本文提出了 LiteGUI,这是一种专为端侧设备设计的轻量级视觉语言 GUI Agent 训练框架。该方法通过 Guided On-policy Distillation (Guided-OPD) 和 Multi-solution Dual-level GRPO 强化学习算法,显著提升了 2B-3B 规模模型在复杂 GUI 任务中的成功率,并在多个基准测试中达到了 SOTA 水平。
TL;DR
在自动驾驶 PC 的 GUI Agent 领域,大模型虽强但推理成本极高,而小模型又常因 SFT(监督微调) 导致的策略僵化而“心余力不足”。本文介绍的 LiteGUI 另辟蹊径,抛弃 SFT,采用 引导式在线蒸馏 (Guided-OPD) 和 多解双层强化学习 (MD-GRPO),让 2B 规模的小模型在 OS-World 等严苛榜单上性能翻倍,甚至越级挑战 72B 巨型模型。
核心痛点:为什么 SFT 救不了小模型?
传统的 GUI Agent 训练高度依赖专家轨迹的 SFT。然而,对于 2B-3B 参数的轻量级模型,SFT 存在三大致命伤:
- 策略僵化 (Policy Rigidity):小模型会死记硬背像素坐标,一旦环境发生细微变化(如下载弹窗位置不对),模型就会陷入死循环。
- 灾难性遗忘:过度微调 GUI 任务常导致模型丧失基础的视觉理解能力。
- 多解性冲突:打开一个文件可以是“双击”,也可以是“右键->打开”。SFT 强行要求模型模仿某一个特定动作,会产生严重的认知偏差。
技术突破:双管齐下的“进化”路径
1. 引导式在线蒸馏 (Guided On-policy Distillation)
作者认为,老师(大模型)不应该只给学生(小模型)答案,而应该在学生自己尝试时给出反馈。为了解决老师容易产生的“幻觉”问题,LiteGUI 引入了 特权指令 (Privileged Guidance)。
- 动态检索匹配:系统会实时观察学生的探索意图,从预先构建的多解路径库中选择最匹配的一条作为老师的参考,确保师生步调一致,降低优化难度。
