本文提出了 LMGenDrive,这是首个将基于大语言模型(LLM)的多模态理解与生成式世界模型(Generative World Model)统一在单一边缘端到端闭环自动驾驶框架中的研究。该方法通过联合预测未来驾驶视频和控制信号,在 CARLA LangAuto 榜单上取得了 SOTA 成就(Driving Score 达 62.2)。
TL;DR
传统的自动驾驶系统要么是“死记硬背”的控制映射,要么是只能“空想”的视频生成。LMGenDrive 首次打破了理解与生成的壁垒,将 LLM 的强语义推理与扩散模型的时空预测通过 Query 机制深度耦合。它不仅能听懂“在下一个路口右转”的指令,还能在脑海中预演未来几秒的驾驶画面,并据此给出更稳健的控制指令。在 CARLA 闭环测试中,它以 62.2 DS 的成绩大幅刷新了业界纪录。
1. 痛点:碎片化的感知与想象
在端到端驾驶领域,我们正面临两难境地:
- LLM-based Driving (如 LMDrive):虽然能处理复杂的语言指令(Open-world reasoning),但它们是“瞎子摸象”,对环境如何随时间演变缺乏直观建模,遇到长尾避障场景容易失灵。
- World Models (如 GAIA, DriveWM):能生成极其逼真的驾驶视频(Imagination),但大多用于离线数据增强或纯预测,缺乏与决策系统的深度统一,且往往无法直接遵循自然语言指令。
人类驾驶员在复杂路口会“脑补”可能的危险。LMGenDrive 的核心动机就是赋予 AI 这种将理解(Understanding)与想象(Imagination)统一的能力。
2. 核心架构:大脑(LLM)与幻影(Diffusion)的共舞
LMGenDrive 的设计非常精妙,它采用了模块化但端到端可导的架构:
2.1 架构拆解
- 感知端 (Vision Encoder):摒弃了依赖 LiDAR 的传统路线,通过多视角图像生成 BEV Token、Waypoint Token 和 Traffic Token,确保了系统的纯视觉兼容性。
- 推理端 (LLM Brain):基于 Vicuna-7B (LLaMA),引入了两种关键的 learnable queries:
- Action Query: 演化为未来的行驶轨迹点(Waypoints)。
- World Query: 吸收指令和视觉上下文,作为扩散生成的特征底色。
