本文提出了 M2RNN (Matrix-to-Matrix RNN),一种采用矩阵值隐藏状态和非线性状态转移的非线性 RNN 架构。通过引入外积状态扩展机制和独立于状态的遗忘门,M2RNN 在 7B MoE 模型规模上超越了 Gated DeltaNet 等线性注意力 SOTA 方法。
TL;DR
伯克利、普林斯顿与 MIT 团队联合发布了 M2RNN (Matrix-to-Matrix RNN)。它证明了非线性 RNN 表现不佳并非因为“非线性”本身,而是因为“状态容量不足”。通过将隐藏状态矩阵化,M2RNN 不仅在 S3/S5 等硬核状态追踪测试中达成完美泛化,更在 7B 规模的语言建模中击败了 Mamba-2 和 Gated DeltaNet。
痛点深挖:为什么 Transformer 和线性 RNN 还不够?
在学术界,我们通常根据电路复杂度类(Circuit Complexity Classes)来衡量模型的“聪明程度”:
- TC0 级别:Transformer 和大多数线性 RNN(如矩阵化后的 SSM)都落在此类。它们擅长模式匹配,但在实体追踪(Entity Tracking)、代码执行逻辑、复杂状态置换等需要对数深度逻辑的任务上存在显著缺陷。
- NC1 级别:非线性 RNN(如传统的 GRU/LSTM)理论上具备更强的表达力,但现实很骨感:它们的向量状态容量太小,导致长文本记忆一塌糊涂,且在 GPU 上跑得极慢。
方法论:矩阵化状态的物理直觉
M2RNN 的核心公式非常优雅,它借鉴了线性注意力(Linear Attention)的“外积更新”思想,但引入了至关重要的非线性算子:
$$Z_t = anh(H_{t-1}W + k_t v_t^ op)$$ $$H_t = f_t H_{t-1} + (1 - f_t) Z_t$$
