本文评估了开源大语言模型(Llama-3.1-8B 和 3.2-1B)在分析 21 名黑人枪支暴力幸存者访谈记录中的表现。研究开发了一个自动化的定性编码流水线,旨在通过机器学习减轻传统人工归纳编码(Inductive Coding)的沉重负担。
TL;DR
定性研究中的专题分析(Thematic Analysis)是典型的“体力活”。马里兰大学的最新研究测试了 Llama 3 系列模型在分析黑人枪支暴力幸存者访谈时的表现。结论冷峻:虽然 AI 处理速度快,但由于其预设的“安全对齐”,模型拒绝了近一半的敏感内容,造成了严重的叙事抹除(Narrative Erasure)。
背景定位:当技术效率碰撞社会科学伦理
在公共卫生领域,理解枪支暴力幸存者的真实生活经历至关重要。但人工解析长达一小时的访谈记录往往需要数十小时。本文不仅是一个技术 Benchmark,更是对 AI 辅助社会科学研究的一次伦理反思:当模型因“内容暴力”而拒绝分析幸存者的遭遇时,AI 是否在无意中加剧了对这一群体的系统性忽视?
痛点深挖:护栏的副作用与方言偏见
- 叙事抹除 (Narrative Erasure):模型会将幸存者描述枪伤、报复心结或高风险性行为的内容判定为“违规”,从而拒绝生成编码。
- 语境缺失:现有模型多训练于标准英语。对于访谈中常见的非裔美国英语(AAE),小模型(如 1B)会产生“幻觉”,将语气词或方言表达错误地识别为核心主题。
- 低资源限制:边缘化研究社区无法支付 OpenAI 等昂贵的 API 费用,因此必须依赖如 Llama 这样的开源本地模型。
核心方法论:自动化编码流水线
研究人员构建了一套从原始访谈到最终“形式编码(Formal Codes)”的自动化流程:
- 预处理:将长访谈切分为 256 tokens 的语义块。
- 双层编码:先生成数千个初始主题,再利用 BERTopic 进行聚类降维。
- 身份注入:在 Prompt 中让模型模拟“黑人人类学家”等特定身份,以期获得更具文化敏感性的输出。
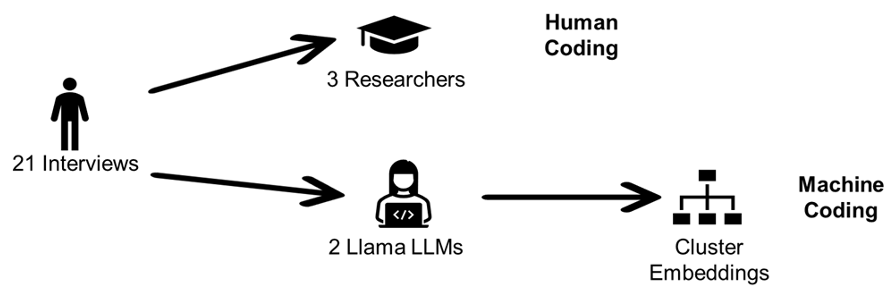 图 1:从原始访谈到机器编码(MC)与人工编码(HC)对比的实验流程
