本文提出将大语言模型(LLM)训练过程视为一种“有损压缩(Lossy Compression)”过程,利用信息瓶颈(Information Bottleneck, IB)理论阐述模型如何通过遗忘无关信息来学习。研究通过分析 OLMo2 等多个开源模型家族,证实了 LLM 预训练遵循“先扩张表示、后优化压缩”的两阶段动力学轨迹。
TL;DR
为什么大模型在见过数万亿个 Token 后能产生智能?本文给出了一个极具物理直觉的解释:LLM 的训练本质上是一个“有损压缩”过程。模型不仅在学习如何预测下一个词,更在学习如何“遗忘”掉训练数据中那些对预测目标无关紧要的噪声。研究发现,高性能模型在信息平面上更接近理论上的信息瓶颈(Information Bottleneck, IB)边界。
背景定位
在学术坐标系中,这项工作成功地将经典的 信息论(Information Theory) 与现代 大规模语言模型(LLM) 的表示学习联系了起来。它不再局限于研究某个特定电路(Mechanistic Interpretability),而是从全局视角审视模型作为一个整体是如何进化的。
核心直觉:为什么要“遗忘”?
在有损压缩(如 MP3 或 JPEG)中,为了节省空间,我们会丢弃人类听觉或视觉无法察觉的频率。作者认为 LLM 也在做同样的事情:
- 复杂度(Complexity, I(X;Z)):模型保留了多少关于输入的信息。
- 表达力(Expressivity, I(Y;Z)):模型保留的信息中有多少能有效预测输出。
一个完美的模型应该用最少的复杂度实现最大的表达力。这就是所谓的“最优压缩”。
动力学详解:预训练的两阶段轨迹
通过对 OLMo2 家族模型的追踪,作者观察到了极其清晰的两个阶段:
- 拟合阶段(Fitting Phase):模型快速吸收信息,I(X;Z) 和 I(Y;Z) 共同上升。
- 压缩阶段(Compression Phase):随着训练损失进入平台期,模型开始“清理”表示空间,降低 I(X;Z) 同时保持甚至提升 I(Y;Z),向 IB 边界靠拢。
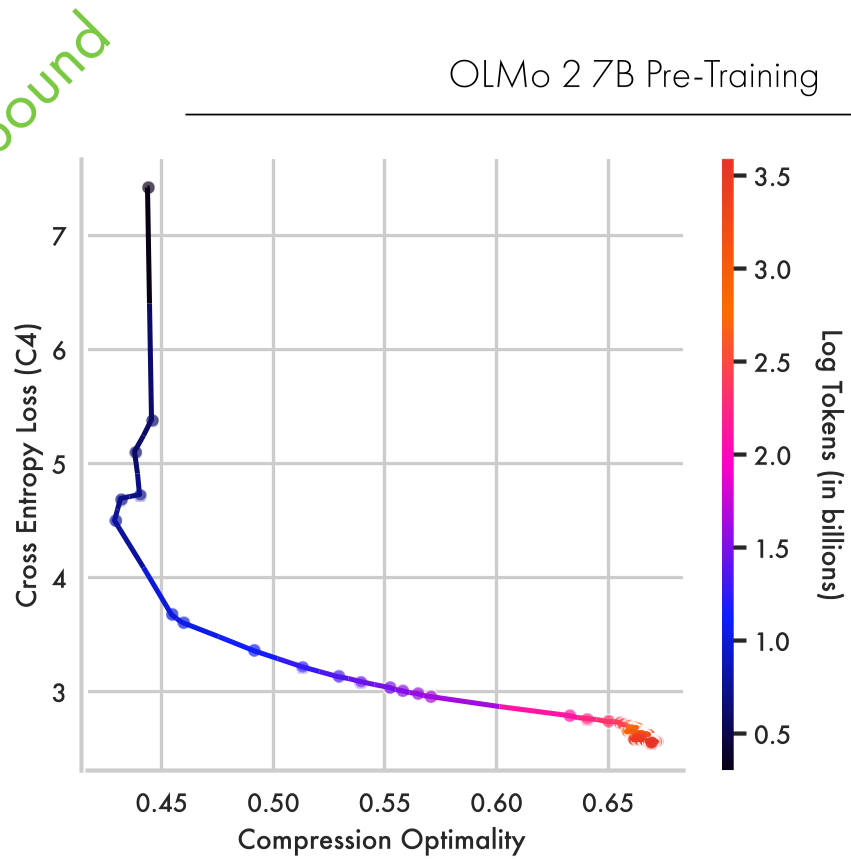 (左图:不同规模模型在信息平面的轨迹;右图:压缩过程与训练损失的对应关系)
