本文推出了 LLaDA2.0-Uni,一个统一的离散扩散大语言模型(dLLM),实现了多模态理解与生成的原生集成。该模型基于 16B MoE 架构,通过 SigLIP-VQ 标记器统一了视觉表示,在保持与顶级 VLM 相当的理解能力同时,实现了卓越的图像生成与编辑效果。
TL;DR
LLaDA2.0-Uni 是由 Inclusion AI 团队推出的新一代 16B MoE 离散扩散大模型。它通过创新性的 SigLIP-VQ 标记器,将图像转化为语义离散 Token,首次在单一 diffusion LLM 框架下实现了“理解”与“生成”的完美统一。在 Benchmark 上,它不仅在图文理解上硬刚 Qwen2.5-VL,在图像生成的细腻度与编辑灵活性上也达到了 SOTA 水平。
痛点深挖:理解与生成的“异形”之痛
长期以来,AI 领域存在一个隐形的屏障:理解模型(VLM)看图像,生成模型(Diffusion)画图像,但它们“语言”不通。
- AR 架构的局限:自回归模型(如 Janus)虽然能统一格式,但在处理图像这种高维度数据时,计算量巨大且缺乏全局上下文建模的效率。
- VQ 的语义缺失:传统的统一扩散模型(如 MMaDA)使用的 VQ-VAE 标记器偏向像素重建。对模型来说,这些标记就像是零散的色块,没有语义,“看得见”却“读不懂”。
- 训练目标的冲突:AR 损失与扩散损失往往难以平衡,导致模型非此即彼。
核心机制:语义标记器与块级扩散
LLaDA2.0-Uni 的核心逻辑是:既然文字是离散的语义单元,为什么不把图像也变成同样的语义单元?
1. SigLIP-VQ:让图像 Token 具备“灵魂”
作者弃用了传统的重建式 VQ,转而采用基于 SigLIP2 的语义标记器。这意味着模型提取的每个视觉 Token 本身就具备极强的分类和描述能力,直接对齐了 LLM 的语义空间。
2. MoE Backbone 与块级注意力
模型采用了 16B 的 MoE 架构。为了克服完全双向注意力(Full Bidirectional Attention)在处理长文本时的不稳定性,引入了 Block-wise Attention(块级注意力),在保证并行解码效率的同时,维持了自回归式的推理稳定性。
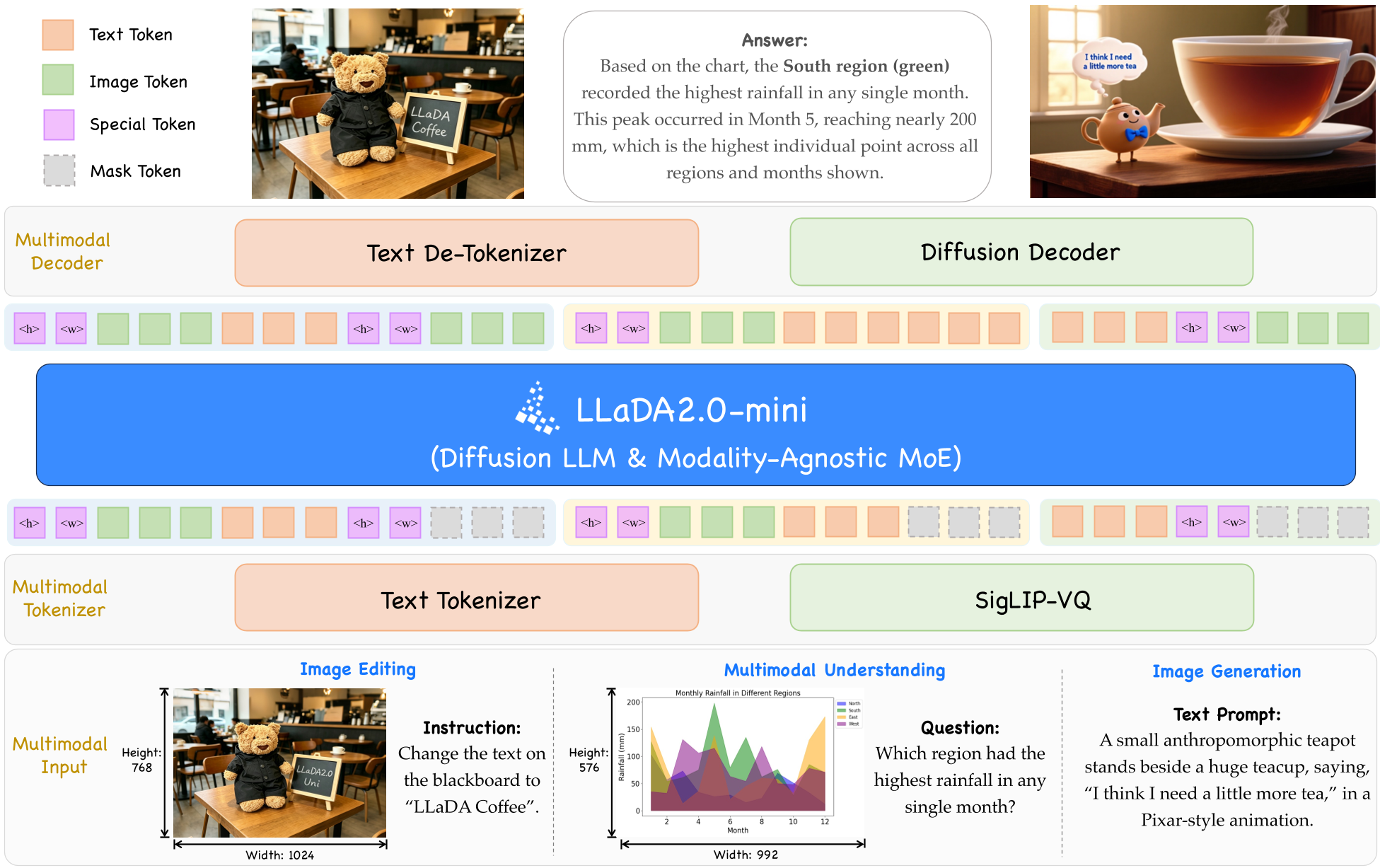 图 1:LLaDA2.0-Uni 的整体架构,集成了语义标记器、dLLM 主干和扩散解码器。
