本文提出了 LeapAlign,一种针对 Flow Matching 模型的高效微调(Post-training)方法。该方法通过构建包含两个 "跳跃"(Leaps)的短轨迹,实现了从奖励模型到生成早期阶段的直接梯度回传,在 Flux 模型上显著提升了图像质量和图文一致性(SOTA 成就)。
TL;DR
传统的扩散模型或 Flow Matching 模型微调往往困于“显存溢出”与“梯度爆炸”,导致开发者只能修补最后几步生成。LeapAlign 通过一种巧妙的“两步跳跃轨迹”逻辑,不但实现了全轨迹(包含决定全局结构的早期步骤)的梯度回传,还通过“梯度折扣”保住了被前人丢弃的跨步骤关联信号,在 Flux 等 SOTA 模型上实现了质的对齐飞跃。
背景定位:微调中的“早期难题”
在 Text-to-Image 领域,生成过程的早期阶段(Timestep 接近 1.0 时)决定了图像的骨架和布局,而后期则负责细节填充。目前主流的微调手段分为两类:
- RL-based (如 GRPO):不要求微分,但方差大、收敛慢。
- Direct-Gradient (直接梯度):利用采样过程的可微性回传奖励。
然而,直接梯度方法面临一个死结:反向传播路径越长,显存占用越高且梯度越容易崩坏。此前的 SOTA 工作(如 DRTune)为了保住显存,选择截断模型输入梯度,但这就像是“只修零件,不看组装”,丢失了步骤间的动态联系。
核心动机:为什么要“跳着走”?
作者观察到 Rectified Flow 具有极强的线性外推潜力。既然不能全量回传,能不能把长达 25-50 步的采样路径,“压缩”成可微分的几步“大跳”?
方法论详解:两步跳跃与梯度折扣
1. 两步跳跃轨迹 (Leap Trajectory)
LeapAlign 不再计算完整的 ODE 链条。它在训练时先进行一次完整的 Forward 采样,然后随机选取两个时间点 和 ,构建如下路径:
- Step 1: 从噪声 直接预测跳跃后的中间状态 。
- Step 2: 从 结合潜空间连接器,直接预测最终结果 。
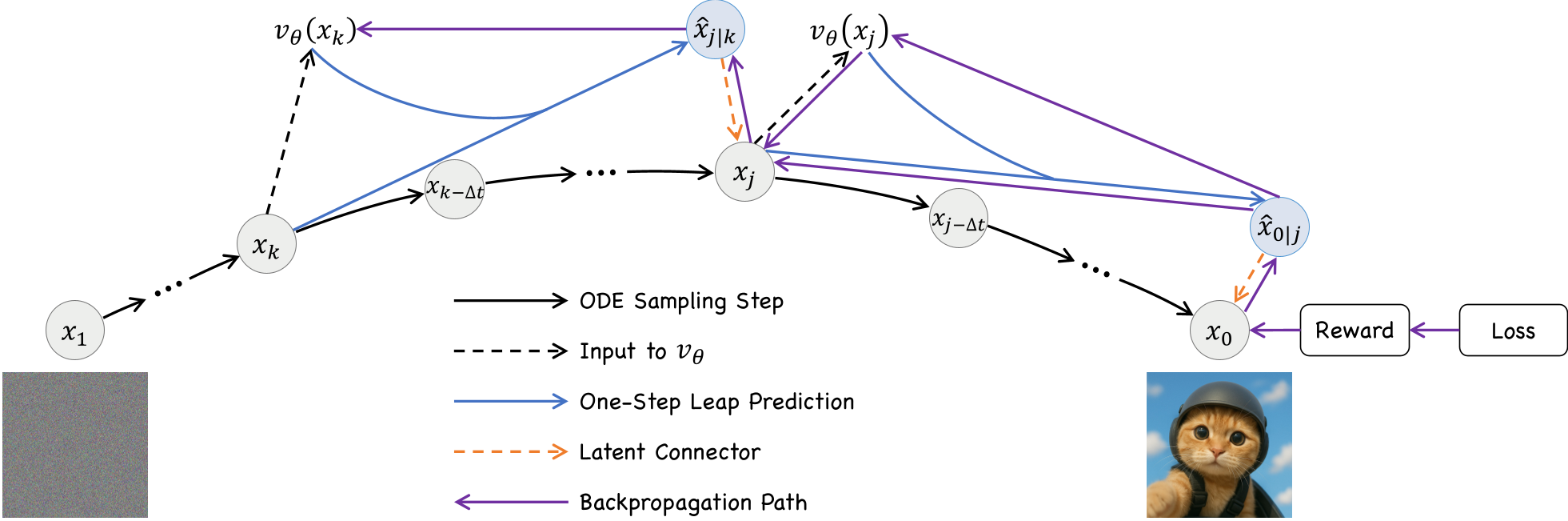 如图所示,通过 Latent Connector 连接真实采样点与预测点,保证了梯度的连续性,同时将反向传播的深度固定在“2次模型调用”的极低水平。
如图所示,通过 Latent Connector 连接真实采样点与预测点,保证了梯度的连续性,同时将反向传播的深度固定在“2次模型调用”的极低水平。