(左图:不同规模模型在信息平面的轨迹;右图:压缩过程与训练损失的对应关系)
关键发现:规模与性能的真相
1. 规模决定压缩能力
研究发现,1B 以下的小模型几乎不经历压缩阶段。在预训练后期,小模型会在信息平面上“徘徊”甚至远离边界,而 7B 和 32B 模型则能持续优化压缩效率。这从信息论角度解释了为什么 Scaling Laws 是有效的——大参数量提供了实现更优压缩的拓扑冗余。
2. 压缩最优性 = 性能
作者通过对比 47 个开源模型(包括 Llama, Gemma, Qwen 等)发现,一个模型在 C4 数据集上的“压缩最优性”与其在 MMLU、Math 等基准测试上的表现显著正相关。
- 有趣的事实:高性能模型往往拥有更低的 Token 级复杂度,但拥有更丰富的长程上下文信息(Bigram/Trigram 层面的互信息更高)。
 (图示:各大家族模型最终都收敛在 IB 边界附近,表现越好的模型越靠近左上方边界)
(图示:各大家族模型最终都收敛在 IB 边界附近,表现越好的模型越靠近左上方边界)
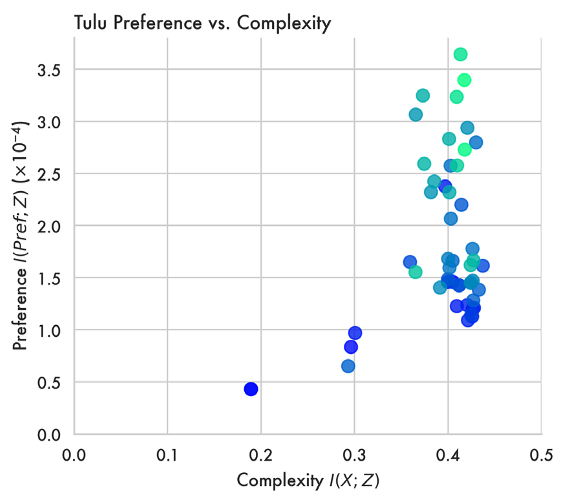
3. 指令遵循与偏好信息
研究进一步探讨了后训练(Post-training)的作用。虽然预训练决定了模型的“基本盘”(通用压缩效率),但 SFT 和 RLHF 则是通过注入“偏好信息(Preference Information)”来微调压缩的内容。实验显示,模型内含的偏好信息量能以 r=0.76 的极高相关度预测其 IFEval 成绩。
深度洞察与总结
这项工作具有重大的工程指导意义:
- 停止准则:我们或许不应只看 Loss 指标,当模型的“压缩最优性”不再提升时,增加训练时长可能已无边际收益。
- 模型筛选:在没有运行昂贵基准测试的情况下,通过一次 Forward pass 计算熵值,即可初步判断一个 Checkpoint 的潜力。
局限性:目前的熵估计方法主要基于余弦相似度,忽略了增量(Norm)信息。未来研究若能涵盖向量模长的统计特性,将进一步完善这一压缩理论。
总结:LLM 的智能不是通过简单的堆砌数据获得的,而是通过在海量噪声中提炼出那一点点“预测未来”所必需的本质信息。学会学习,首先要学会遗忘。