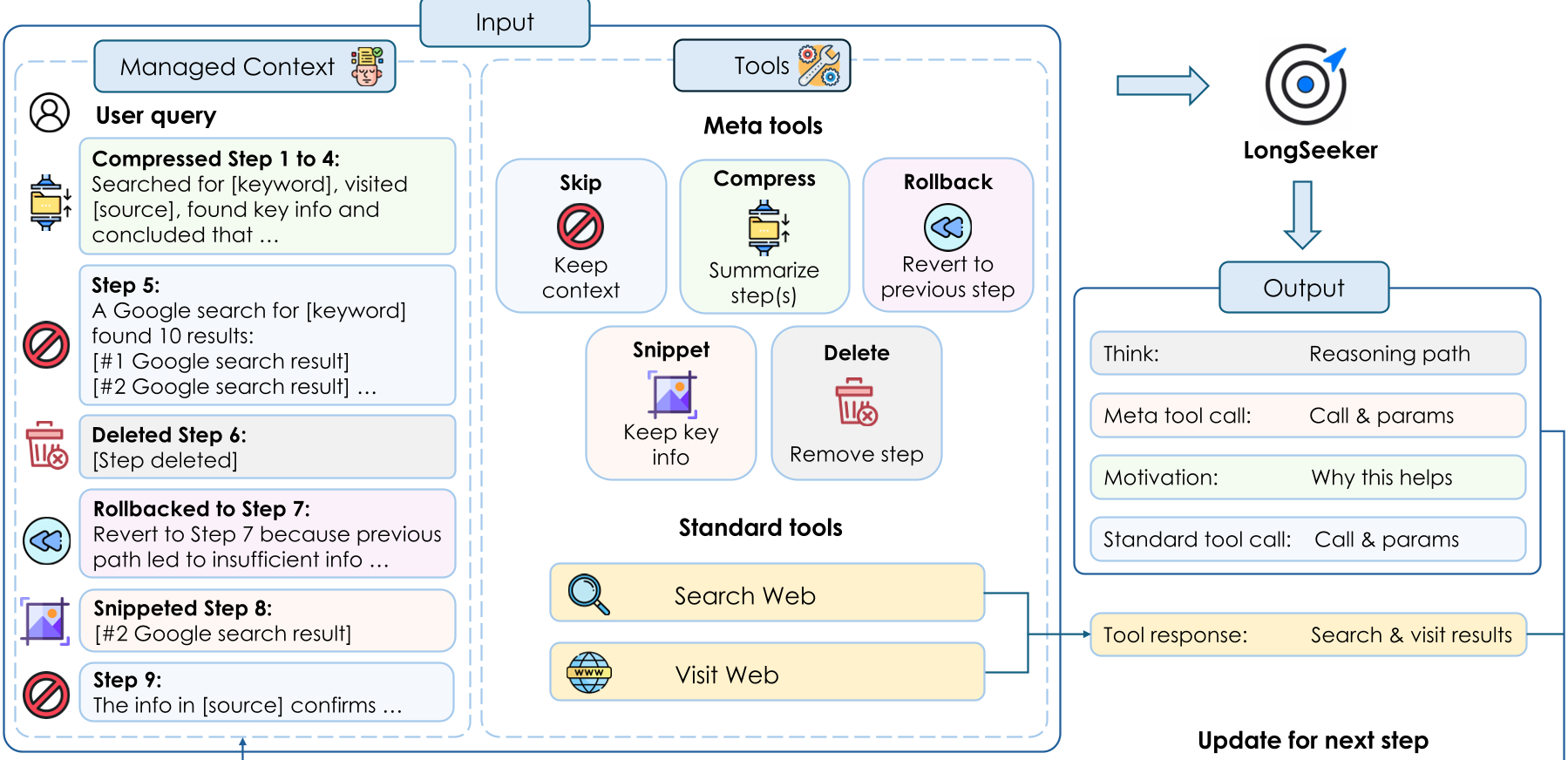
本文提出了 LongSeeker,这是一种专为长程搜索(Long-horizon Search)设计的智能体。其核心贡献在于引入了 Context-ReAct 范式,通过 5 种原子元操作(Skip, Compress, Rollback, Snippet, Delete)实现了对工作上下文的动态弹性编排,打破了传统 ReAct 模式下的上下文膨胀瓶颈。
TL;DR
传统的 AI 搜索智能体就像一个“囤积癖”,随着搜索步骤的增加,所有的网页内容和推理过程都会被塞进上下文窗口,最终导致模型“内存溢出”或思绪混乱。LongSeeker 改变了这一现状:它通过 Context-ReAct 范式,让智能体学会了“断舍离”。通过五种精细化的元操作,它能自主决定哪些信息该总结、哪些该删除、哪些该精准保留。实验证明,它在复杂搜索任务上的表现大幅超越了阿里和字节的同类模型,且上下文长度始终保持在极低水平。
背景:被“撑死”的 ReAct 智能体
在长程任务(Long-horizon tasks)中,智能体需要调用工具(如搜索网页)、观察结果、更新推理。目前主流的 ReAct 架构由于采用单调递增的追加模式,面临三大痛点:
- 噪声污染:无效的搜索结果会干扰模型的判断力。
- 信噪比下降:核心证据被淹没在冗长无关的信息中。
- 资源枯竭:即使是 128k 甚至更长的上下文窗口,在数十轮复杂的搜索面前也显得捉襟见肘。
作者给出的药方是:弹性上下文编排(Elastic Context Orchestration)。