2. 梯度折扣 (Gradient Discounting):保住 Nested Gradient
这是本文最具数学直觉的部分。全梯度可以分解为“单步梯度”和“嵌套梯度(Nested Gradient)”。
- DRTune 的做法:直接把嵌套项扔掉。
- LeapAlign 的做法:引入折扣系数 (如 0.3)。 公式为:。
这样做既保留了步骤间的耦合信号,又避免了梯度量级瞬间爆炸,实现了训练的稳定性。
实验与结果:全方位吊打基线
在对顶级模型 FLUX.1-dev 的微调实验中,LeapAlign 展示了强大的统治力:
- 组合对齐 (GenEval):在“两个物体”、“空间位置”等布局敏感任务上提升巨大。这意味着微调早期步骤确能改变布局。
- 通用偏好:在 HPSv2.1 奖励曲线上,LeapAlign 的上升斜率和最终点位均显著优于 DRTune。
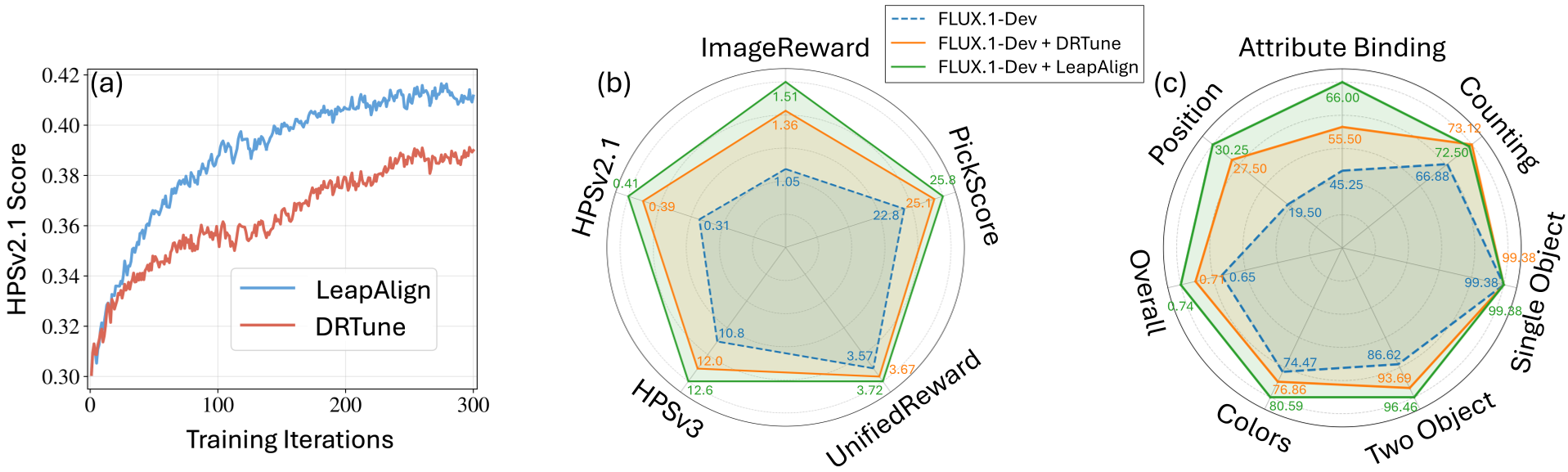 雷达图清晰地显示,LeapAlign 在图文对齐(GenEval)和视觉偏好(HPS)上均优于现有的 GRPO 和直接梯度方法。
雷达图清晰地显示,LeapAlign 在图文对齐(GenEval)和视觉偏好(HPS)上均优于现有的 GRPO 和直接梯度方法。
深度洞察
LeapAlign 的成功归功于对 Rectified Flow 数学特性 的深度利用。
- Why it works? 它的跳跃预测本质上是对 ODE 轨迹的一阶近似。由于采用了“随机采样时间点”策略,模型在训练过程中实际上被迫学习了如何从任意起始点精确地导向高 Reward 的终点。
- 相似度加权的妙用:作者加入的 实际上是一个正则化项。如果某次“跳跃”偏离原本的 ODE 路径太远,该梯度会被抑制。这确保了微调后的模型不会为了骗分而产生违背物理逻辑的轨迹(Reward Hacking)。
总结与局限
Takeaway: LeapAlign 解决了大模型微调中“早期步骤难更新”的长久痛点,且显存效率极高。 局限性: 虽然该方法在 Rectified Flow 上表现完美,但在非线性调度的传统扩散模型(如 SD1.5/SDXL 的某些 Scheduler)上,这种线性跳跃预测的偏差可能会增大,需要更复杂的积分近似。
未来,这种“压缩轨迹后对齐”的思想极有可能在 视频生成(Sora-like models) 领域大放异彩,因为视频的时间轴更长,全路径回传几乎是不可能的。