本文提出了 TGSR (Timestamp-Grounded Speech Reasoning),这是一种基于强化学习的音频语言模型 (LALM) 框架。该方法通过在推理链中引入显式的时间戳标注(Timestamp Grounding),显著提升了模型在语音推理任务中的忠实度与准确性,在 MMAU 和 AIR-Bench 等多个基准测试中超越了现有 SOTA。
TL;DR
在多模态大模型(LALMs)领域,模型经常出现“听而不闻”的尴尬:虽然能给正确答案,但其推理逻辑(CoT)往往是靠文本常识硬抠出来的。本文提出的 TGSR (Timestamp-Grounded Speech Reasoning) 框架,通过引入显式的时间戳对齐和 GRPO 强化学习,强制模型在推理时必须“点名”音频的具体位置。这不仅大幅提升了任务准确率,更让模型的推理过程变得真正可信。
痛点深挖:音频模型的“注意力陷阱”
即便强如 GPT-4o 或 Gemini,在处理音频推理时也存在一个隐秘的问题:文本偏见 (Text-bias)。作者通过注意力图分析发现,在推理某些必须依赖音频才能回答的问题时(如“这段话是谁说的?”),模型竟然将 15 倍以上的注意力权重分配给了系统提示词(System Tokens),而分配给音频 Token 的比例少得可怜。
这种现象被称为 Attention Sink。结果就是:模型可能猜对答案,但它给出的解释由于不参考音频证据,本质上是一种“幻觉推理”。
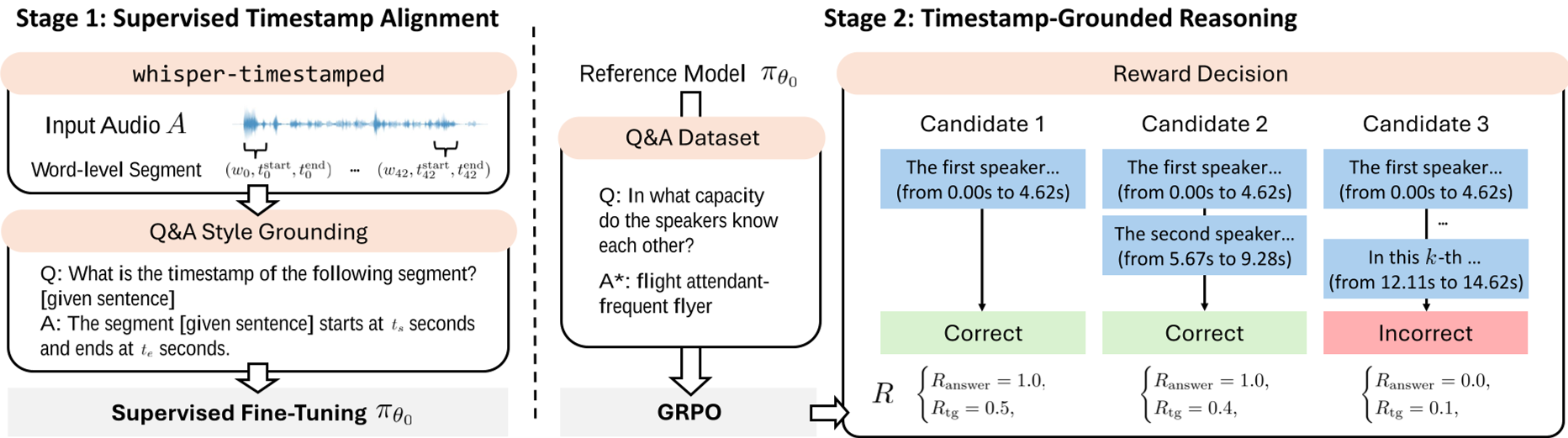
核心方法:两阶段进阶路径
为了解决这一问题,作者设计了一套从“定位”到“逻辑”的训练流:
1. 监督时间戳对齐 (STA)
首先,你得让模型学会“数秒”。利用高精度的 whisper-timestamped 工具,作者构建了一个包含 26.8 万条数据的语音语料库。模型被要求针对特定的语音片段预测其起始时间()和结束时间()。这一步建立了模型对音频时域的直观感知能力。
