本文提出了 RAPO (Reaction Aware Policy Optimization) 框架,旨在解决情感支持对话 (ESC) 中标量奖励稀疏和逻辑断层的问题。该方法通过模拟用户反应生成高密度的自然语言反馈,并结合标量与口头(Verbal)混合强化学习,在 ESC 和 SOTOPIA 社交智能基准上均达到了 SOTA 性能。
TL;DR
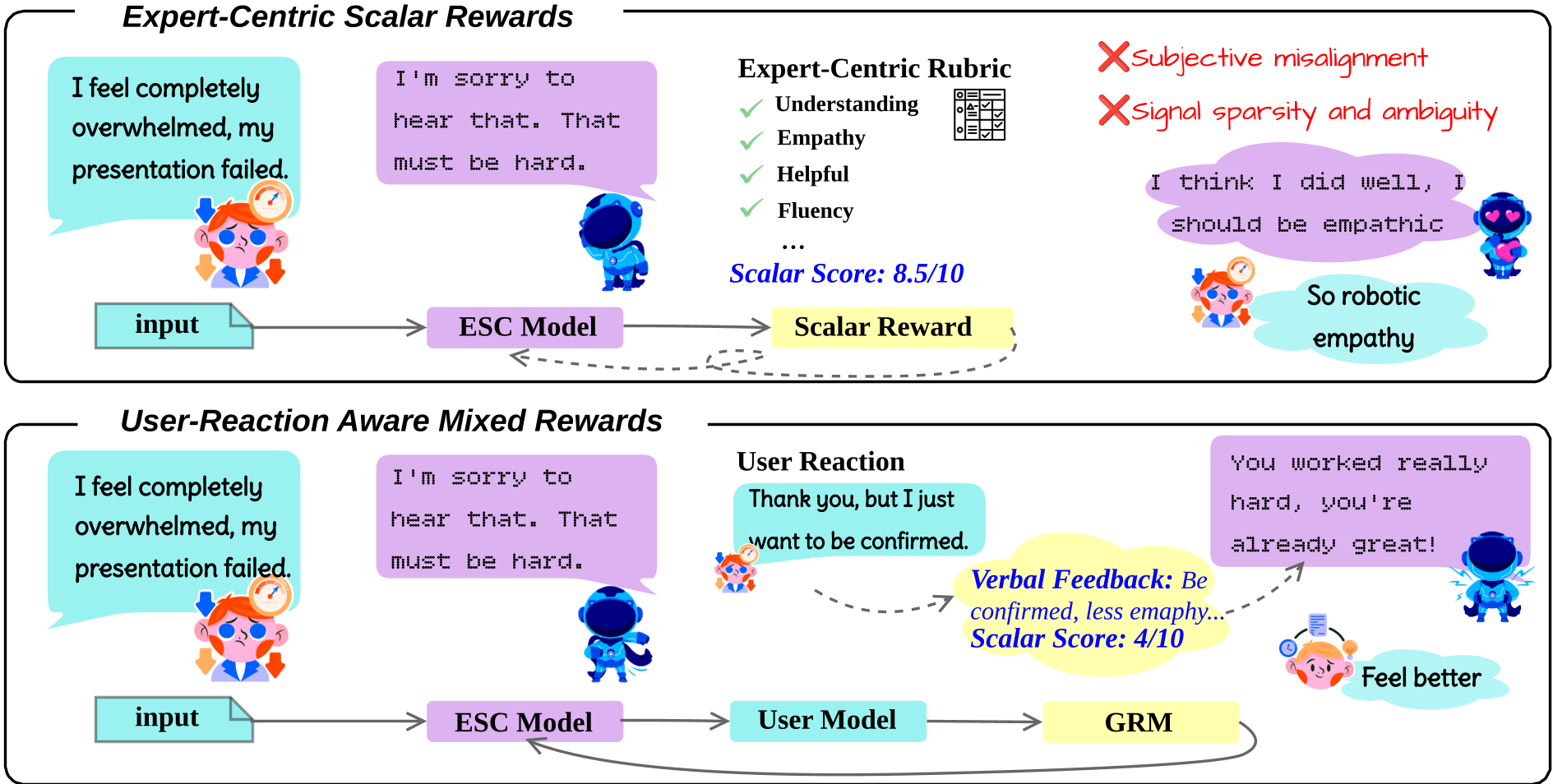
传统的情感支持 AI 往往在“刷分”——它们通过堆砌“我理解你的感受”这类万能模版来获取高专家评分,却无法真正缓解用户的焦虑。本文提出的 RAPO (Reaction Aware Policy Optimization) 框架实现了一个关键范式转移:放弃死板的专家评分表,转而让模型“倾听”用户的持续反应。 通过模拟用户在听到回复后的情绪回响,并将其转化为“标量+文本”的混合反馈,RAPO 让 AI 能够像真人一样在互动中学会真正的共情。
1. 痛点深挖:为何共情无法被“标量化”?