图 1:LLaDA2.0-Uni 的整体架构,集成了语义标记器、dLLM 主干和扩散解码器。
实验与战绩:全能选手的爆发
在多模态理解(Multimodal Understanding)测试中,LLaDA2.0-Uni 证明了自己不再是一个“偏科”的生成模型。
- 理解力:在 MMStar 榜单上拿下 64.1 分,超越了许多专门为理解设计的 VLM。
- 生成力:在 DPG-Bench 上甚至超过了专注生成的 Z-Image-Turbo,展示了极强的指令遵循能力。
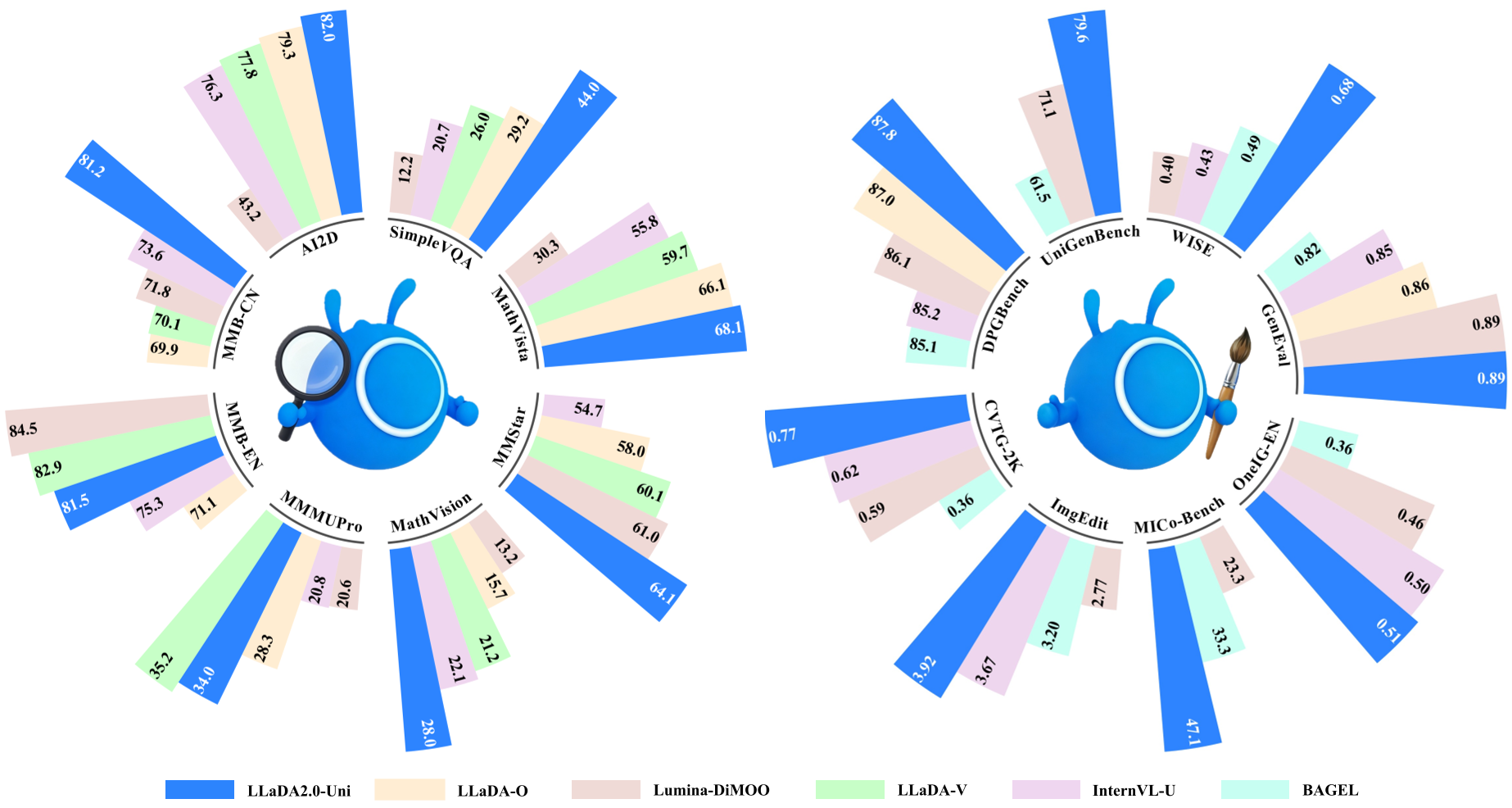 图 2:LLaDA2.0-Uni 在各项 Benchmark 上的综合表现,不仅在理解上处于第一梯队,在生成上亦然。
图 2:LLaDA2.0-Uni 在各项 Benchmark 上的综合表现,不仅在理解上处于第一梯队,在生成上亦然。
推理加速:SPRINT 框架
扩散模型通常推理缓慢。本文提出了 SPRINT 加速技术:
- 稀疏前缀保留(Sparse Prefix Retention):动态剪掉对当前生成不重要的 KV Cache。
- 非均匀 Token 去掩码(Non-uniform Unmasking):根据预测信心动态调整采样步骤,自信的 Token 走“快车道”,不确定的走“精修路”。
