本文提出了 Autocurriculum(自动课程学习)机制,用于优化大语言模型的 Chain-of-Thought (CoT) 推理训练。核心方法 AutoTune 通过模型自评(配合验证器)动态选择难点样本进行有针对性的监督微调 (SFT) 或强化学习 (RL),在数学和代码等可验证任务上实现了 SFT 样本需求量级的指数级降低。
TL;DR
在学术界疯狂通过增加计算量(Test-time Compute)来暴力提升模型推理能力的今天,DeepMind 与顶尖院校的研究者另辟蹊径,从训练效率入手。本文提出的 Autocurriculum(自动课程学习) 理论框架证明了:如果模型能根据自己的掌握程度“挑选”练习题,其所需的专家演示(CoT)数量可以实现指数级减少。 该方法在 SFT 时将样本需求与精度解耦,在 RL 时将计算量与模型初始覆盖率解耦。
痛点深挖:昂贵的推理标签与无效的 RL 计算
目前的推理模型(如 o1, DeepSeek-R1 系列)训练面临两大瓶颈:
- SFT 阶段:收集高质量的 CoT 推理轨迹极其昂贵。非自适应的方法(Non-adaptive Fine-tuning)会给模型喂入大量它已经学会的简单样本,这不仅浪费了标注成本,还可能导致“灾难性遗忘”或过拟合。
- RL 阶段:强化学习(RLVR)在没有专家轨迹的情况下通过验证器(Verifier)进行自我提升。但如果初始模型能力较弱(Coverage 低),它需要生成天文数字级别的无效 Token 才能“碰巧”撞到一个正确答案,计算资源浪费严重。
核心直觉:AutoTune 的“错题本”机制
作者提出的核心工具是 AutoTune。其背后的物理直觉非常接近人类学习:专注于错题。
1. SFT 的指数级加速
AutoTune 借鉴了经典机器学习中的 Boosting (提升法) 思想。在每一轮迭代中,模型先在验证器上自测,识别出那些即使经过当前训练仍无法解决的“死角”样本。只有这些样本才会去请求昂贵的“老师”(专家模型)提供 CoT 标注。
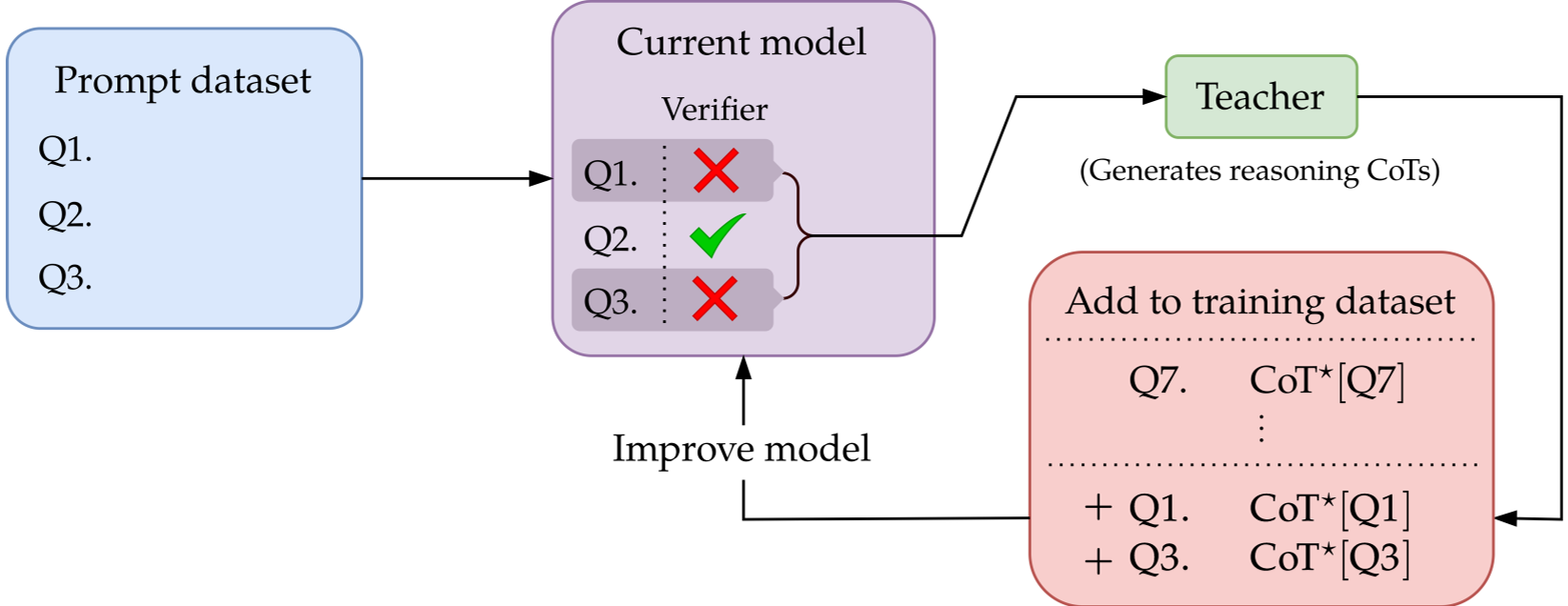 上图展示了 SFT 下的 Autocurriculum:学习器根据其在该 Prompt 上的准确率决定是否获取专家的 CoT 演示。
上图展示了 SFT 下的 Autocurriculum:学习器根据其在该 Prompt 上的准确率决定是否获取专家的 CoT 演示。
2. RL 中的 Coverage 解耦
