本文提出了 Learning to Self-Evolve (LSE),一种通过强化学习(RL)训练大语言模型(LLM)在测试时通过迭代优化自身 Prompt 上下文来提升性能的框架。实验表明,仅有 4B 参数的模型经过 LSE 训练后,在 Text-to-SQL 和通用 QA 任务上的表现超越了 GPT-5 和 Claude 3.5 Sonnet 等顶级模型。
TL;DR
传统 LLM 在部署后是“静态”的,无法从解决问题的经验中学习。本文提出的 Learning to Self-Evolve (LSE) 框架通过强化学习,专门训练模型在测试时根据环境反馈(Feedback)重写自己的 Context(指令/技巧库)。结果令人惊叹:一个经过 LSE 训练的 Qwen3-4B 模型,在 Text-to-SQL 等复杂任务上的进化能力竟超越了 GPT-5 和 Claude 3.5 Sonnet。
痛点深挖:静态模型的“部署即终点”
目前的 LLM 训练流程在 post-training 阶段虽然使用了 RL,但一旦部署,策略便冻结了。
- 经验浪费:模型解决了一万个相同领域的问题,其 Prompt 依然保持不变,无法积累领域知识。
- 推理能力局限:现有的自改进方法(如 Reflexion, TextGrad)全靠模型“悟性”,没有针对“如何根据失败案例修改指令”进行过专项训练。
- 容易跑偏:单纯的线性进化(修改 A -> 修改 B)一旦某一步改错了,模型性能会崩盘且无法恢复。
核心机制:LSE 的“单步进化”与“树状搜索”
1. 改进量奖励(Improvement-based Reward)
LSE 的核心直觉是:不要奖励模型“改完后得分多高”,而要奖励它“比原来进步了多少”。 公式定义如下: 这种设计利用初始分数 作为天然的 Baseline,有效抵消了任务难度的影响。它强迫模型学习“什么样的编辑能变强”,而不是“保住原来的好 Prompt 不动”。
2. 模型架构与进化循环
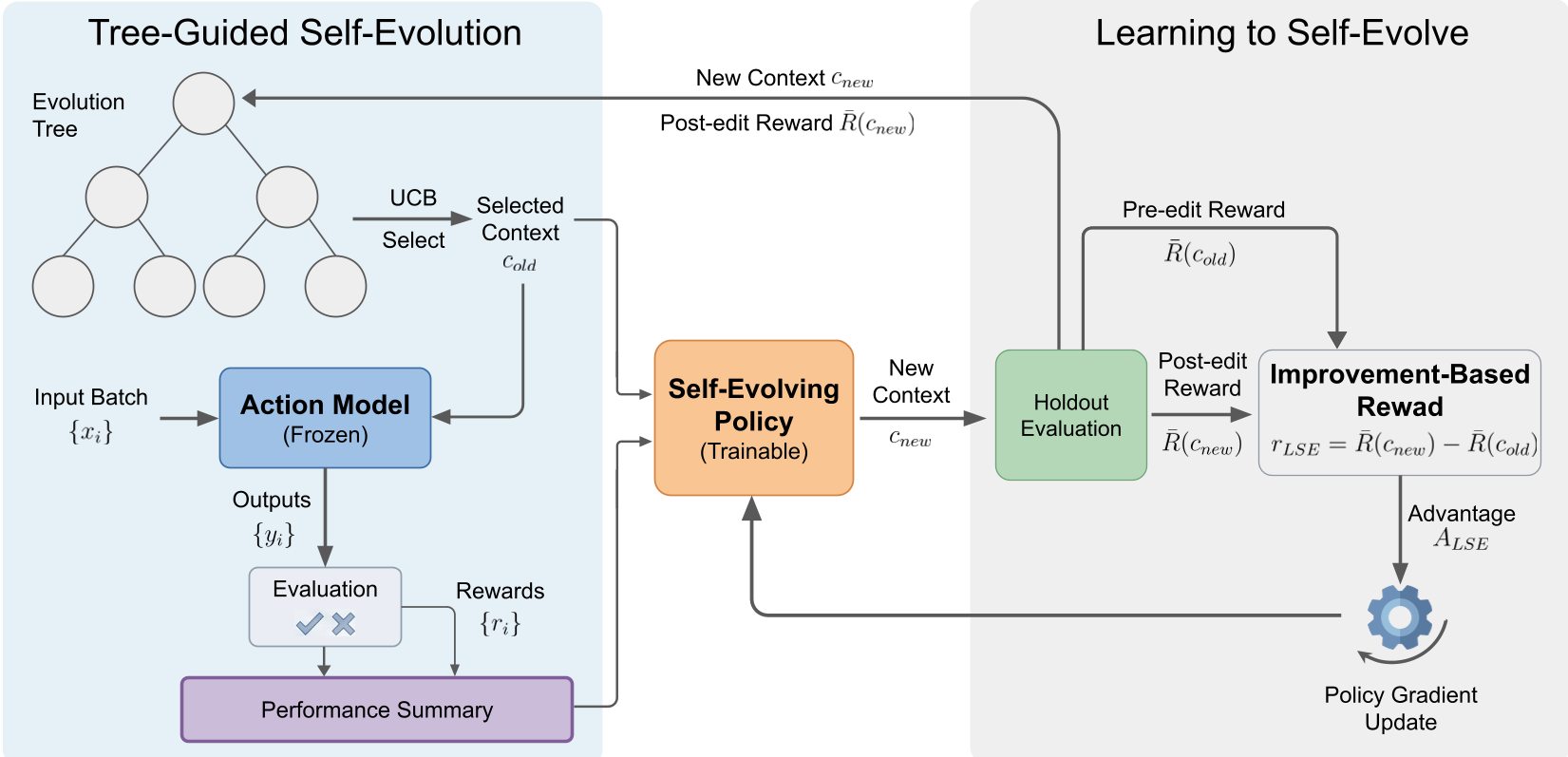 图 1:LSE 框架。左侧为测试时树搜索进化,右侧为带改进奖励的 RL 训练流程。
图 1:LSE 框架。左侧为测试时树搜索进化,右侧为带改进奖励的 RL 训练流程。