- 生成端 (World Generator):基于 Stable Diffusion 和 AnimateDiff,利用 LLM 输出的 World Query 结合上一帧图像作为 Condition,合成未来 8 帧的多视角驾驶视频。
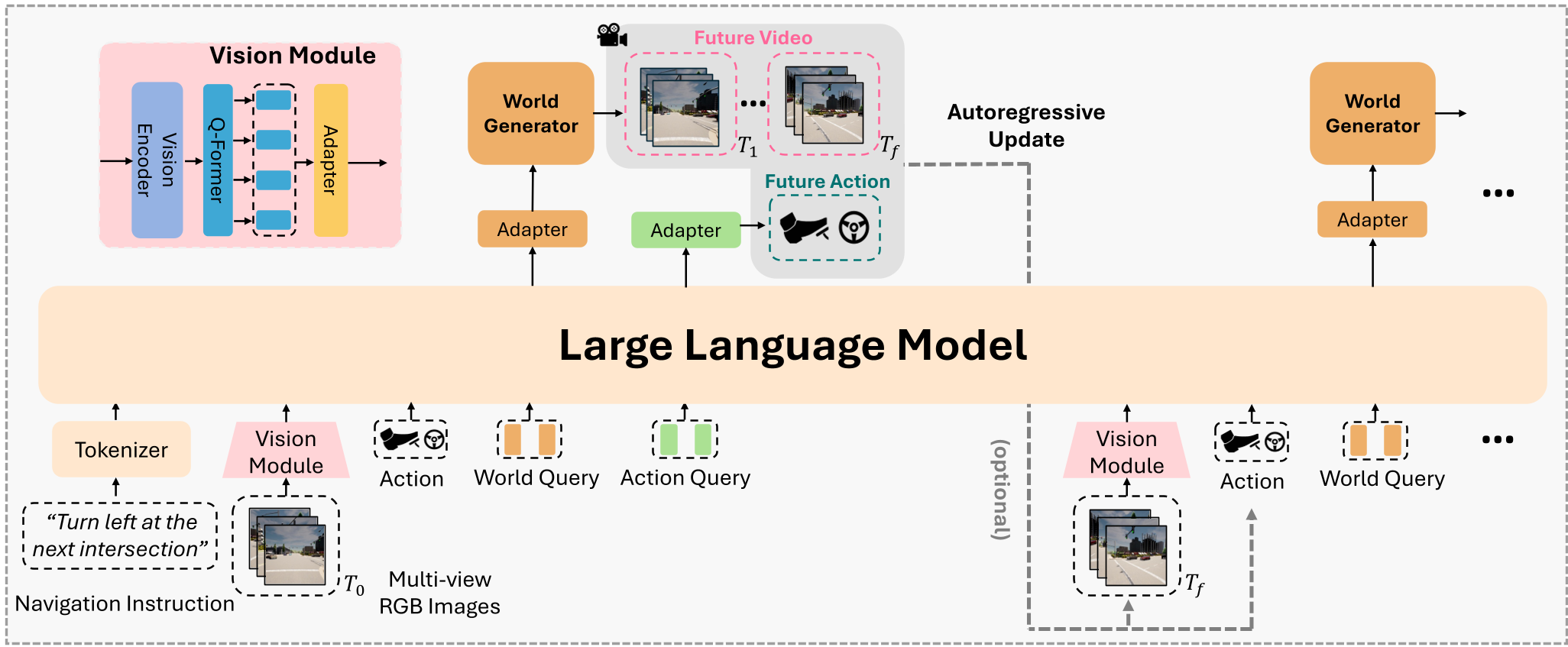 图 1: LMGenDrive 整体框架图。左侧为 LLM 处理理解任务,右侧为扩散模型处理生成任务,两者通过特征空间耦合。
图 1: LMGenDrive 整体框架图。左侧为 LLM 处理理解任务,右侧为扩散模型处理生成任务,两者通过特征空间耦合。
3. 三阶段课程学习:从识图到长时演化
为了训练这样一个复杂的统一模型,作者提出了三阶段训练策略,这对于系统的稳定性至关重要:
- Stage 1: 视觉预训练。在 3M 专家数据上训练感知能力(检测、信号灯识别)。
- Stage 2: 单步规划与生成。冻结感知端,让 LLM 学习如何根据指令输出动作和单步未来的预测。
- Stage 3: 多步长时程训练。引入自回归机制,将生成的视频回传给 LLM 训练,解决误差累积问题,增强时空一致性。
4. 实验结果:统治级的 SOTA 表现
在最具挑战性的 CARLA LangAuto 榜单上,LMGenDrive 展示了压倒性的优势。
 表 1: 在复杂城镇和多变天气下的闭环测试结果。
表 1: 在复杂城镇和多变天气下的闭环测试结果。
深度分析:
- 理解与生成的互补:消融实验显示,如果丢掉“视频生成器”,Driving Score (DS) 会从 62.2 跌至 53.4。这意味着强制模型去“想象”未来画面,反过来迫使 LLM 提取更深刻的时空表征,辅助了规划。
- 多视角一致性:通过引入 Multi-view Fusion 块,生成的左、前、右视角不再产生错位,这对于转弯等大动态场景下的规划至关重要。
5. 局限性与展望
尽管 LMGenDrive 阶段性地解决了“理解+想象”的统一问题,但它仍面临挑战:
- 长程衰减:实验显示,生成超过 64 帧后,时空一致性(FVD)会迅速恶化,存在“幻觉”风险。
- 算力开销:扩散模型在实时推理时仍然较重,目前在线规划模式需裁剪生成分支以降低延迟。
6. 总结
LMGenDrive 的价值在于它验证了一个极具潜力的范式:未来的自动驾驶不应只是简单的动作映射网络,而是一个拥有强大世界理解力、能通过模拟未来来优化当前决策的“数字孪生体”。 这种将 AGI 领域的生成能力与 Embodied AI 结合的思路,为解决驾驶长尾问题提供了新的曙光。