This study investigates Reinforcement Learning with Verifiable Rewards (RLVR) under weak supervision, proposing a systematic framework to evaluate performance across scarce data, noisy rewards, and self-supervised proxy rewards. Using the GRPO algorithm, the researchers demonstrate that pre-RL properties like reasoning faithfulness are the primary determinants of whether LLMs like Qwen and Llama can generalize or merely memorize under limited guidance.
TL;DR
Reinforcement Learning with Verifiable Rewards (RLVR) is often hailed as a "magic bullet" for LLM reasoning. However, this paper reveals a sobering reality: RLVR’s success under weak supervision (few samples, noisy labels) is entirely dependent on pre-RL reasoning faithfulness. If your model doesn't "mean what it says" before RL starts, more training will only lead to rapid reward saturation, memorization, and eventual performance collapse.
The Core Conflict: Quick Wins vs. Real Learning
In the current LLM landscape, we often see models like Qwen-Math performing exceptionally well with very little data, while other models like Llama require massive, clean datasets. The researchers found that this isn't just about the number of parameters—it's about Saturation Dynamics.
- Generalizing Models: Experience a prolonged "pre-saturation" phase. Here, training rewards and test performance climb together.
- Memorizing Models: Hit 100% training reward almost instantly but show zero improvement (or even regression) on held-out tasks.
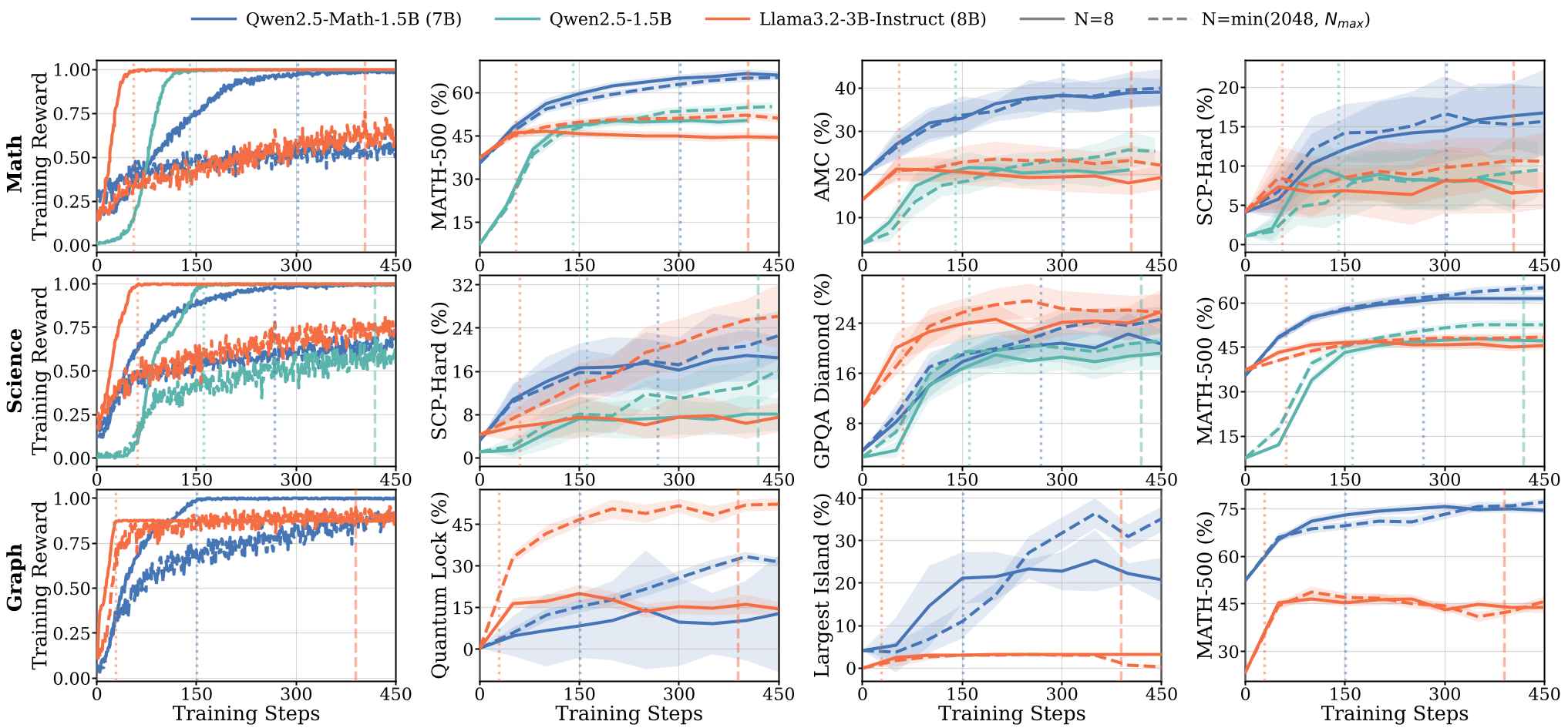 Figure 1: Notice how Qwen (solid lines) sustains growth across steps, whereas Llama (shorter curves) saturates almost immediately.
Figure 1: Notice how Qwen (solid lines) sustains growth across steps, whereas Llama (shorter curves) saturates almost immediately.
The "Faithfulness" Breakthrough
Why do some models saturate so quickly? The study debunks the common myth that "diversity is all you need." Interestingly, Llama models actually produced more diverse answers than Qwen, yet they failed to generalize.
The real differentiator is Reasoning Faithfulness: Does the "Chain of Thought" actually lead to the answer, or is the model just "hallucinating" a path to a lucky guess?
