The paper introduces Reaction Aware Policy Optimization (RAPO), a reinforcement learning framework for Emotional Support Conversation (ESC). It shifts the optimization target from static, expert-defined rubrics to dynamic, dense natural-language feedback derived from simulated user reactions, achieving significant improvements in interaction outcomes across ESC and SOTOPIA benchmarks.
TL;DR
Existing AI for emotional support often feels like a robot reading from a script—it says "I understand," but it doesn't actually help. This is because we train them on static expert rubrics. RAPO (Reaction Aware Policy Optimization) changes the game by training models to optimize for the actual result of a conversation: the user's reaction. By simulating how a user "echoes" back to a response, RAPO combines scalar rewards with verbal critiques to create truly adaptive and empathetic agents.
The Problem: The Trap of "Hallucinated Empathy"
In Emotional Support Conversation (ESC), we've traditionally used Supervised Fine-Tuning (SFT) or RLHF based on expert rubrics. However, these suffer from two fatal flaws:
- Optimization Mismatch: A model can earn a "perfect" score from an expert rubric for saying "I'm sorry you feel that way," while the actual human user feels ignored or bored.
- Signal Sparsity: A single number (e.g., a reward score of 0.2) doesn't tell the model why it failed. Was it too pushy? Too vague? Scalar rewards lack the semantic resolution to guide fine-grained improvement.
Methodology: Learning from the Echo
The authors propose that the most reliable signal isn't a score—it's the User Reaction. If a user responds with "That's exactly it!" the agent succeeded. If they say "You're not listening," it failed.
1. The Interaction Loop
RAPO doesn't just score a response; it uses a User Simulator to generate a hypothetical "echo" for every candidate response. This transforms a static turn into a dynamic mini-trajectory.
2. Generative Hindsight Feedback
Instead of a standard reward model, RAPO uses a Generative Reward Model (GRM). The GRM looks at a group of responses and their simulated reactions to produce:
- Relative Ranks: A stable scalar signal.
- Verbal Critiques: Natural language explanations of why one response worked better than another (e.g., "The user felt invalidated because you gave advice too early").
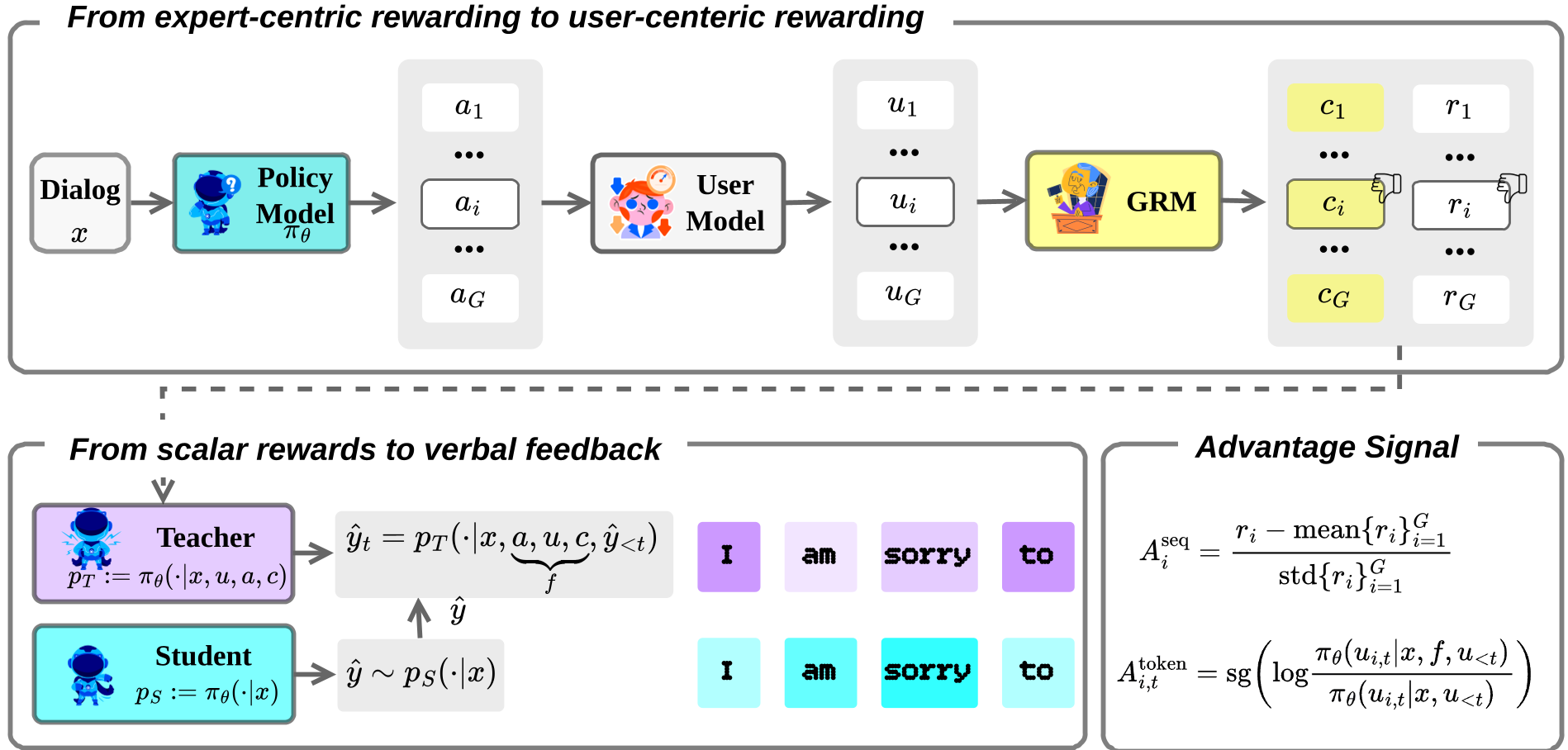 Fig 1: The RAPO pipeline—from User Simulation to Hybrid Policy Optimization.
