本文提出了 LLM Router,一种基于模型内部 Prefill 激活信号的 LLM 路由方法。通过核心架构 SharedTrunkNet 和“编码器-目标解耦” (Encoder-Target Decoupling) 技术,该方法能利用小型开源模型的内部状态预测闭源大模型的表现,在保持高准确率的同时大幅降低推理成本。
TL;DR
大语言模型(LLM)的世界里没有全才。即使是 GPT-5 或 Claude 4 也有其短板。NVIDIA 团队最新的研究表明,路由(Routing)——即根据任务难度选择最合适的模型——其成功的秘密不在于你“问了什么”(语义),而在于模型“思考”时的内在几何特征。本文提出的 LLM Router 通过轻量级模型的 Prefill 激活信号,捕获了 SOTA 模型间 45.58% 的性能差距,并削减了 74% 的推理成本。
1. 痛点:为什么语义路由(Semantic Routing)还不够好?
传统的 LLM 路由器(如基于向量搜索 KNN 的方法)主要分析查询的语义 Embedding。这种方式假设“相似的问题应该由同一个模型回答”。
然而,研究人员发现:
- 语义-复杂度鸿沟:一个看起来简单的数学题和一个复杂的文学评论在语义空间可能很近,但对不同规模模型的挑战程度完全不同。
- 黑盒限制:语义特征无法反映模型生成过程中的内在限制和信心。
2. 核心创新:编码器-目标解耦 (Encoder-Target Decoupling)
作者提出了一个反直觉的发现:“外国”开源模型的隐藏状态训练出的探测器,甚至能比闭源模型自身的信号更准确地预测后者的表现。
通过将提供信号的 Encoder(如 Qwen-35B)与最终执行任务的 Target(如 Claude 4.6)解耦,我们可以用极小的本地计算开销,预判那些昂贵 API 的调用价值。
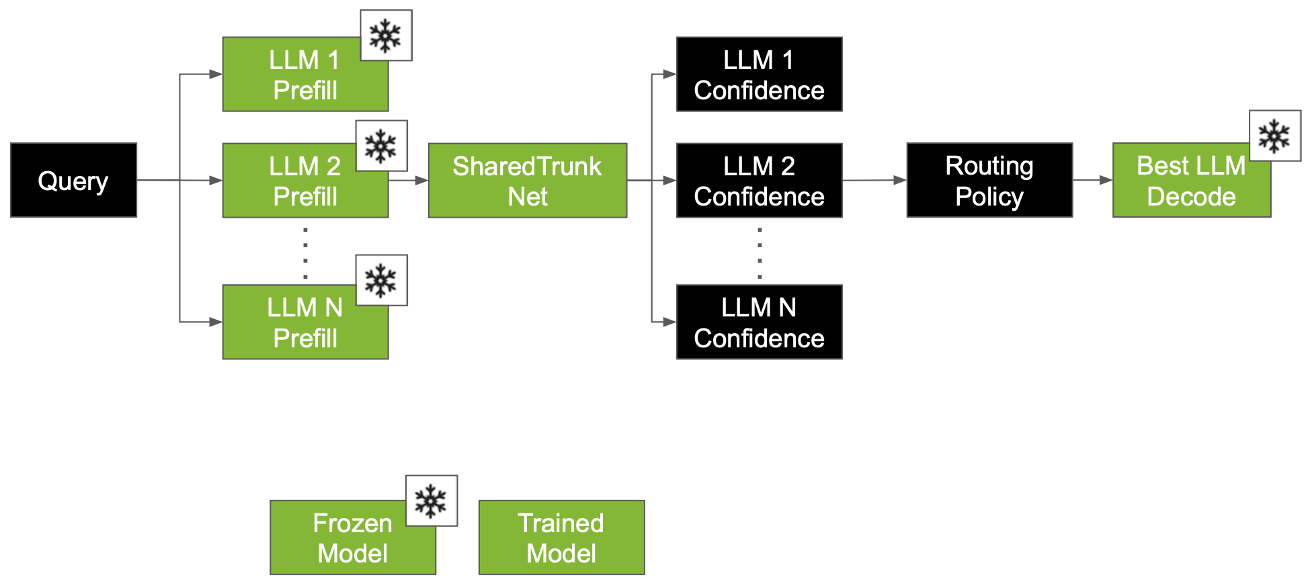
3. 机械化探测:Fisher 分离度与有效维度
如何在这众多的 Transformer 层中找到最具“预见性”的一层?作者引入了两个数学指标:
- 有效维度 (deff):衡量信息的分布广度,防止 PCA 降维造成信息丢失。
- Fisher 分离度 (J):衡量正确与错误两种状态在特征空间中的线性可分性。
实验发现,只要通过 Fisher J 指标选对层,简单的逻辑回归(LR)或 MLP 就能获得极高的预测精度。
4. SharedTrunkNet:多模型协同预测
不同于传统的单对单预测,SharedTrunkNet 采用共享骨干网络(Shared Trunk)同时输出对多个 Target 模型正确率的估计。这种设计带来了 Cross-model context,让路由器能够对比不同模型的相对难度,从而做出更精准的博弈选择。
5. 实验战绩:准确率与成本的巅峰平衡
在包含 GPT-5 和 Claude 4.6 的 Frontier 模型池中,LLM Router 表现惊人:
- 精度增益:将最强 standalone 模型的性能向上推进了 10.9 个百分点。
- 成本节省:在混合模型池中,它可以智能地将简单任务分流给小模型,实现 74.31% 的成本削减。
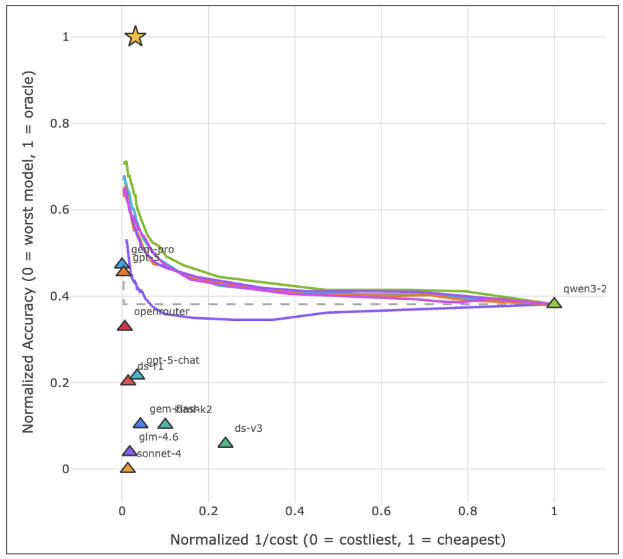
从上图可见,SharedTrunkNet(红色实线)在所有成本区间内都稳定压制了传统的语义路由基线(Semantic Backbones)和静态模型选择(Model-only Pareto)。
6. 深度洞察与总结
LLM Router 的成功标志着路由技术从“黑盒意图识别”转向了“原生的机械预测”。
关键结论:
- Prefill is All You Need:在生成第一个 Token 之前的预填充阶段,模型激活空间的几何特征已经预示了任务的成败。
- 开源赋能闭源:通过 Encoder-Target Decoupling,开发者可以用低成本的开源模型作为“守门人”,精准管理高价值的闭源模型配额。
局限性:目前的成本预估模型还稍显简单(主要基于中位数 Token 数),未来如果能将输出长度(Output Token Count)也纳入预测,路由的帕累托前沿(Pareto Frontier)将进一步向 Oracle 靠近。