LumosX is a novel framework for personalized multi-subject video generation that introduces explicit face-attribute dependency modeling. It leverages a new data collection pipeline and "Relational Attention" mechanisms to achieve state-of-the-art results in identity-consistent and subject-consistent video synthesis using the Wan2.1 Diffusion Transformer (DiT) backbone.
TL;DR
LumosX solves the "who is wearing what" problem in AI video generation. By introducing Relational Attention and a specialized data pipeline, it explicitly binds faces to their specific attributes (clothes, accessories), preventing the common "ID-swapping" or "attribute bleeding" seen in previous multi-subject models like Phantom or SkyReels-A2.
The Problem: Identity Confusion in Multi-Subject Scenes
While Text-to-Video (T2V) models have reached incredible levels of realism, personalization remains a "wild west." When you ask a model to generate "A man in a red hoodie and a woman in a blue dress," current DiT (Diffusion Transformer) architectures often mix them up. The model might put the red hoodie on the woman or blend their facial features. This happens because the Inductive Bias of standard attention is too global; it doesn't know that specific visual tokens (the face) must "stay" with specific attribute tokens (the clothes).
Methodology: The "Relational" Secret Sauce
LumosX tackles this through two core innovations: a sophisticated data engine and a relational architectural overhaul.
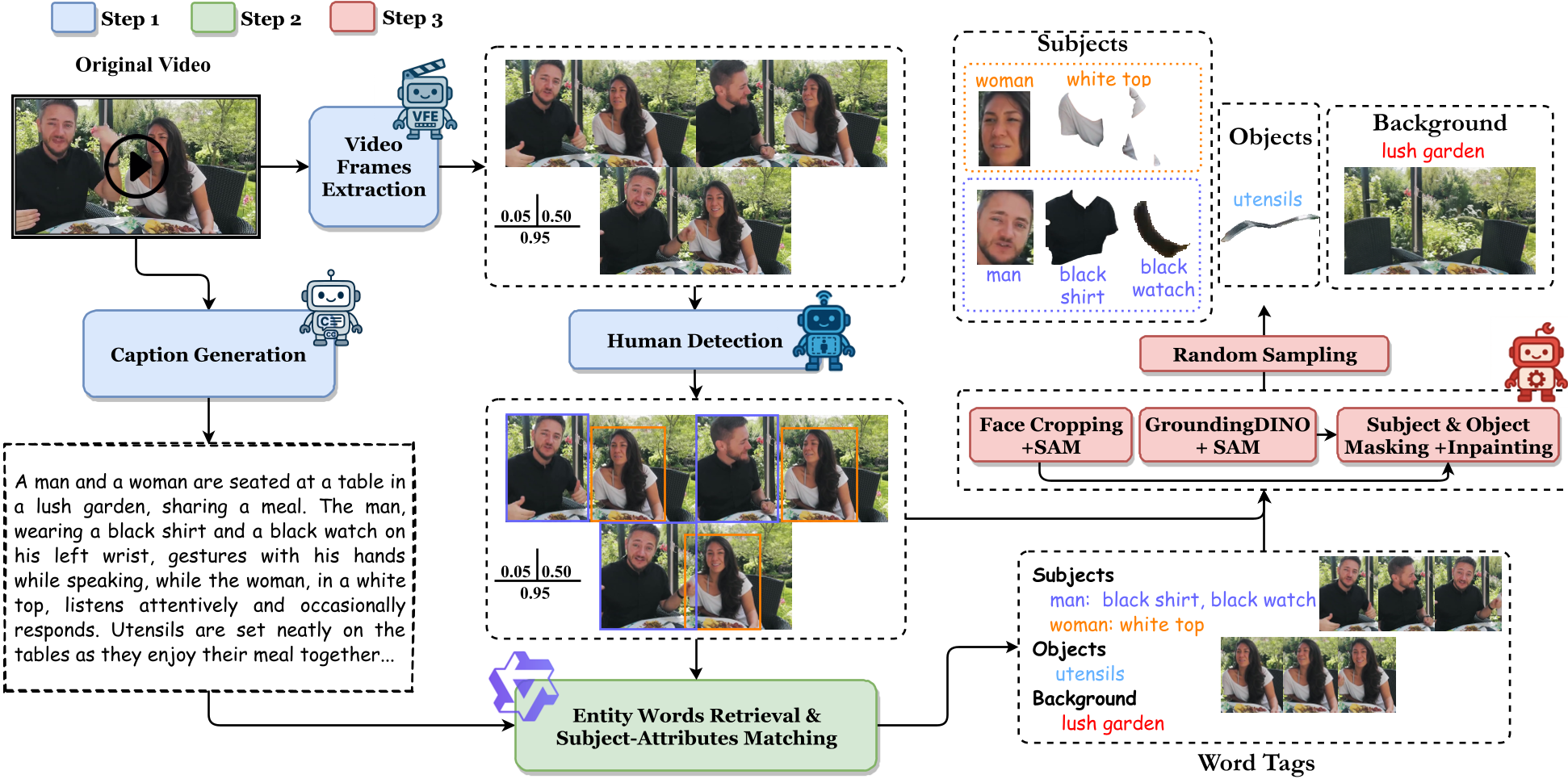
1. The Relational Data Engine
The researchers built a pipeline that transforms raw video into "relational training pairs." Using Qwen2.5-VL, the system doesn't just caption a video; it identifies subjects and matches them to their attributes (e.g., "Person A: green shirt, glasses"). It then segments these elements to create clean condition images for training.
