VLA-World is a Vision-Language-Action world model for autonomous driving that unifies predictive imagination with reflective reasoning. Built on the Qwen2-VL backbone, it achieves SOTA results on the nuScenes-GR-20K dataset, outperforming existing VLA and world models in both trajectory planning and future-frame generation quality.
TL;DR
VLA-World is a novel autonomous driving framework that bridges the gap between Vision-Language-Action (VLA) models and World Models. By generating a "future frame" of what the world will look like 0.5 seconds ahead and then "thinking" about that image before committing to a long-term plan, the model achieves SOTA performance on the nuScenes benchmark, significantly reducing collision rates and improving trajectory accuracy.
Problem & Motivation: The Gap Between Simulation and Reason
In the current landscape of end-to-end autonomous driving, we see two dominant but isolated paradigms:
- VLA Models: They are great at high-level reasoning (using LLM backbones) but often lack a "sense of the future." They map current pixels to actions without explicitly modeling how other agents (pedestrians, cars) move.
- World Models: These act as internal simulators, imagining video sequences of the future. However, they usually "dream" without "reasoning"—they can't effectively evaluate if the future they just imagined is safe or even physically consistent with a specific driving goal.
The Insight: Human drivers don't just react; they anticipate. If you see a ball roll into the street, you briefly imagine a child following it and then reflect: "If I keep going, I might hit someone." VLA-World formalizes this by turning image generation into a "sketchpad" for reflective thought.
Methodology: The "Generation-to-Think" Pipeline
VLA-World operates in a structured sequence that mimics human cognitive processes:
- Perception: Structured grounding of the current scene (detecting agents, road boundaries).
- Short-term Prediction: Estimating the vehicle's state 0.5s into the future.
- Imagination (The World Model): Generating the next image frame conditioned on that 0.5s prediction.
- Reflective Thinking: The model "looks" at its own generated image to identify risks.
- Refined Action: Finalizing the 3-second trajectory based on the reflection.
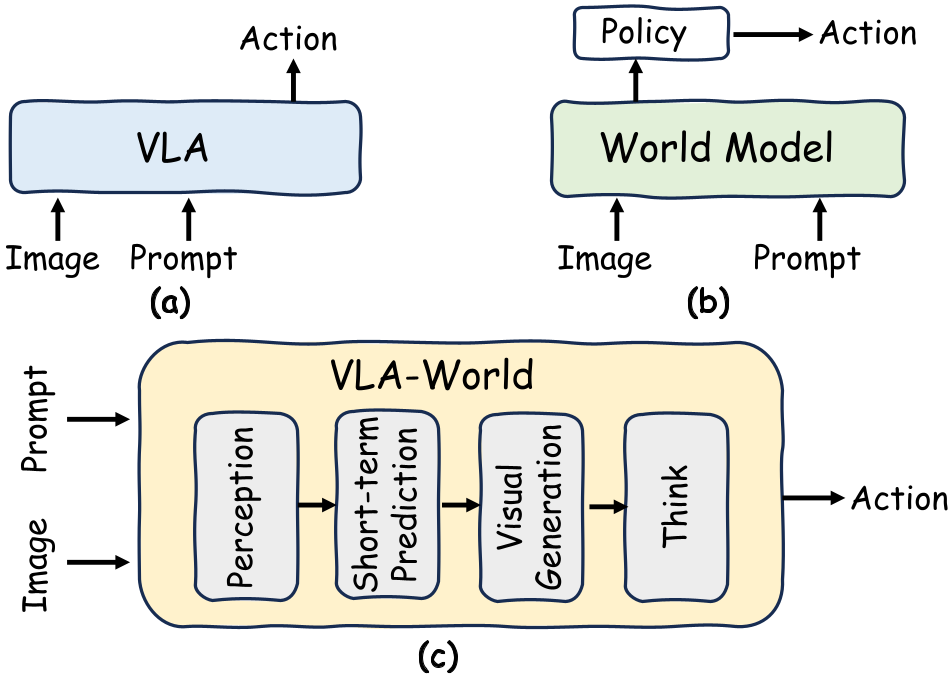
The Three-Stage Training Strategy
To make this work, the authors didn't just fine-tune an LLM; they used a sophisticated pipeline:
- Stage 1: Visual Pretraining: Activating the ability to generate multi-view consistent images via visual tokens (VQGAN).
- Stage 2: Supervised Fine-Tuning (SFT): Teaching the model the "causal chain" of Perceive -> Imagine -> Think -> Act using the new nuScenes-GR-20K dataset.
- Stage 3: RL with GRPO: Using DeepSeek-inspired Group Relative Policy Optimization to reward safe trajectories and correct formatting without the need for a heavy "Critic" model.
Experiments & Results
VLA-World was tested on the industry-standard nuScenes dataset and showed dominance across the board.
