LPM 1.0 (Large Performance Model) is a comprehensive video-generative framework including a 17B Diffusion Transformer for high-fidelity audio-visual conversational performance. It addresses the "performance trilemma" (expressiveness, real-time speed, and identity stability) and includes Online LPM, a distilled causal version capable of real-time, infinite-length streaming.
TL;DR
LPM 1.0 is a groundbreaking framework that moves beyond traditional lip-sync models to create "living" digital characters. By introducing a 17B Diffusion Transformer (Base LPM) and a real-time distilled version (Online LPM), it enables characters to not only speak but also listen, react, and maintain a consistent identity over infinite time horizons—all in real-time.
The Problem: The Performance Trilemma
In the realm of AI-generated humans, we have long suffered from a "Trilemma." You could have Expressive Quality (vivid micro-expressions), but you'd lose Real-time Inference. You could have Speed, but the character's Identity would drift or "melt" after 30 seconds.
Most critically, researchers have ignored the "Listening" half of conversation. A natural character shouldn't just be a static image when the user speaks; they should nod, blink, and react emotionally.
Methodology: Engineering a "Full-Duplex" Actor
1. Interleaved Dual-Audio Conditioning
To handle both speaking (lip-sync/high energy) and listening (subtle reactions/low energy), LPM uses an interleaved architecture. Even-numbered layers focus on the speaker's audio, while odd-numbered layers process the listener's audio. This prevents "gradient conflict" and allows the model to specialize in both high-frequency lip movements and low-frequency postural shifts.
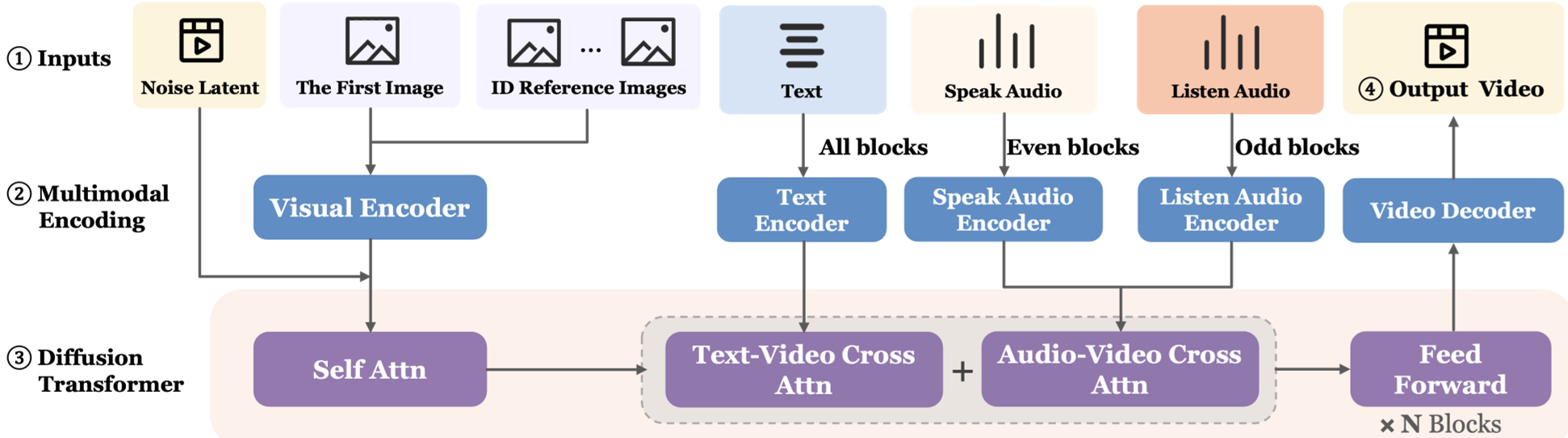
2. Multi-Reference Identity Anchoring
Single-image conditioning often leads to hallucinations. LPM conditions on multiple references:
- Global References: For overall scene/lighting.
- Multi-view Body: For consistent profiles and rear views.
- Facial Expressions: Ensuring the "teeth" and "smile lines" belong to that specific character across different emotions.