Fig 1: The RAPO pipeline—from User Simulation to Hybrid Policy Optimization.
3. Scalar-Verbal Hybrid Policy Optimization
This is the mathematical core of the paper. RAPO optimizes a dual objective:
- Macro-level (GRPO): Aligns the policy with global ranking rewards.
- Micro-level (Self-Distillation): The model acts as its own "feedback-aware teacher." It takes a failed response + a critique, generates a corrected version, and then distills that knowledge back into the base policy.
Experiments: Does it Actually Work?
The authors tested RAPO on ESConv (standard benchmark), EmoHarbor (personalized support), and SOTOPIA (complex social negotiation).
Key Result: Superior Interaction Outcomes
On EmoHarbor, RAPO consistently outperformed vanilla RL methods. While standard SFT models often "collapsed" into repetitive templates, RAPO-tuned models maintained high semantic variety and goal-oriented support.
 Table 1: Performance across benchmarks showing RAPO's dominance over SFT and standard GRPO.
Table 1: Performance across benchmarks showing RAPO's dominance over SFT and standard GRPO.
Generalizability in SOTOPIA
In SOTOPIA, a benchmark for social "games" like negotiation, RAPO achieved a Goal Completion score of 8.41, even outperforming GPT-4o in difficult scenarios. This proves that "listening to the reaction" is a universal principle for social intelligence, not just empathy.
Critical Analysis & Takeaways
Why RAPO succeeds: It resolves "reward ambiguity." By using the user's reaction as a bridge, the model learns the causal link between its words and the user's emotions.
Limitations:
- Computation: Simulating multiple user reactions for every training step is expensive.
- Simulator Bias: The model is only as good as the User Simulator. If the simulator doesn't reflect real human diversity, the policy might overfit to "simulated" personalities.
The Future of ESC: RAPO marks a shift from "expert-centric" AI to "user-centric" AI. Future agents won't be judged by how well they follow a psychological textbook, but by how effectively they navigate the unique, shifting internal worlds of the humans they serve.
Senior Editor's Note: This work elegantly bridges the gap between traditional RL and natural language feedback. The use of self-distillation to internalize critiques is a robust way to bypass the "sparse reward" bottleneck that has long plagued conversational AI.