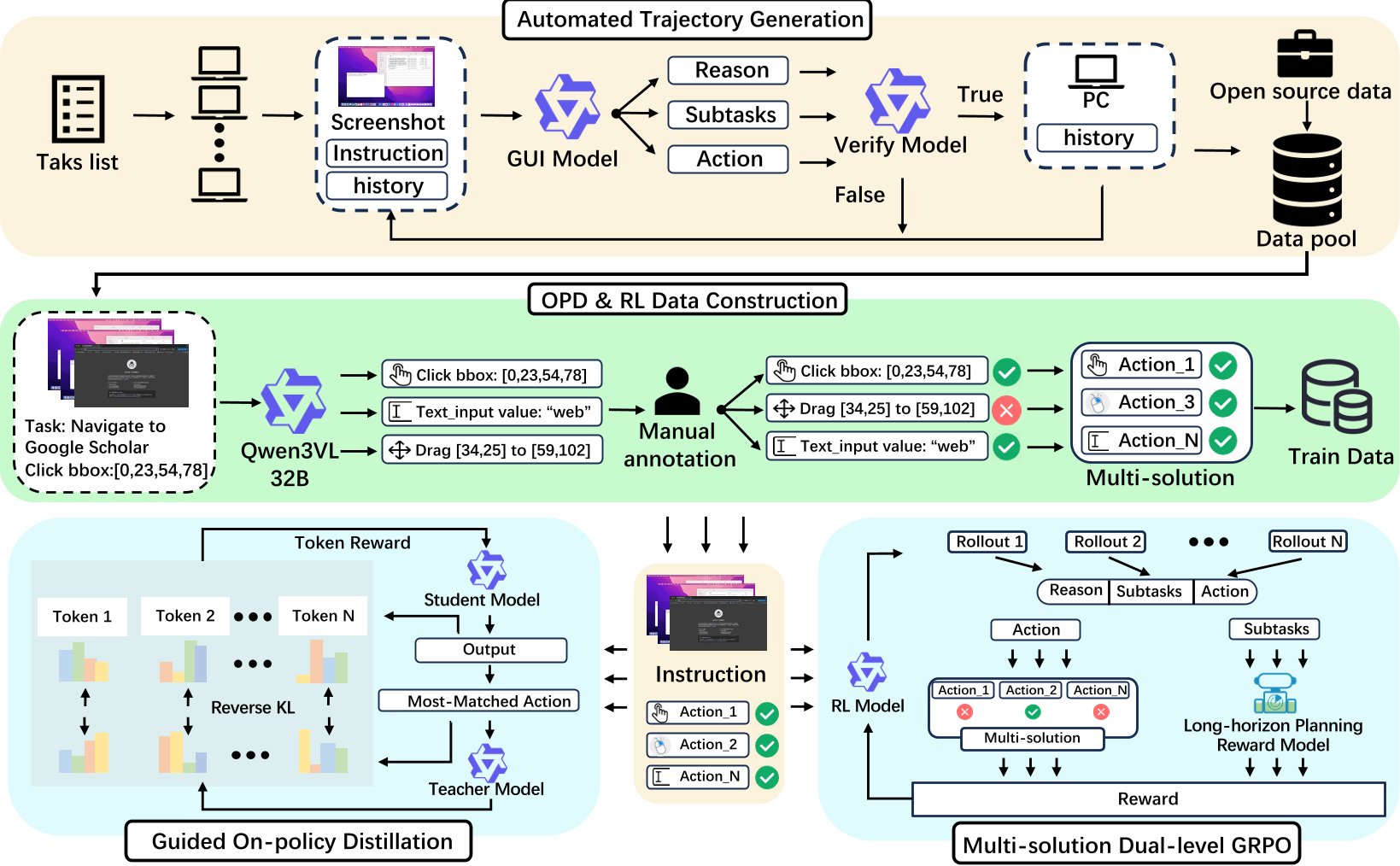
2. 多解双层 GRPO (MD-GRPO)
在强化学习阶段,LiteGUI 改进了 DeepSeek 提出的 GRPO 算法,针对 GUI 任务定制了双层奖励机制:
- 微调层(动作匹配):不再死磕单一坐标,只要动作类型正确且点击在有效的候选点集内,均给予正向奖励。
- 宏观层(子任务规划):利用强语义模型(如 Qwen3-32B)作为裁判,评估模型的“思考链”是否合理,是否理解了当前进度,是否在遇到报错时有重试逻辑。
实验战绩:小钢炮的逆袭
在涵盖文件系统、网页和终端的 Lite-Bench 测试中,LiteGUI 表现惊人:
- 性能翻倍:LiteGUI-2B 在 OS-World 上的成功率从基座模型的 6% 提升至 13.24%。
- 越级挑战:LiteGUI-30B-A3B 在多项指标上击败了参数量大数倍的 UI-TARS-72B。
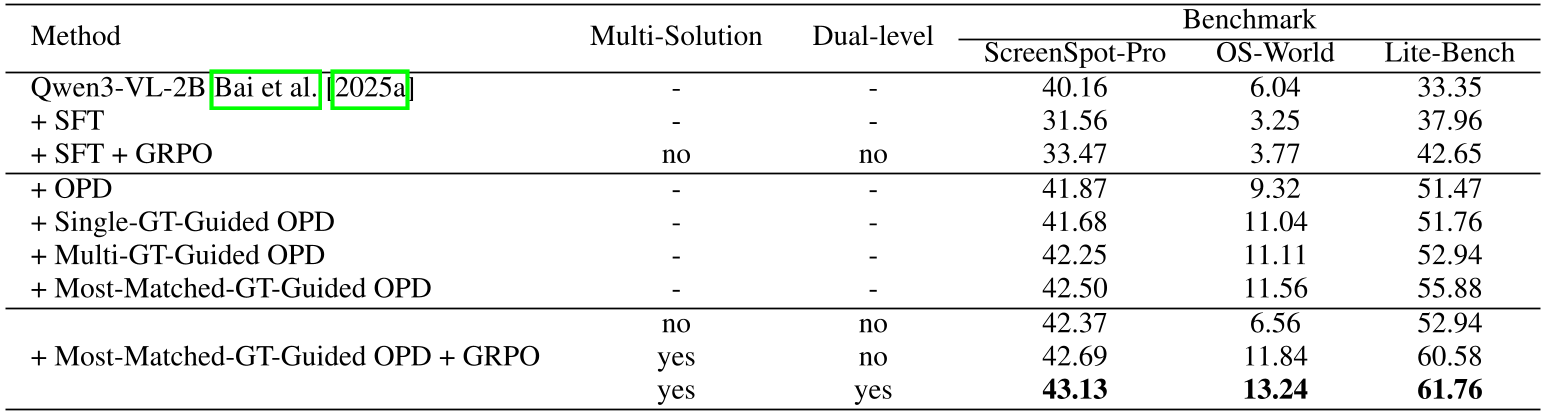
消融实验显示,即便没有 SFT,仅凭 Guided-OPD + GRPO 也能实现跨越式增长,这证明了“无 SFT 范式”在代理任务中的巨大潜力。
深度洞察
LiteGUI 的成功在于它深刻理解了 GUI 交互的本质——鲁棒性比精确模仿更重要。通过引入“多解性”的宽容度,模型在强化学习中得到了更密集的奖励信号。对于开发者而言,这意味着未来我们无需昂贵的算力芯片,仅凭手机端侧的 NPU 就能跑起一个如丝般顺滑的自动化助理。
总结与展望
LiteGUI 不仅提供了一套高效的训练范式,还开源了 Lite-Dataset (30K 轨迹) 和 Lite-Bench,填补了 GUI 领域高质量多解标注数据的空白。未来的研究重点将转向如何进一步减少长历史窗口带来的内存开销,并实现在线增量学习。
本文由资深学术技术主编重构。原论文:LiteGUI: Distilling Compact GUI Agents with Reinforcement Learning (2026).