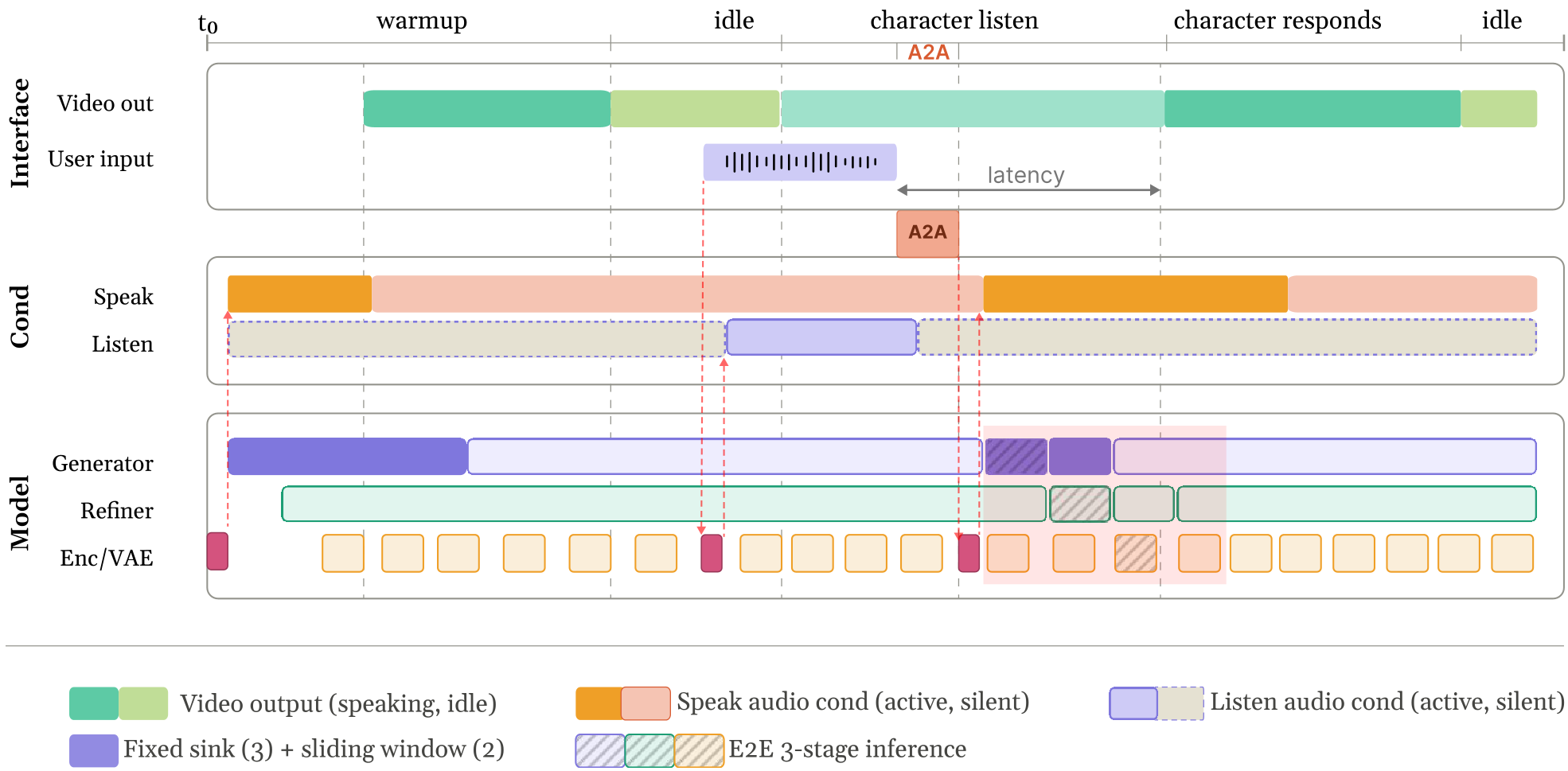
3. Online Distillation: The Backbone-Refiner Split
How do you make a 17B DiT run at 24fps? The authors used a Backbone-Refiner architecture. The Backbone handles the coarse movement and temporal stability (using noisy-history caches), while a one-step Refiner restores the high-frequency visual details.
