LoST (Level of Semantics Tokenization) is a novel 3D shape tokenization method that orders tokens by semantic salience rather than geometric detail. It allows Autoregressive (AR) models to decode complete, plausible shapes from just a few tokens, setting a new SOTA in 3D generation.
TL;DR
LoST (Level of Semantics Tokenization) is a paradigm shift in how we represent 3D shapes for AI. Instead of breaking a shape down into smaller and smaller geometric boxes (Level-of-Detail), it breaks it down by "meaning" (Level-of-Semantics). This allows a model to understand a "chair" from its first token, using subsequent tokens only to refine the specific style or texture. The result? SOTA 3D generation using 90-99% fewer tokens.
Problem: The "Token Bloat" of Geometric Hierarchies
Traditional 3D AR models treat shapes like zip files. They use Octrees or meshes to define space. If you stop the generation early, you get a "cloud" or a "scaffold" that looks nothing like the final object. This is geometrically logical but semantically nonsensical.
For an Autoregressive (AR) model, this is a nightmare:
- High Perplexity: The model spends thousands of tokens defining "empty space" or "coarse blocks" before getting to the actual object.
- Inflexible Decoding: You can't stop early to save compute; the intermediate results are useless.
Methodology: Semantics First, Geometry Later
LoST introduces a Level-of-Semantics (LoS) hierarchy. The goal is simple: the first token should represent the most "salient" part of the shape (e.g., the essence of a car), and the 512th token should represent a tiny scratch on the fender.
The RIDA Innovation
To train this, the authors needed a way to tell the model what "semantics" are. While we have DINO for images, we don't have a "DINO for 3D." The authors proposed Relational Inter-Distance Alignment (RIDA).
Instead of trying to force 3D features to look like 2D pixels (which fails due to dimensionality mismatch), RIDA aligns the relationships between objects. If a "Sports Car" is semantically close to a "Sedan" but far from a "Tree" in the image domain (DINO), RIDA ensures the 3D features maintain that same distance in the 3D latent space.
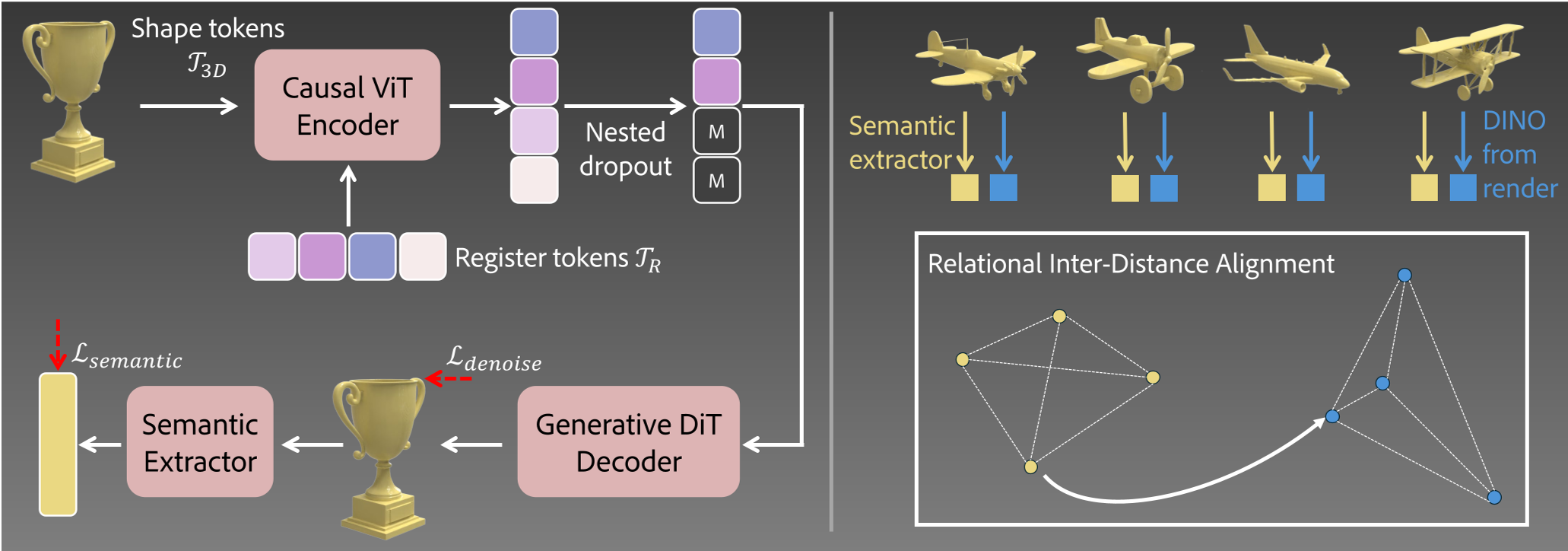 Figure: Overview of LoST. Left: Mapping 3D latents to semantic sequences. Right: RIDA pre-training for semantic Extractors.
Figure: Overview of LoST. Left: Mapping 3D latents to semantic sequences. Right: RIDA pre-training for semantic Extractors.
Experiments: Doing More with Less
The results are staggering. In 3D reconstruction benchmarks, LoST with just 4 tokens often outperforms baseline models (like OctGPT) using thousands of tokens.
For Autoregressive generation, the LoST-GPT model uses only 128 tokens. Compared to Llama-Mesh or ShapeLLM-Omni, it achieves significantly better FID scores (a measure of generation quality) while being orders of magnitude faster and more efficient.
 Figure: LoST vs. LoD baselines. Notice how the 1st token of LoST already looks like a recognizable shape.
Figure: LoST vs. LoD baselines. Notice how the 1st token of LoST already looks like a recognizable shape.
Critical Analysis & Conclusion
LoST proves that for 3D generative AI, how we tokenize is as important as the model architecture itself. By aligning 3D latents with proven 2D semantic foundations (DINO), the authors bypassed the need for massive 3D-native semantic datasets.
Limitations:
- The method currently relies on a Diffusion decoder to turn tokens back into 3D shapes, which adds a computational step.
- While it handles geometry brilliantly, expanding this to high-fidelity "Gaussian Splatting" or complex textures is the next frontier.
The Takeaway: If you want to build the "LLM for 3D," stop thinking in voxels and start thinking in semantics.