2. 基于 GRPO 的强化学习 (Stage 2)
模型在有了定位能力后,如何将其融入推理?作者采用了 GRPO (Group Relative Policy Optimization) 机制,并设计了独特的复合奖励函数:
- :回答正确就有分。
- (Timestamp Grounded Reward):奖励那些在推理链中包含了简洁、准确时间戳参考的行为。
这种设计鼓励模型不仅要找到答案,还要在推理步骤中指出:“根据音频 [1.2s - 3.5s] 处的语调,我判断……”
实验与结果:不仅是分数的提升
在 MMAU 和 AIR-Bench 等硬核音频理解基准测试中,基于 Qwen2.5-Omni 的 TGSR 模型表现抢眼,甚至在部分指标上超越了 GPT-4o Audio。
关键战绩:
- 一致性 (Consistency):推理逻辑与最终答案的匹配度提升至 0.83(基线为 0.72)。
- 音频验证 (Audiology Verify):生成的解释内容与对应音频片段的语义匹配度提升了两倍以上。

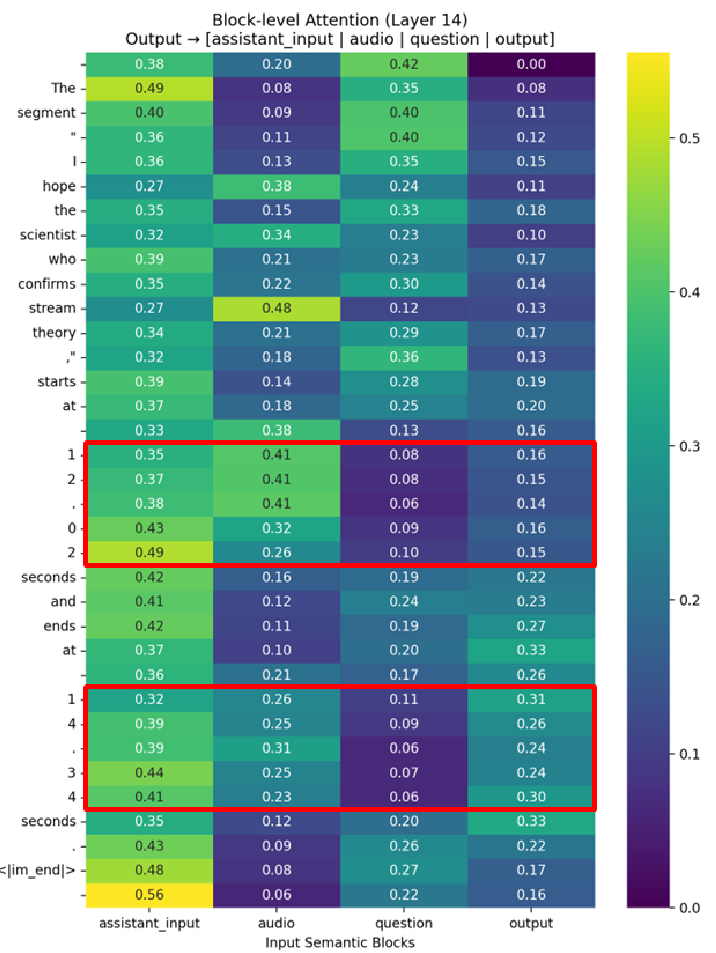
有趣的是,从下图中可以看到,经过训练后的模型在生成时间戳相关的 Token 时,对音频区域的 Attention Map 有明显的“增亮”效应,证明了模型确实在“认真听”那一秒钟发生了什么。
深度洞察与总结
TGSR 的核心价值在于它触及了多模态推理的灵魂:忠实度 (Faithfulness)。
局限性 (Limitations): 目前该方法主要集中在语音(Speech)领域,对于复杂的环境音、多重背景乐等非语义信号的对齐尚处起步阶段。此外,强化学习中的稀疏奖励(Sparse Reward)问题仍有待通过引入更细粒度的中间奖励来解决。
未来展望: 随着模型能力的增强,这种“先定位、再分析、后回答”的范式可能成为音频交互的标准。它不仅让 AI 听得准,更让 AI 的思考过程对人类变得透明。