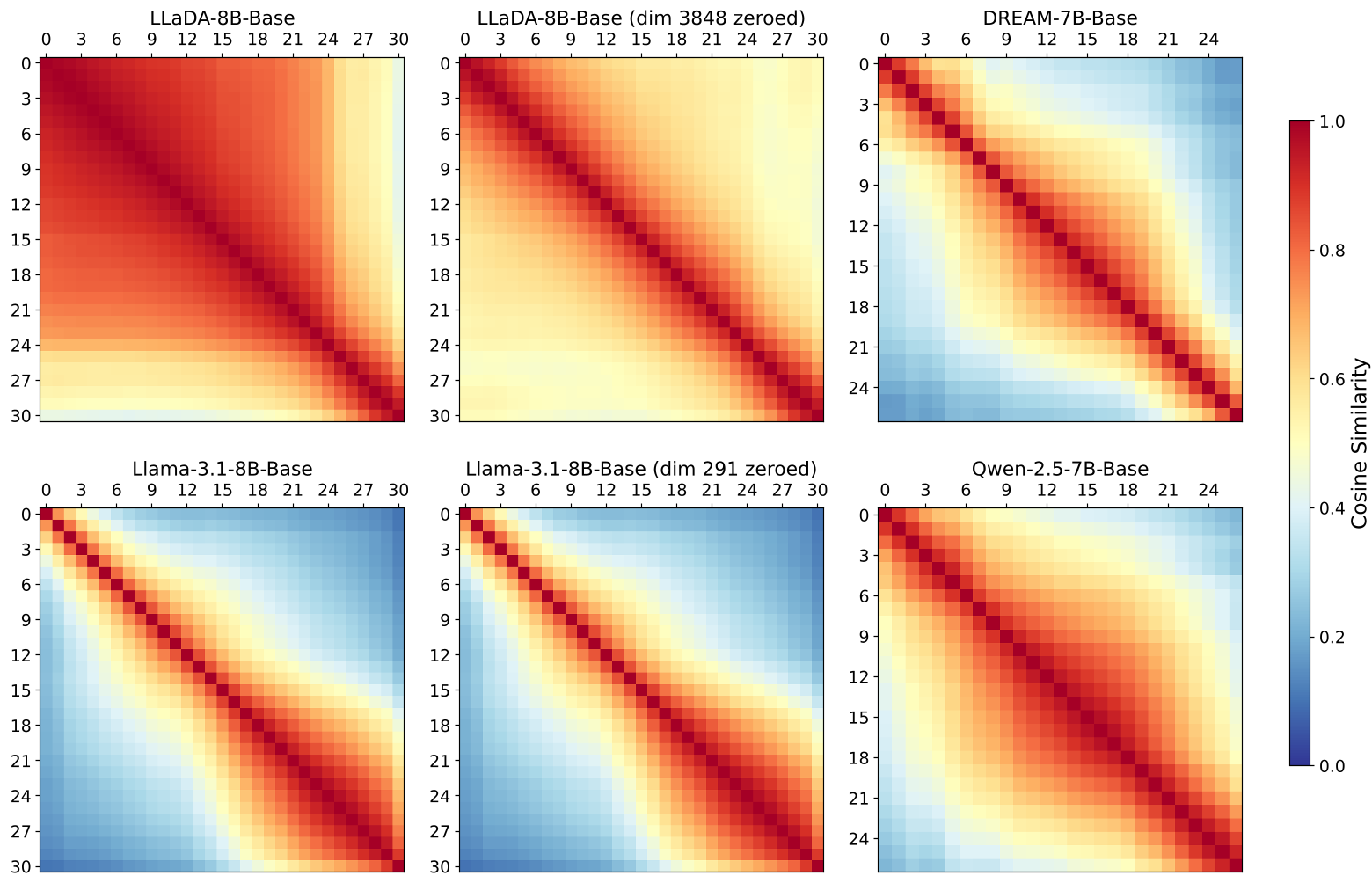 矩阵热图清晰显示:LLaDA(左上)在前层拥有巨大的暗红色高相似度区域,这在 Llama(左下)中是看不到的。
矩阵热图清晰显示:LLaDA(左上)在前层拥有巨大的暗红色高相似度区域,这在 Llama(左下)中是看不到的。
3. 颠覆性的实践:为何 DLM 更抗压?
这一发现对模型压缩具有深远的指导意义:
- 极端量化鲁棒性:由于 DLM 的层间冗余巨大且信息集中,它对量化误差极其不敏感。在 3-bit GPTQ 量化下,DLM 几乎维持了原有力,而 Llama 已经逻辑混乱。
- 剪枝策略倒置:
- AR 经验:由于后层冗余,应该多剪后层(Deeper-is-Sparser, DIS)。
- DLM 新规:由于前层塌陷,应该多剪前层(Earlier-is-Sparser, EIS)。实验证明,EIS 在 DLM 上比 DIS 准确率高出 8.4%。
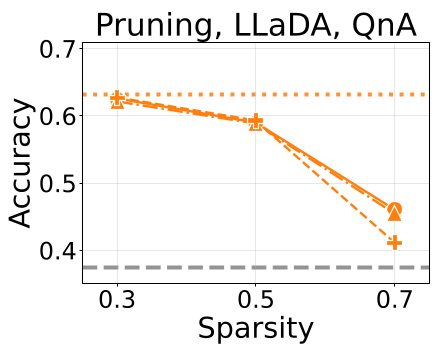 实验数据证明,在不同稀疏度下,DLM(实线)的性能跌幅远小于 AR(虚线)。
实验数据证明,在不同稀疏度下,DLM(实线)的性能跌幅远小于 AR(虚线)。
4. 深度洞察:是 Bug 还是算力的礼赠?
通过对 160M 参数的小模型进行受控实验,作者确认这种现象并非 LLaDA 独有的“架构缺陷”,而是由**扩散训练目标(Masked Diffusion Objective)**直接导致的。
总结与思考:
- 价值:这项工作为 DLM 的高效部署指明了方向——不要怕剪掉 DLM 的前层,也不要怕极低比特量化。
- 局限:这种“层塌陷”是否暗示了当前的 DLM 训练效率其实极低?既然前 15 层都在做同样的事,我们是否可以设计更紧凑的架构?
- 未来:超级离群值在 DLM 信息处理中到底扮演了什么角色?是噪声屏障还是全局语义的载体?这将是下一个研究热点。
资深主编点评:这篇论文最精妙之处在于它不仅展示了扩散模型“好用”或者“耐压”,更揭示了其在表征动力层级与自回归模型的本质非对称性。对于追求极致侧端部署的研究者来说,这不啻为一份 DLM 压缩指南。