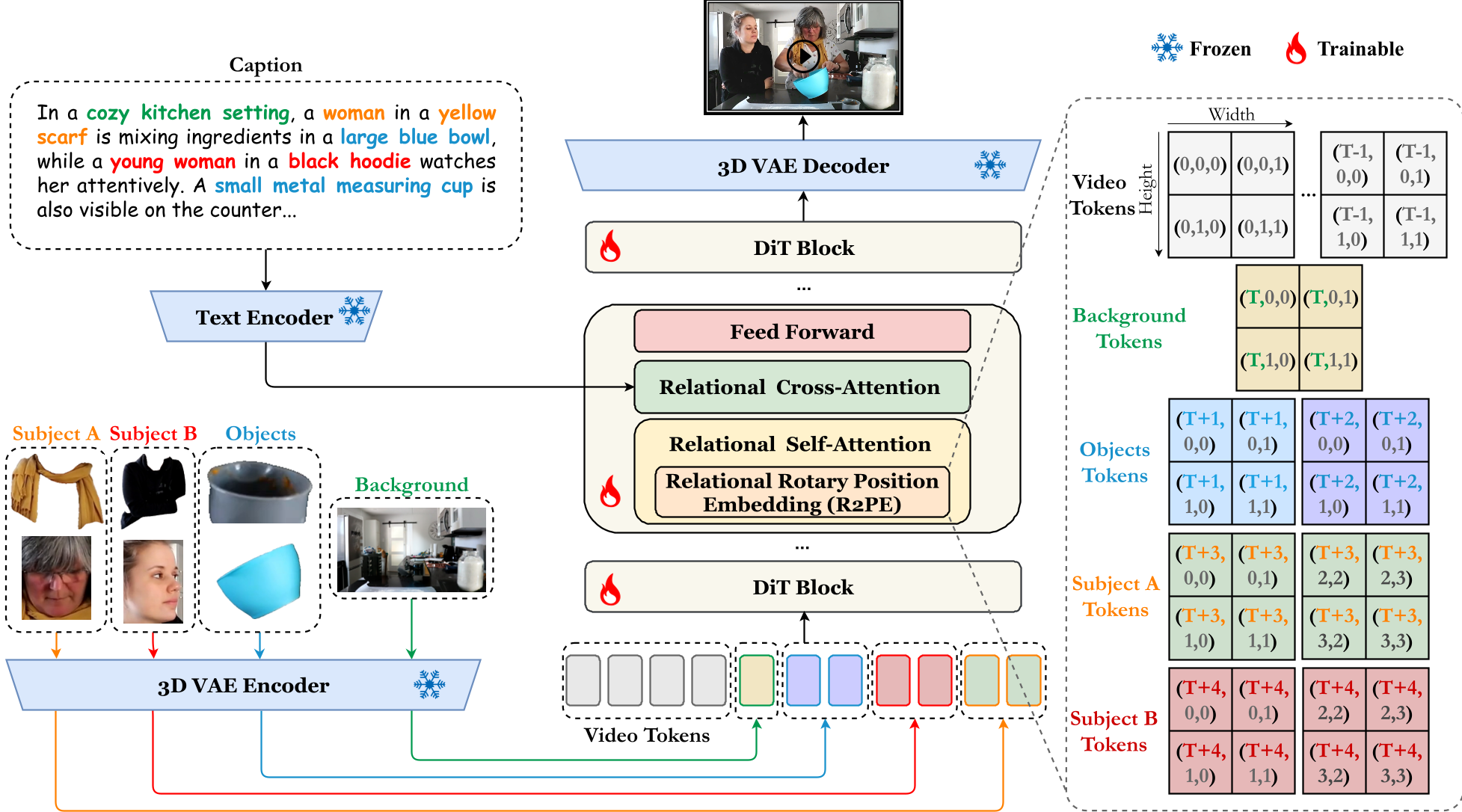
2. Relational Rotary Position Embedding (R2PE)
In a standard DiT, tokens are indexed sequentially. LumosX modifies 3D-RoPE so that a face and its attributes share the same "temporal index" (-index) and are grouped in the spatial manifold. This forces the model to realize these tokens belong to the same "entity" before any attention is even calculated.
3. Masked Attention (CSAM & MCAM)
The architecture introduces two specialized masks:
- Causal Self-Attention Mask (CSAM): Ensures that video denoising tokens can "see" the reference images (unidirectional attention), but condition images only interact within their own subject group.
- Multilevel Cross-Attention Mask (MCAM): A numerical mask that strengthens the bond between a visual subject and its corresponding text description, while suppressing interference from other subjects' descriptions.
Experiments: SOTA Performance
LumosX was tested against heavyweights like Phantom and SkyReels-A2. While competitors often struggle with "character confusion" in scenes with 2 or 3 people, LumosX maintains identity fidelity (ArcSim: 0.454 in 3-subject scenes, significantly outperforming baselines).

The ablation studies prove that the MCAM is the heavy hitter—setting the hyperparameter provides the optimal balance between keeping the face consistent and keeping the video quality high.
Critical Insight & Conclusion
LumosX proves that attention is not all you need—you also need structured attention. By moving away from "global" attention towards a more "hierarchical/relational" approach, LumosX paves the way for complex cinematic generation where multiple actors can interact without losing their unique visual identities.
The main limitation? It is currently capped by the base model's (Wan2.1-1.3B) inherent capacity. As the authors scale this to 14B+ models, we can expect "LumosX-Large" to potentially replace human editors for simple multi-actor scene assembly.