在情感支持对话 (ESC) 领域,模型训练长期面临两大顽疾:
- 评价失真 (Optimization Mismatch):专家定义的评分标准(如共情度、技巧性)是静态的。模型学会了生成听起来温和但毫无意义的废话(幻觉共情),因为这些废话在指标上是完美的,但由于没有动态观察用户反应,它们在实际交互中非常“假”。
- 信号稀疏 (Signal Sparsity):给一个回复打 0.6 分并不能告诉模型为什么不好。是因为建议给得太早?还是因为语气太冷淡?仅靠标量奖励,模型无法进行细粒度的语义修正。
2. 核心机制:RAPO 的三重奏
RAPO 框架通过以下三个阶段将对话建模为一个“反应驱动”的过程:
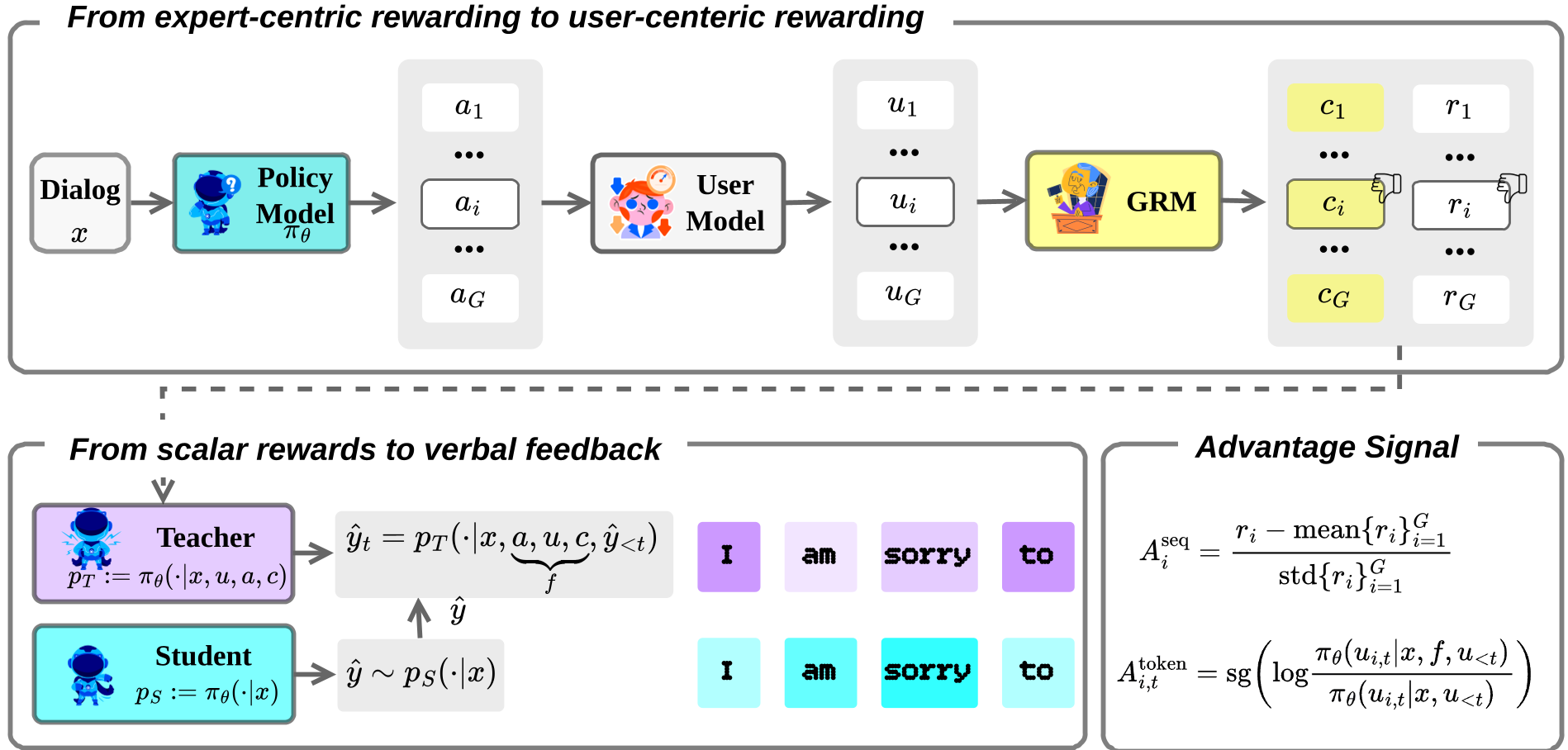
2.1 后验对话选择 (Hindsight Dialogue Selection)
并非对话中的每一句话都值得深度强化学习。很多轮次只是简单的寒暄。RAPO 使用 GPT-4o 作为“裁判”,回溯整段对话,识别出那些真正导致用户情感轨迹发生转折的关键轮次(Pivotal Turns),并针对性地进行策略优化,避免模型在低信息量的模版上过拟合。
2.2 生成式后验反馈 (Generative Hindsight Feedback)
这是 RAPO 的灵魂。
- 用户模拟器:针对一个 Prompt,模型生成一组候选回复。对于每个回复,模拟器会给出一个“回声”——即用户听到这话后的反应。
- 对比式 Critique:生成式奖励模型 (GRM) 同时观察这一组“回复-反应”对,不仅给出排名分,还写出一段自然语言批判,解释为什么回复 A 比回复 B 更能安抚用户。
2.3 标量-口头混合策略优化 (Hybrid Optimization)
这是本文数学上的精妙之处。它在梯度层面融合了两种力量:
- 宏观对齐 (GRPO):利用排名标量奖励进行全局策略对齐。