在 RL 任务中,模型面临所谓的 Coverage(覆盖率) 挑战。作者证明了通过 Autocurriculum,可以将“找到第一个正确答案”的搜索成本转化为一次性的 Burn-in(预热) 开销。
- 传统方法:需要持续投入 比例的计算量来维持对高精度目标的探索。
- AutoTune 方案:一旦在某些难点上突破了初始覆盖率限制,后续提升精度阶段的成本将几乎与初始模型的能力无关。
理论成就与实验表现
本文最大的亮点在于其可证明的收益(Provable Benefits)。研究者通过数学推导给出了下表的复杂度对比:
| 任务设置 | 传统非自适应方法 (No curriculum) | 自动课程学习 (Autocurriculum) | 改进点 | | :--- | :--- | :--- | :--- | | SFT (专家轨迹数) | | | 指数级节省 | | RL (生成采样次数) | | | 覆盖率与精度解耦 |
表格注: 为目标误差, 为参考模型覆盖系数。
实验直观图解
算法通过 Rejection Sampling(拒绝采样) 不断重塑数据的分布权重。如下图所示,随着阶段 的推进,权重 α 逐渐向那些模型尚未攻克的“高难度/低 Rank”区域偏移:
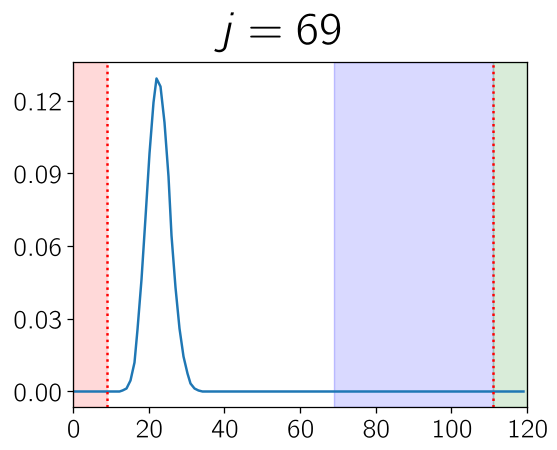 图 (a)(b) 展示了随着模型迭代,学习重点(绿色区域)是如何动态调整的。
图 (a)(b) 展示了随着模型迭代,学习重点(绿色区域)是如何动态调整的。
深度洞察:为何这在 AI 工业界很重要?
这篇文章不仅是理论推演,它还为诸如 DeepSeek-R1 的“生成-过滤-再训练”循环(ReST 机制)提供了严格的数学支撑。
- Inductive Bias(归纳偏置):该论文告诉我们,不需要对 Prompt 分布做任何先验假设,单纯依靠模型自测试的反向路由,就能捕捉到数据中的结构信息。
- 现实意义:通过 AutoTune,我们可以在保持相同精度前提下,将昂贵的合成数据生成成本降低 1-2 个数量级。
局限性与展望
尽管取得了理论突破,但本文仍基于 Perfect Verification(完美验证器) 的假设。在数学和编程任务中这很自然,但在主观对话或开放式写作中,如何定义“正确”的验证器依然是悬而未决的问题。此外,文章提到的“多阶段专家迭代”在在线 RL(如 PPO 流程)中的适应性仍需进一步探索。
总结一句话:不要再给你的模型喂重复的“营养”,让它学会寻找自己的“短板”,那才是性价比最高的训练之路。