核心武器:Context-ReAct 的五大原子操作
LongSeeker 不再机械地记录历史,而是在每一步行动前,先进行一次“内观”,通过以下五种操作重塑自己的记忆:
- Skip:若当前信息精炼,不作变动。
- Compress:对过去的某一段轨迹进行抽象总结,保留结论。
- Snippet:这是本文的亮点。针对数字、代码等关键信息,它不使用易产生幻觉的总结,而是通过指令式提取实现“无损保留”。
- Delete:直接擦除被证伪或无用的冗余信息。
- Rollback:就像玩游戏读档,当发现搜索路径错误时,它会回溯到之前的某个状态,并记录“为什么这条路没走通”,避免重蹈覆辙。
技术直觉:作者在文中证明了
Compress操作在表达上是完备的(Expressively Complete),但为了效率和保真度,引入Snippet和Rollback提供了关键的感官偏置(Inductive Bias),降低了模型在长程任务中的幻觉风险。
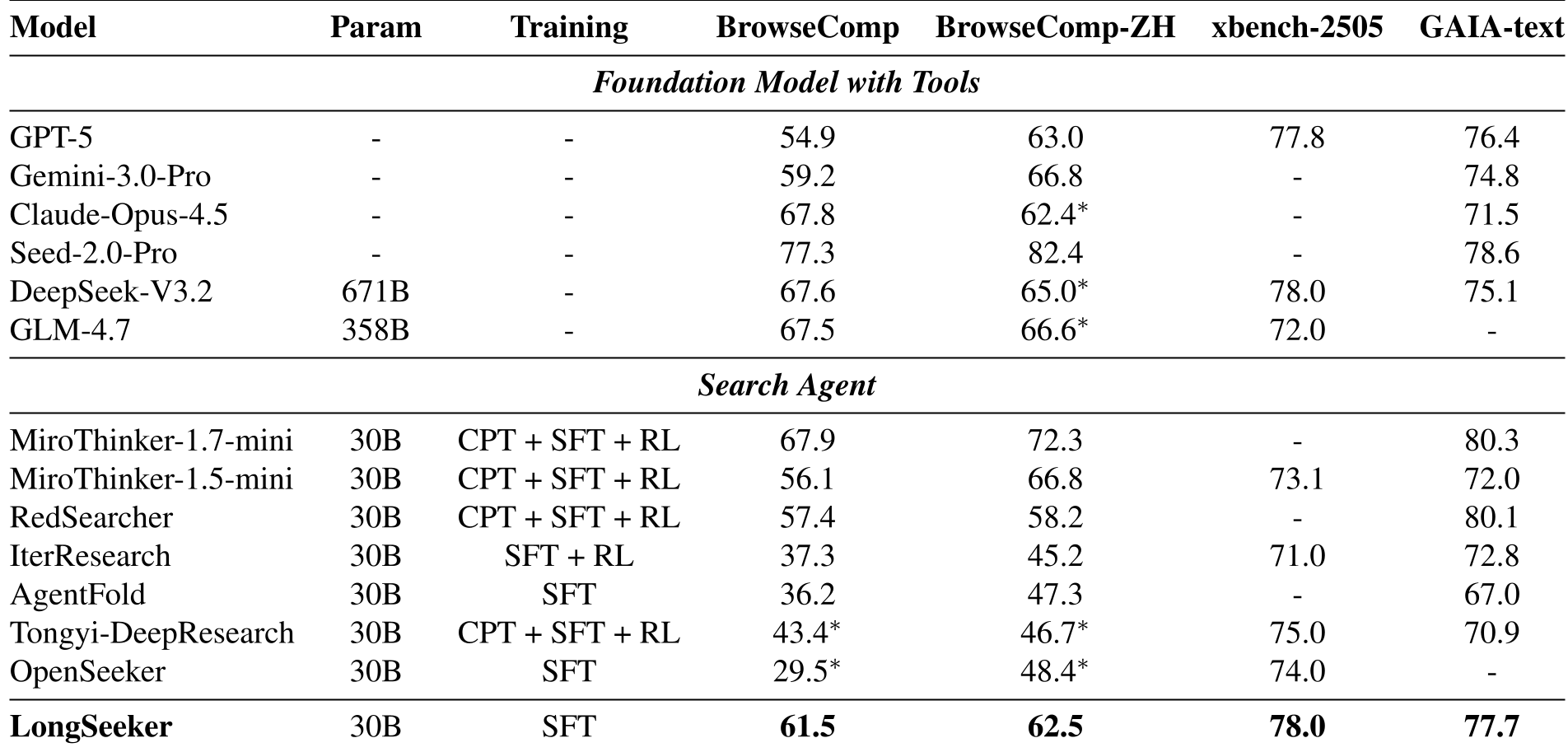
实验与结果:小参数,大能量
LongSeeker 仅使用了 30B 参数(微调自 Qwen3),但在处理复杂搜索任务时展现出了惊人的效率。
1. 性能霸榜
在 BrowseComp(英语)和 BrowseComp-ZH(中文)基准测试中,LongSeeker 的得分分别为 61.5% 和 62.5%,这一成绩不仅超越了同样是开源范畴的 Tongyi DeepResearch,甚至紧追 GPT-5 和 Gemini 3.0 Pro 等闭源巨头。