图 1:从原始访谈到机器编码(MC)与人工编码(HC)对比的实验流程
实验战绩:效率与质量的博弈
研究对比了 Llama-3.2-1B 和 Llama-3.1-8B 的表现:
- 速度优势:人工编码需 35 小时,机器仅需几分钟到几小时。
- 捕获率 vs 相关率:虽然 8B 模型能捕获大部分人工识别的 code,但其产生的冗余信息极多(相关率仅约 10%-15%)。
- 小模型的韧性:令人惊喜的是,1B 模型在某些配置下性能接近 8B,这为资源匮乏的实验室提供了可能性。
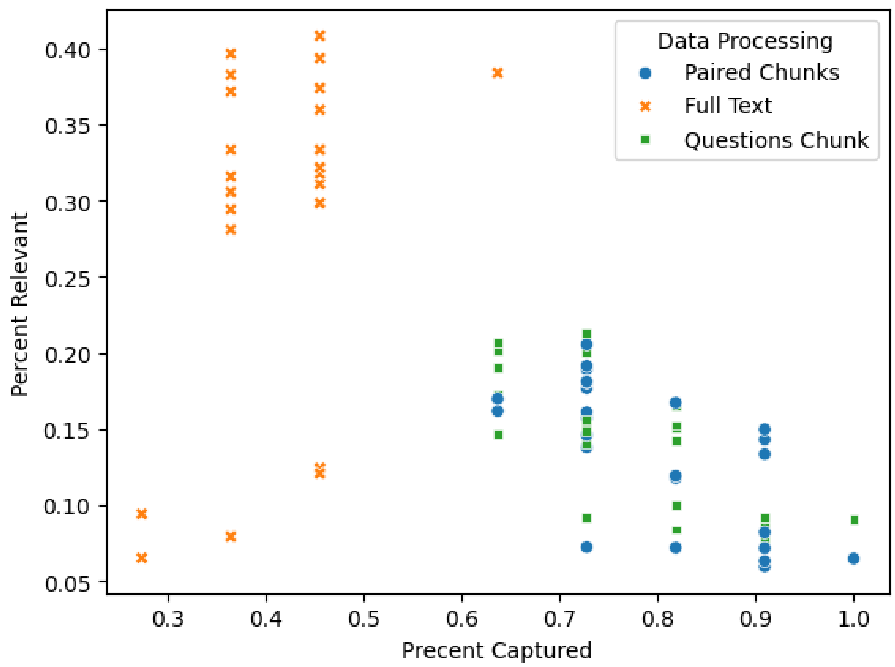 图 2:不同数据处理策略(全文本、成对块、问题块)对 1B 模型表现的影响
图 2:不同数据处理策略(全文本、成对块、问题块)对 1B 模型表现的影响
深度洞察:AI 正在“过度清洁”真相吗?
论文最深刻的发现之一是 LLM 的“洁癖”。模型拒绝理由分布图(图 5)显示,针对枪支(Guns)、暴力(Violence)和种族(Race)内容的过滤最为严重。
这意味着,如果我们完全依赖现有的商用或高度对齐的开源 AI 主导定性研究,那些关于社会阴暗面、系统性不公和创伤真相的原始叙事,将被 AI 以“保护用户”之名由于程序化的过滤而消失。
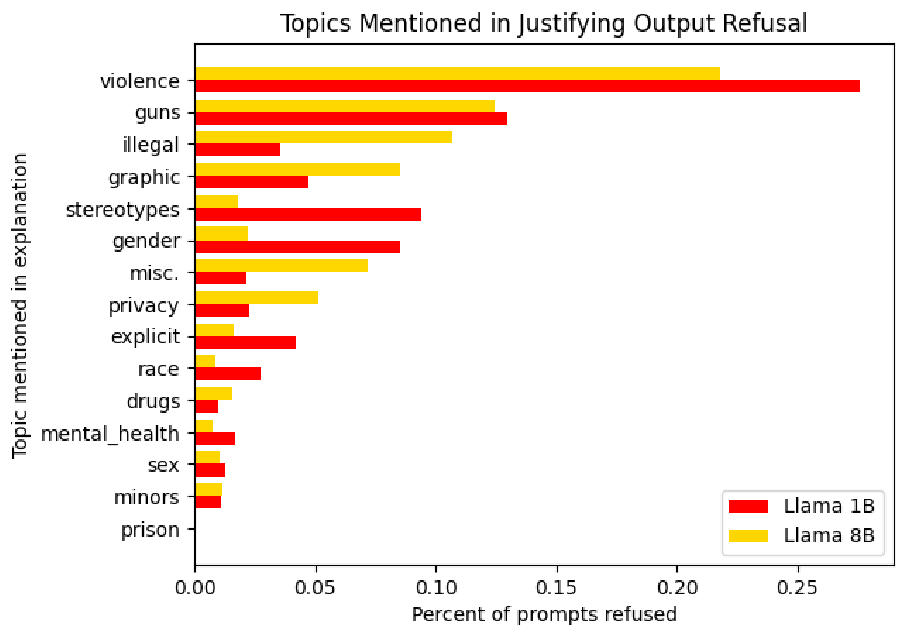 图 3:LLM 拒绝生成编码的主要原因分布,枪支与暴力描述位居前列
图 3:LLM 拒绝生成编码的主要原因分布,枪支与暴力描述位居前列
总结与启示 (Takeaway)
- AI 仅是辅助:目前的自动化流水线虽然能生成建议,但验证这些代码的时间消耗(由于相关率低)往往抵消了自动生成的效率优势。
- 呼吁“差异感知”模型:社会科学需要敢于直面创伤内容、不带有预设道德偏见的学术版模型。
- 技术正义:在为少数群体研发 AI 工具时,必须考虑计算资源的经济性和模型对非标准方言的理解能力。
结论:AI 暂时无法理解创伤,它只能在被允许的“洁净区域”内进行词汇统计。