Performance vs. SOTA
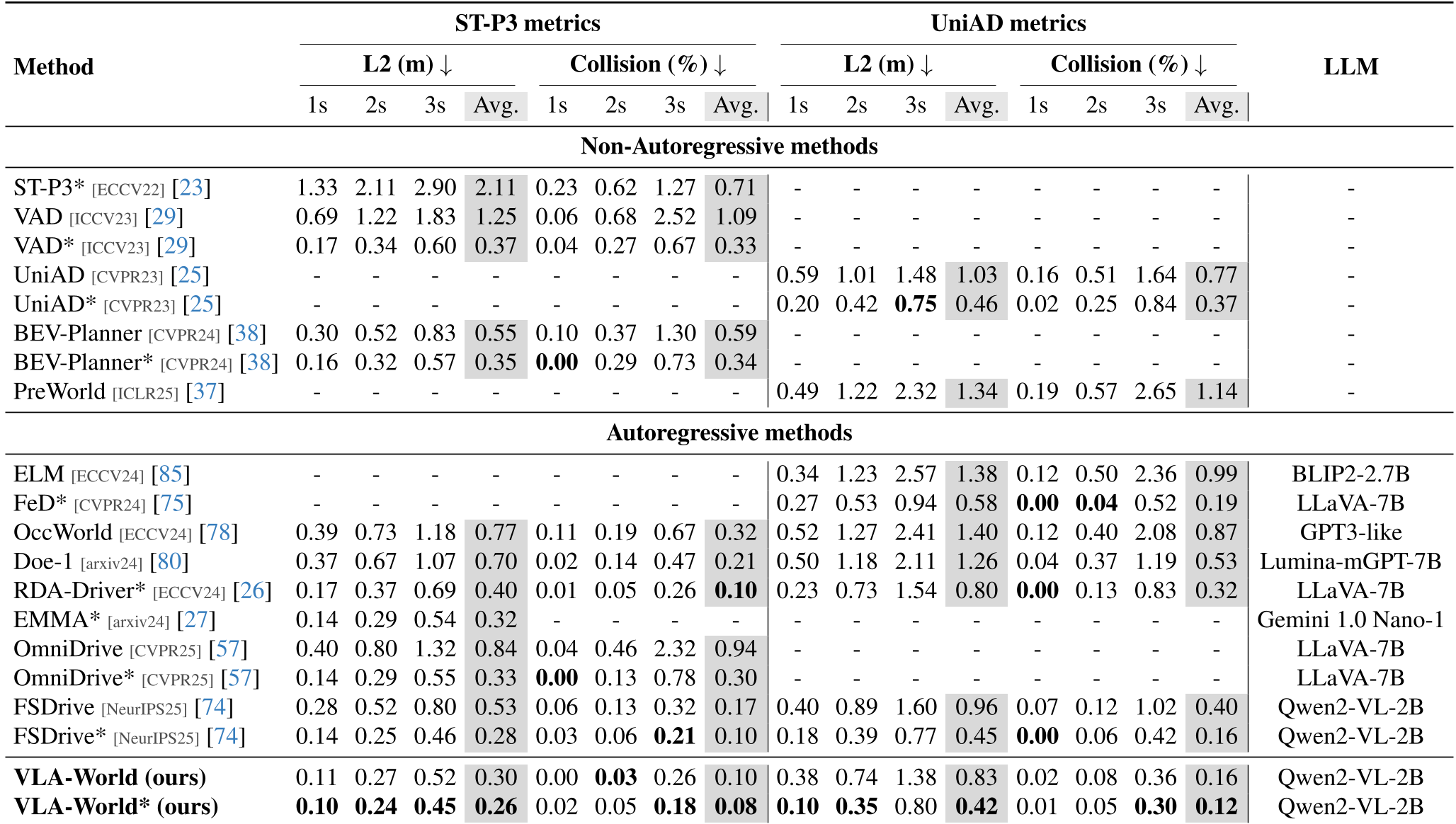
The model outperformed both non-autoregressive (UniAD, VAD) and autoregressive (FSDrive, OmniDrive) baselines. Notably, it achieved an average L2 error of 0.26m (ST-P3 metrics) and a collision rate of just 0.08%, a significant improvement over previous leaders.
Visual Quality
Crucially, the model doesn't just drive better; its "imagination" is more accurate. With an FID score of 9.8, it produces sharper, more physically plausible future frames than even dedicated diffusion-based world models.

Deep Insight & Conclusion
The core contribution of VLA-World is proving that generation is a form of reasoning. By forcing the model to manifest its prediction as an image, we provide the LLM with a much richer "feature set" to reason over than simple vector-based coordinates.
Takeaway: Future autonomous systems will likely move away from black-box "pixels-to-steering" models toward "World-VLA" hybrids that can explain why they are braking by pointing to an imagined risk in their internal simulator.
Limitations: The model is currently heavy (based on Qwen2-VL), leading to latencies that might be challenging for real-time edge deployment without significant quantization or distillation.