本文提出了 DeepVision-VLA,一种通过 Vision-Language Mixture-of-Transformers (VL-MoT) 架构增强视觉表征的机器人操纵模型。该模型通过将 DINOv3 视觉专家的多级特征注入到 VLA 主干网络的深层,并在 SOTA 基线基础上实现了模拟任务 9.0% 和真实任务 7.5% 的成功率提升。
TL;DR
传统的视觉-语言-动作(VLA)模型在预测动作时,往往会随着神经网络深度的增加而逐渐屏蔽掉关键的视觉信息。DeepVision-VLA 通过引入 VL-MoT (视觉-语言混合 Transformer) 架构和 AGVP (动作引导视觉剪枝) 技术,直接将高分辨率的视觉专家特征“空投”到模型的深层,显著提升了机器人在复杂、精确操作任务(如写字、叠罐头、精准倾倒)中的成功率。
- 性能战绩:RLBench 模拟环境 SOTA (83% S.R.),真实机器人任务平均成功率达 91.7%。
- 核心技术:深层特征注入 + 基于注意力机制的动态视觉剪枝。
痛点深挖:消失的视觉敏感度
尽管现有的 VLA 模型(如 OpenVLA, RT-2)在通用性上表现出色,但它们大多遵循“视觉特征输入 -> 堆叠 LLM 层 -> 动作输出”的串行逻辑。
作者通过 Grad-CAM 和 Layer-wise Token Dropout 实验揭示了一个令人惊讶的现象:
- 浅层清醒,深层迷糊:在模型的浅层,Attention 能够精准锁定机械臂和操作目标;但在深层,注意力变得弥散,动作生成对视觉 token 的依赖度大幅下降。
- 信息稀释:视觉信息在经过数十层 Transformer 处理后,被语言指令和内部隐藏状态淹没,导致对于需要微调的高精度任务(Precision Manipulation)力不从心。
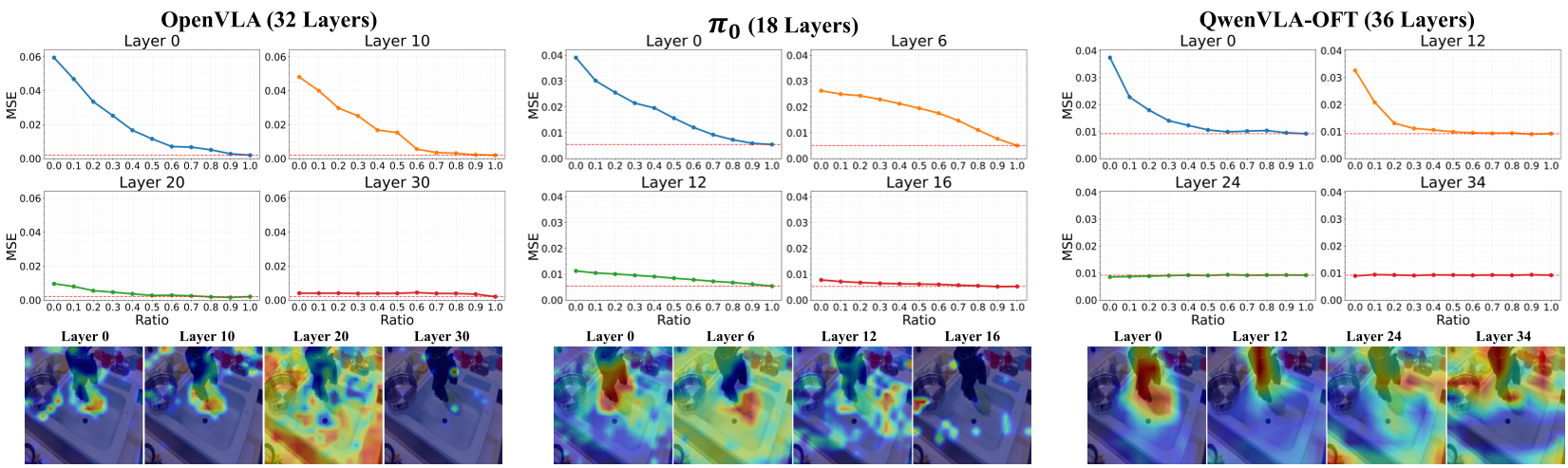 图 1:实验证明,屏蔽深层视觉 Token 对动作 MSE 的影响微乎其微,说明深层模型已经“视而不见”。
图 1:实验证明,屏蔽深层视觉 Token 对动作 MSE 的影响微乎其微,说明深层模型已经“视而不见”。
核心方法论:DeepVision-VLA 的“深层补强”
1. VL-MoT:视觉专家的深层介入
为了解决深层视觉信息缺失,作者引入了一个 0.8B 的 DINOv3 作为“视觉专家”。
- 不再是简单的拼接:不同于在输入端合并特征,VL-MoT 采用了一种共享注意力(Shared-Attention)机制。在 VLA 主干的深层,直接提取视觉专家的 QKV 矩阵进行融合计算。