- High Faithfulness: Logical steps support the answer RL reinforces reasoning patterns.
- Low Faithfulness: Reasoning is gibberish, but the answer is correct RL reinforces the specific prompt-answer pair (memorization).
Intervention: How to Fix a Failing Model
The authors didn't just diagnose the problem; they provided a cure. For the Llama-3.2-3B model—which initially failed across the board—they applied a two-stage intervention:
- Continual Pre-training (CPT): Feeding the model 52B tokens of domain-specific (Math) data to build a strong prior.
- Thinking SFT: Crucially, tuning the model on explicit reasoning traces rather than just (Question, Answer) pairs.
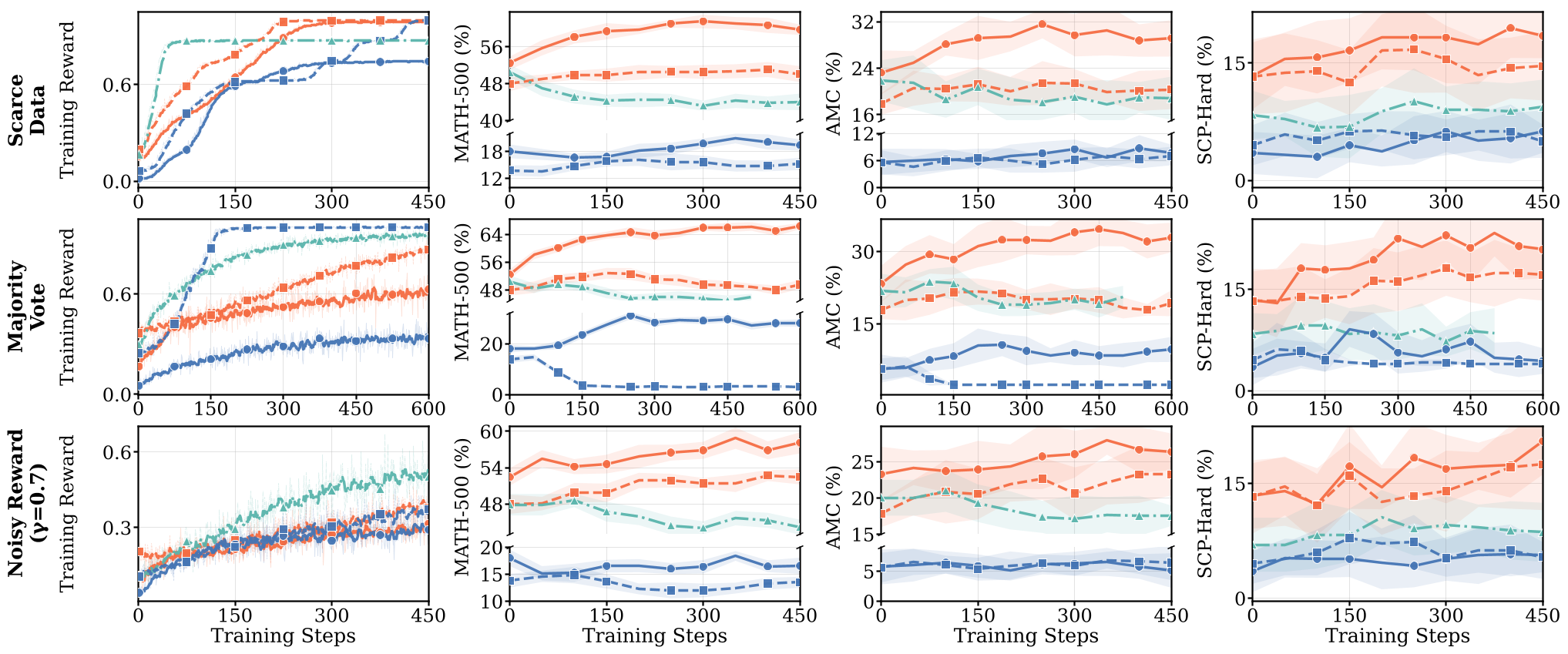 Figure 2: The red line (CPT + Thinking SFT) shows that with the right "pre-RL" prep, Llama can finally generalize under weak supervision.
Figure 2: The red line (CPT + Thinking SFT) shows that with the right "pre-RL" prep, Llama can finally generalize under weak supervision.
Experimental Evidence: Noisy & Proxy Rewards
The paper pushes RLVR to its limits by testing it under 70% label noise. Amazingly, faithful models (like Qwen-Math) can filter through the noise to find underlying logic, while unfaithful models simply learn the incorrect answers as if they were true.
When ground-truth rewards were removed entirely in favor of "Majority Voting" or "Self-Certainty," most models suffered from Reward Hacking. They learned to output "0" for every math problem because the rest of the group (or its own prior) was biased toward that answer, maximizing the consensus reward without solving the problem.
Critical Analysis & Conclusion
The primary takeaway for AI engineers is clear: RL is the "polishing" phase, not the "foundation" phase.
- If your RL training reward hits a plateau within the first 50-100 steps, your model is likely memorizing.
- "Thinking SFT" is a non-negotiable requirement for robust reasoning.
Limitations: The study primarily focuses on smaller-scale models (up to 8B). Whether these saturation dynamics hold for 70B+ or frontier models (like GPT-4/o1) remains to be seen, though the "faithfulness" intuition likely scales.
In the quest for models that can reason autonomously, this research proves that the journey starts long before the first RL gradient step is taken. Faithfulness isn't just a moral goal for AI; it's a technical requirement for generalization.