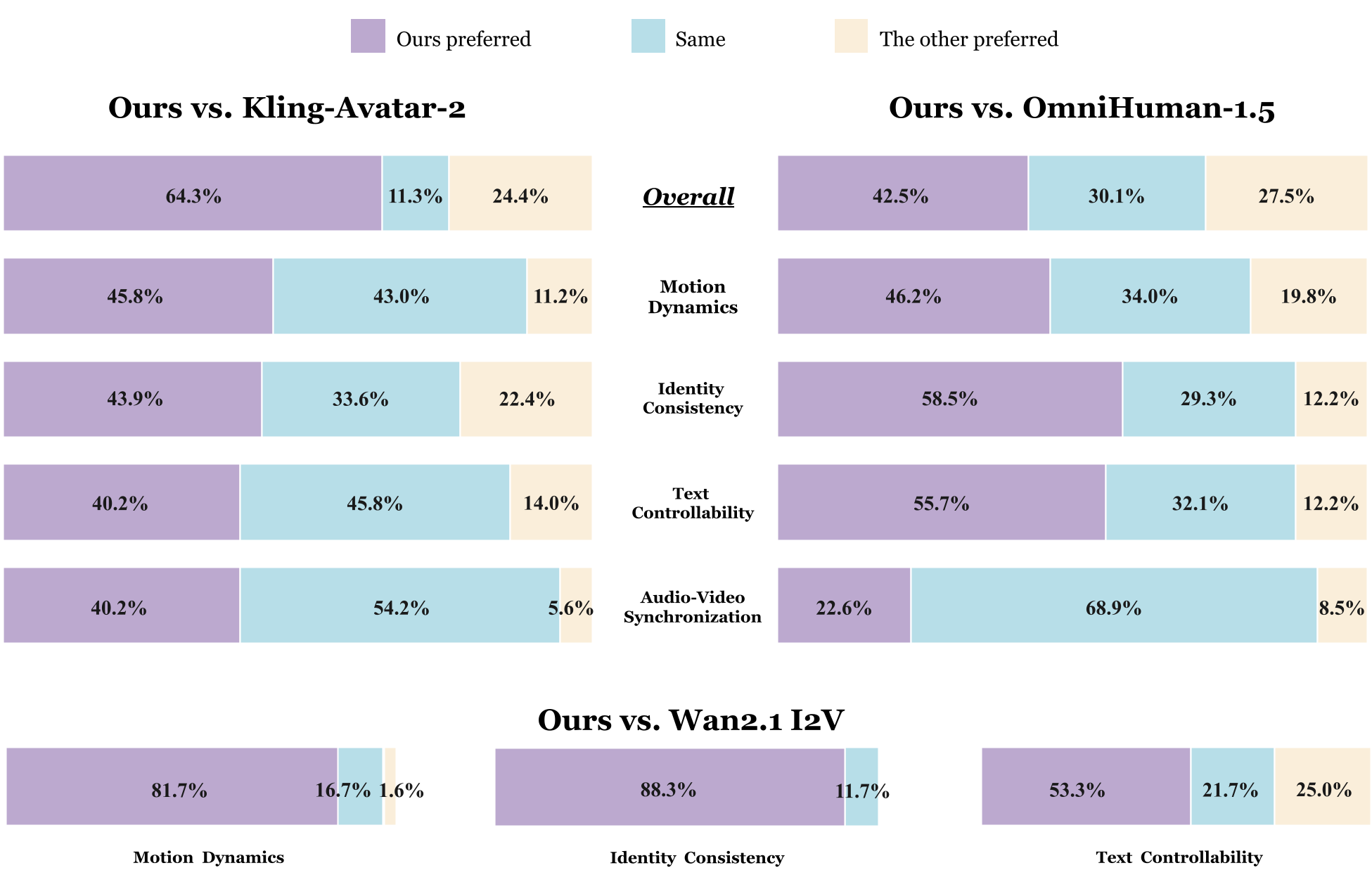
Experiments: Setting a New SOTA
The researchers introduced LPM-Bench, the first benchmark specifically for interactive performance.
- Base LPM (720P): Outperformed Kling-Avatar-2 and OmniHuman-1.5, particularly in "Text Controllability" and "Identity Consistency."
- Online LPM (480P): Achieved a massive 82.5% preference over LiveAvatar. Most impressively, the distilled model was judged as nearly indistinguishable from the high-quality base model in 42-88% of cases.
Critical Insights & Takeaways
The core genius of LPM 1.0 isn't just a bigger model; it's the recognition that "Acting is Reacting". By treating "listening" as a primary input modality and using multi-view references as 3D-consistent anchors, LPM 1.0 provides a production-ready engine for NPCs, virtual streamers, and AI companions.
Limitations: The model is still mostly optimized for single, camera-facing characters. Future iterations will need to handle complex 3D environments and multi-party coordination (like a group dinner conversation).
Future Outlook: We are moving toward "Unified Actor Models" where the AI determines what to say and how to move simultaneously, blurring the line between LLM reasoning and visual generation.