- 逻辑直觉:由于 DINOv3 的后期层包含丰富的目标语义和空间结构信息,这与需要产生动作行为的 VLA 深层特征在语义上高度契合。
2. AGVP:按需取用的视觉剪枝
直接引入高分辨率(512x512)特征会带来巨大的计算开销。DeepVision-VLA 提出了一种极其巧妙的解法:
- 借力打力:利用模型浅层(已经被证明视觉感知较准的层)生成的
Action-to-Vision注意力图作为热力图。 - 精准打击:只保留热力图中最关键的 Top-K 视觉 Token(如操作瓶口、指尖区域),过滤冗余背景。这种“按需感知”的策略在提升分辨率的同时降低了推理延迟。
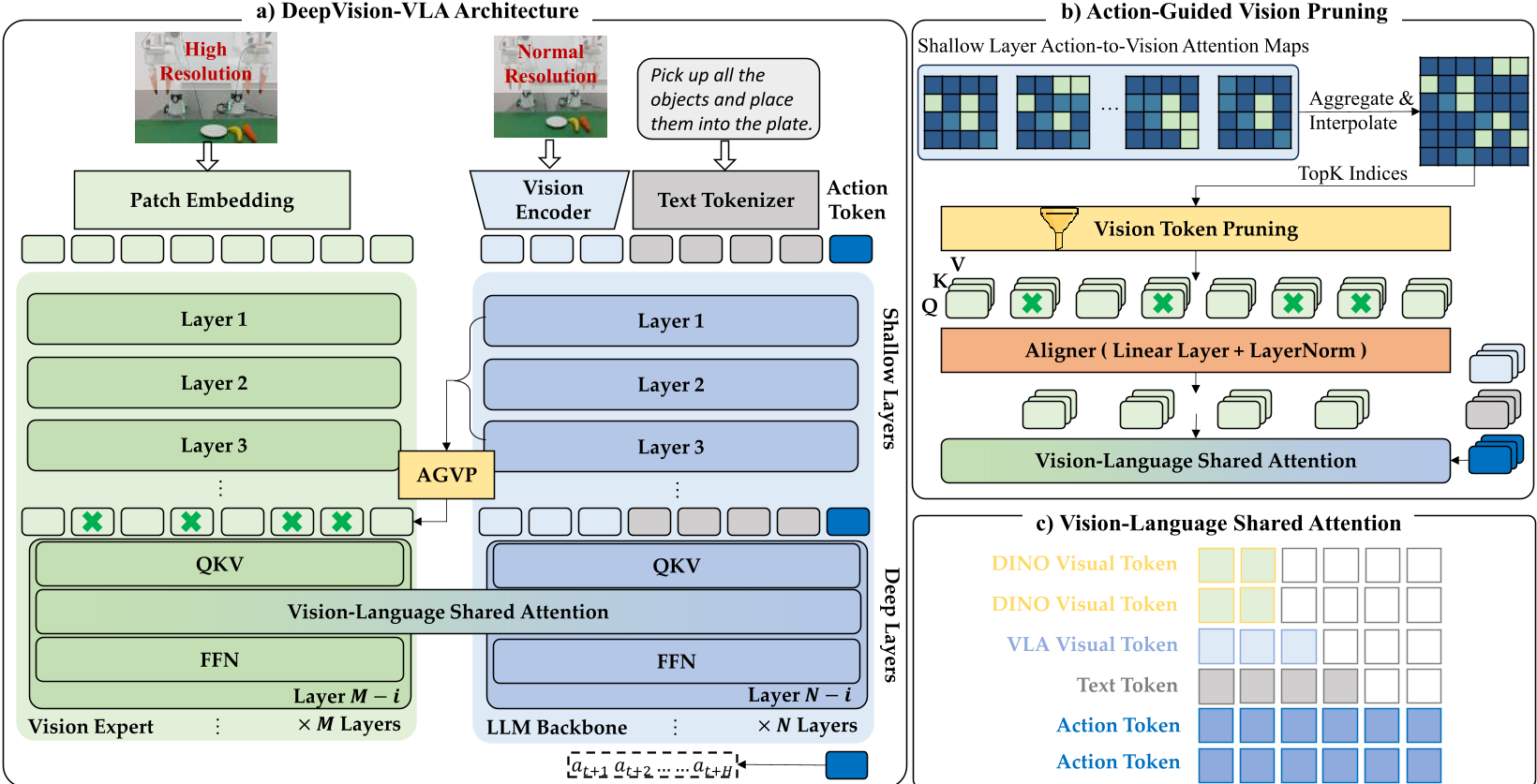 图 2:整体架构。通过 AGVP 剪枝后的高精度特征与 LLM 深层共享注意力。
图 2:整体架构。通过 AGVP 剪枝后的高精度特征与 LLM 深层共享注意力。
实验与结果:全线碾压的稳健表现
在 RLBench 的 10 项严苛任务中,DeepVision-VLA 的表现不仅稳定且上限高。在“扫垃圾进簸箕 (Sweep to dustpan)”和“放酒瓶 (Wine at rack)”等极度依赖视觉反馈的任务中,其成功率比基线模型高出 30%-80%。
 表 1:DeepVision-VLA 在大多数任务上均达到最高成功率。
表 1:DeepVision-VLA 在大多数任务上均达到最高成功率。
真实世界验证: 在 Franka 机械臂上进行的四项复杂任务测试(包括写字、倒饮料)中,DeepVision-VLA 展现了极强的泛化能力。即使在未见过的背景或光照剧烈变化的环境下,依然保持了极高的操作精度,证明了其架构设计在处理物理世界不确定性方面的优越性。
深度洞察与总结
DeepVision-VLA 的成功给了我们三个重要启发:
- 端到端不代表一成不变:LLM 强大的推理能力并不等同于它在每一层都能完美保持视觉精度,针对物理交互任务,特殊的微结构设计(如 VL-MoT)至关重要。
- 视觉专家的价值:利用像 DINOv3 这样拥有强空间先验的 Foundation Model 作为“插件”,比单纯扩大 VLA 的训练数据集更高效。
- 动作引导的注意力:机器人模型应该学会主动决定“看哪里”,AGVP 这种基于动作反馈的动态剪枝是平衡高分辨率需求与计算效率的利器。
局限性:尽管模型表现强劲,但目前仍依赖于离线预训练的视觉专家模型,未来如何实现视觉专家与控制主干的协同协同进化(Co-evolution)仍是值得探索的方向。