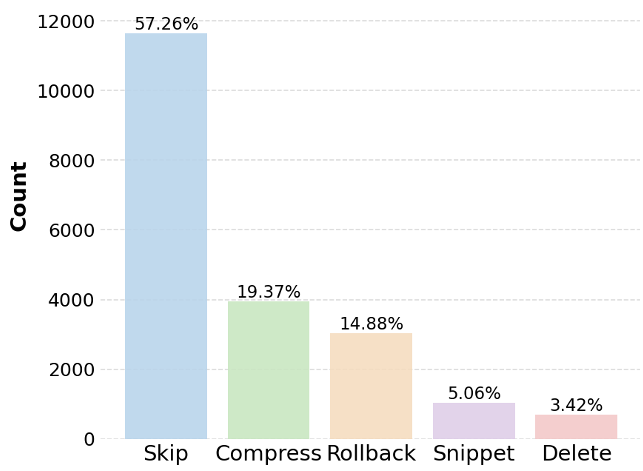
2. 上下文增长动力学
观察下图(a),可以明显看到对比。传统的 ReAct 轨迹(如 DeepSeek-V3.2 模式)Token 数呈直线爆炸增长;而 LongSeeker 即使推理到 300 步以上,上下文长度依然稳定在 15k 以内。这种“稳如老狗”的记忆控制能力,是其能持续处理高难度任务的关键。
深度洞察:让上下文管理成为一种推理本能
LongSeeker 的成功揭示了一个深刻的道理:有效的信息检索不仅仅是“找”,更是“扔”。
以往的研究(如 AgentFold)主要是在一段对话结束后进行总结,这属于“后处理”。而 LongSeeker 将上下文操作整合进了 next-token prediction 的生成过程中。在模型的 structured output 中,推理理由、元操作指令和工具调用是同时生成的。这意味着模型在思考“下一步搜什么”时,也在同时思考“之前的记忆里哪些已经过时了”。
总结与局限
LongSeeker 证明了主动管理工作记忆可以极大地提升复杂任务的可靠性。然而,该方法目前还比较依赖高质量的合成数据(由更强大的模型如 DeepSeek-V3.2 作为老师进行标注)。
未来方向:作者提到,利用强化学习(RL)来进一步优化元操作的决策逻辑将是下一个高地。此外,这种弹性上下文范式不仅能用于搜索,未来在自动编程、长法律文档分析等领域也极具想象空间。
关键词:Long-horizon Search, Context Management, ReAct, LongSeeker, 弹性编排