- 微观矫正 (Verbal RL):利用在策略自我蒸馏 (On-policy Self-distillation),让模型强行学习那些带有 Critique 的“教师分布”。
3. 实验战绩:不只是情感,更是社交智慧
RAPO 在多个严苛的基准测试中展现了压制性的实力:
- 情感支持能力:在 EmoHarbor 测试中,Qwen-2.5-RAPO 的整体表现比传统的 GRPO 提升了 12.4%。
- 社交通用性:在 SOTOPIA(多智能体社交智能基准)中,尽管任务跨越了谈判、竞争和协作,RAPO 的目标完成得分 (8.41) 依然显著优于 GPT-4o 以及基于 PPO 的基线。
- 人类偏好:在人类评估中,RAPO 相比 CPO 等强基线保持了绝对的胜率,证明了其生成的回复更符合人类的真实情感感知。

4. 深度洞察:自我蒸馏的“校准”作用
消融实验(Ablation Study)揭示了一个有趣的现象:
- 如果不加 URM(用户反应建模):模型会陷入“自嗨”,评分虽高但解决不了用户的实际压力。
- 如果不加 SD(自我蒸馏):模型的“建议分”会陡增。这意味着模型在发现效果不好时,会倾向于“粗暴地给建议”而不是“耐心地倾听”。只有加入文本反馈的蒸馏,模型才能学会**“不要过早给建议”**这种细微的社交平衡。
5. 总结与展望
RAPO 的成功标志着 LLM Alignment 正从“对齐静态准则”向“对齐动态后果”演进。通过将模拟的用户反应引入训练循环,我们赋予了 AI 一种**“交互式直觉”**。
局限性分析:尽管性能强劲,RAPO 的训练成本较高(需要频繁调用模拟器),且极其依赖于用户模拟器的质量。未来的研究方向在于如何将这种昂贵的“反应反馈”蒸馏到更小、更高效的奖励模型中。
Takeaway: 真正的共情不在于你说了多么优美的安慰话,而在于你是否根据对方的反应即时调整了你的灵魂。RAPO 让 AI 迈出了学会“倾听”的第一步。