深度洞察:交织推理的未来
LLaDA2.0-Uni 最惊艳的能力在于其天然支持交织推理(Interleaved Reasoning)。 例如,在处理复杂的物理问题时,它可以先输出一段文字分析,然后生成一张用于辅助说明的物理示意图,再接着写推导过程。这种“边想边画”的能力是 AGI 场景(如多模态科研助手、高级 UI Agent)最需要的特质。
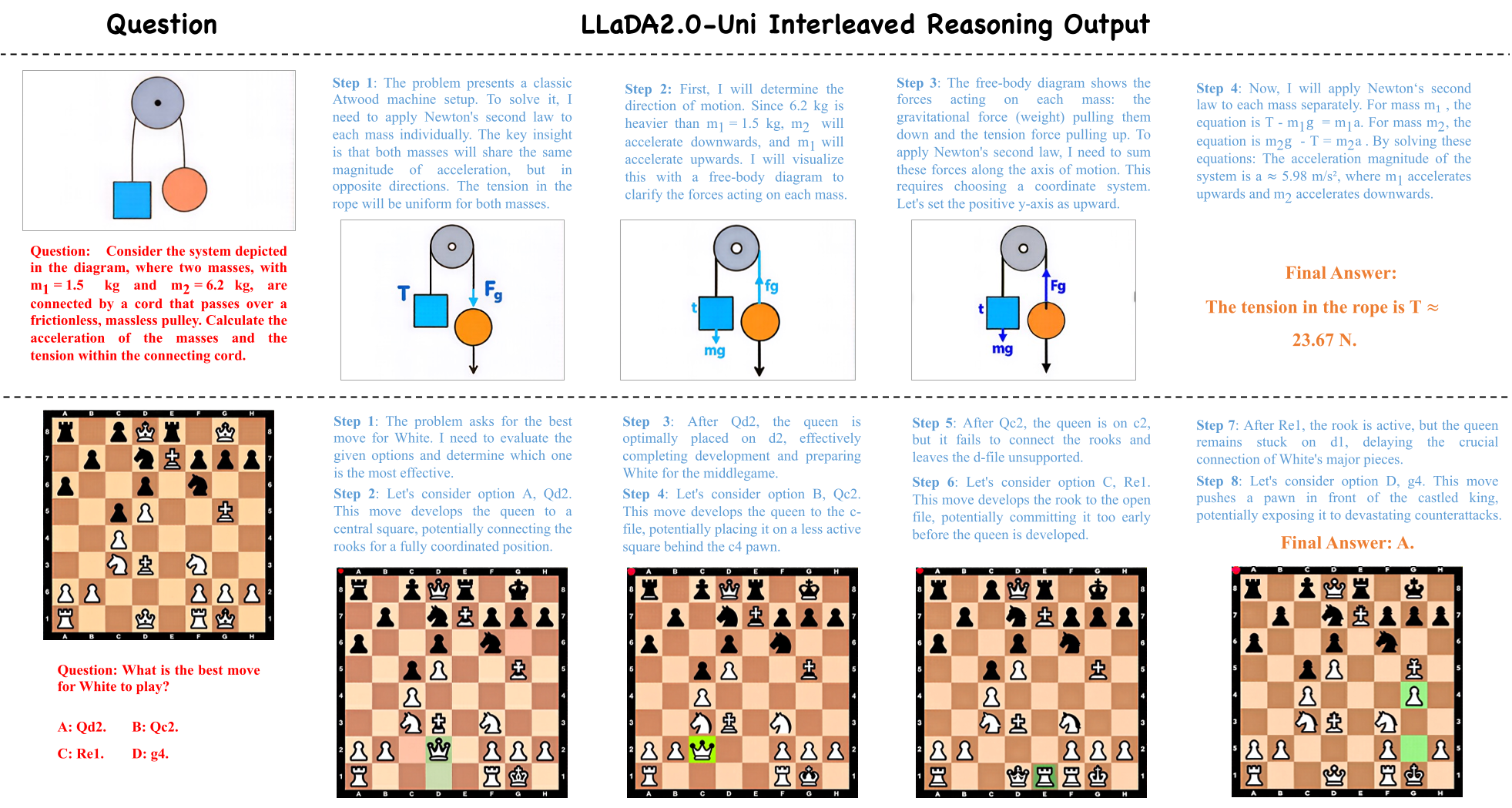 图 3:模型在下象棋和解物理题时的交织推理展示。
图 3:模型在下象棋和解物理题时的交织推理展示。
总结与局限
Takeaway: LLaDA2.0-Uni 成功地验证了离散扩散模型在多模态统一路径上的巨大潜力。它告别了 VLM 作为生成模型“附件”的尴尬地位。
局限性:虽然语义标记器提升了理解能力,但由于其高度压缩,在极具细节的图像还原(如极小文字、超精细纹理)上仍有提升空间。此外,MoE 的负载均衡在超长上下文下仍是一个待持续优化的方向。
未来的研究方向将集中在通过强化学习(RL)进一步优化模型的生成与逻辑一致性,这值得所有 AI 从业者持续关注。