在测试阶段,LSE 不再单纯走“直线”,而是维护一棵进化树。利用 UCB (Upper Confidence Bound) 算法,系统会在“尝试新修改”和“回到之前表现最好的 Prompt 重新改”之间寻找平衡。这样即使某次修改让性能大跌,模型也能通过回溯(Backtrack)自救。
实验战绩:越级打怪的 4B 模型
在 BIRD (Text-to-SQL) 数据库任务中,LSE 展现了恐怖的适应力:
| 方法 | 平均准确率 (%) | | :--- | :--- | | Seed Prompt (原始) | 57.2 | | GPT-5 (自进化) | 65.2 | | Claude 3.5 Sonnet | 64.5 | | LSE (Qwen3-4B) | 67.3 |
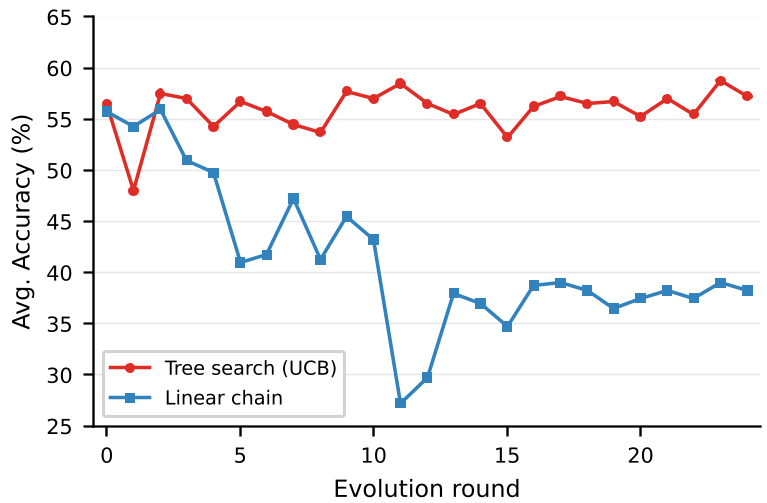 图 2:在 BIRD Card Games 任务中,线性链(橙色)由于一次错误的修改导致准确率直接崩盘,而 LSE 的树搜索(蓝色)能够及时止损并重回性能巅峰。
图 2:在 BIRD Card Games 任务中,线性链(橙色)由于一次错误的修改导致准确率直接崩盘,而 LSE 的树搜索(蓝色)能够及时止损并重回性能巅峰。
关键洞察:
- 训练即技能:自我进化(Self-Evolve)不是一种通用智能的附属品,而是一种通过学习获得的特定技能。
- 跨模型迁移:更有趣的是,LSE 训练出来的 4B 模型生成的指令,可以拿给 Arctic-7B 模型用,让后者的性能提升了 6.7%。这说明模型学会了某种通用的“优化逻辑”。
局限性与展望
尽管 LSE 表现强劲,但目前的挑战在于每一轮进化都需要进行小规模的数据测试(Holdout set),这增加了推理成本。此外,现在的进化主要针对“指令(Instruction)”字段。未来,这种自我进化能力如果扩展到参数空间(Test-time Training)或动态生成的外部知识库,LLM 或将真正具备类似人类的“随干随学”的能力。
总结
LSE 告诉我们:规模(Scale)不是唯一的答案。通过精巧的 RL 目标设计,即使是小参数量的模型,也能在特定的元任务(Meta-tasks)上展现出超越“六边形战士”大模型的专业深度。