- 矩阵状态 ($H \in \mathbb{R}^{K imes V}$):不同于传统 RNN 的一维向量,矩阵状态极大地增加了存储“键-值”关联的插槽数量。
- 非线性转换 ($W$):$W$ 矩阵对状态进行混合。由于
tanh的存在,模型可以表达比线性累加复杂得多的逻辑转换。 - 硬件友好性:作者发现,利用外积扩展状态后,计算形状变得非常规则。在 NVIDIA GPU 上,这可以直接映射到 Tensor Core 的矩阵乘法单位,避免了像 FlashRNN 那样在小 Batch 下不得不进行 Padding 导致的算力浪费。
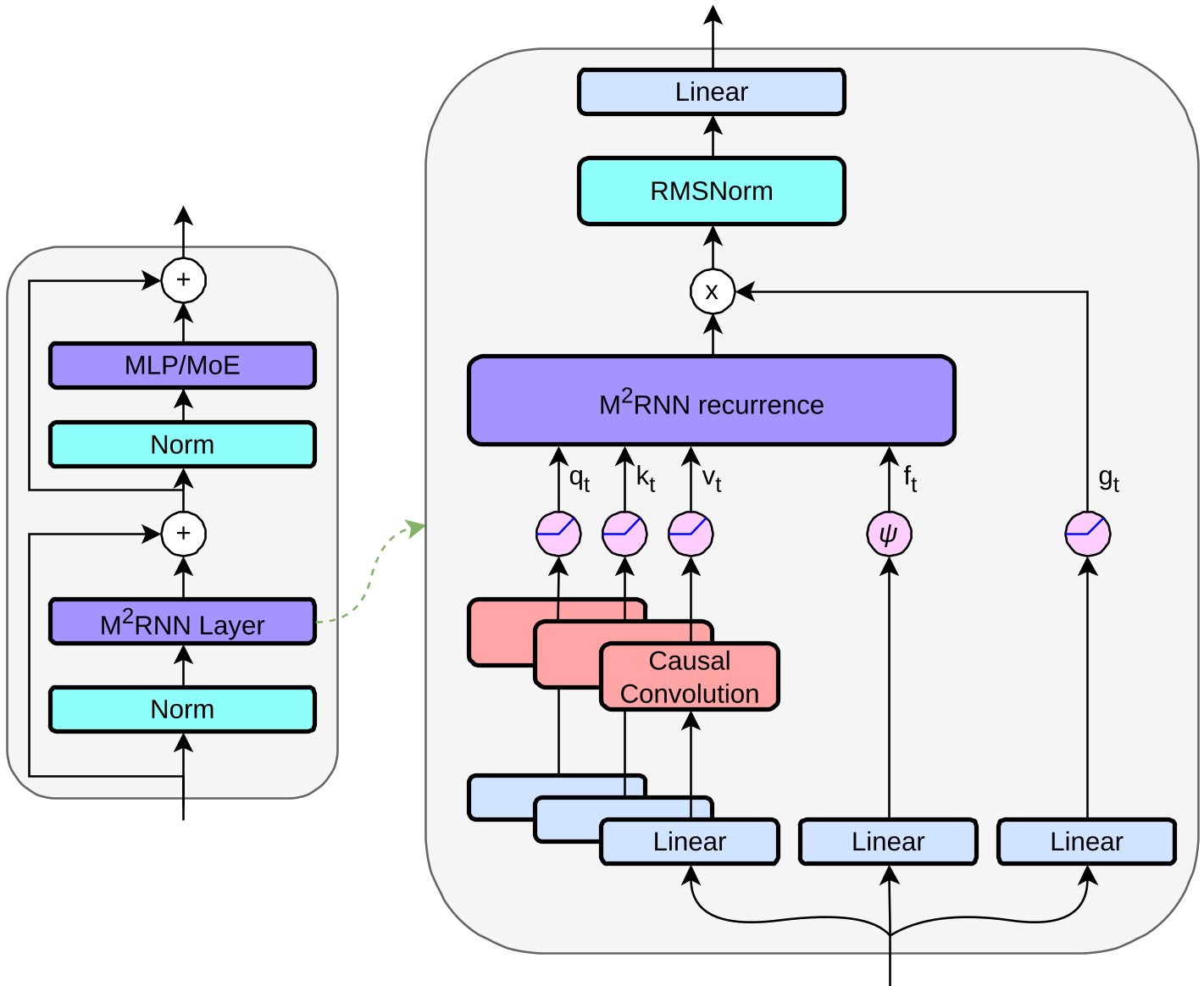 图 1:M2RNN 层架构图。该模块取代了传统的 Attention,并与 MLP 模块交替堆叠。
图 1:M2RNN 层架构图。该模块取代了传统的 Attention,并与 MLP 模块交替堆叠。
实验战绩:以少胜多
M2RNN 最惊人的发现之一是:你不需要让每一层都变成昂贵的非线性层。
- SOTA 混合建模:在使用 1 层 Attention + 7 层循环层的混合架构中,M2RNN 在 410M 和 7B (MoE) 尺度上均优于 Mamba-2。
- 长文本神迹:在 LongBench 测试中,将 Hybrid Gated DeltaNet 中的一层替换为 M2RNN,平均得分直接提升了 8 分。
- 训练速度:尽管非线性计算比线性操作慢,但通过 Triton 内核优化,M2RNN 混合架构的吞吐量损失控制在 6% 以内,这对于换取的精度提升来说极具性价比。
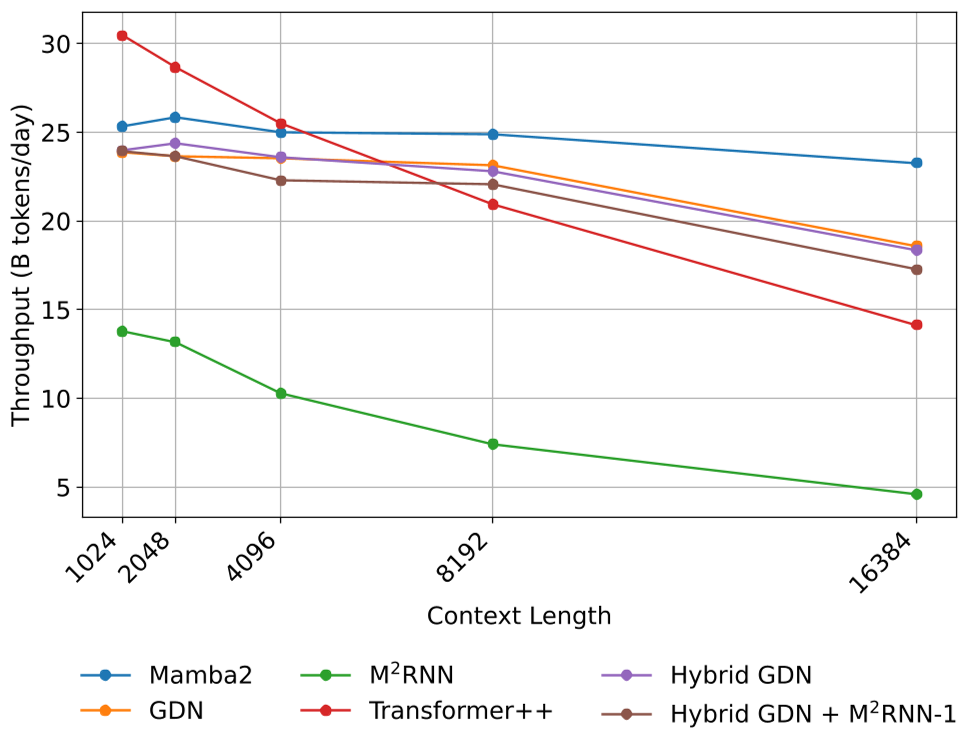 图 2:7B MoE 配置下的训练吞吐量测试。尽管 M2RNN 较慢,但在混合架构中其开销被大幅稀释。
图 2:7B MoE 配置下的训练吞吐量测试。尽管 M2RNN 较慢,但在混合架构中其开销被大幅稀释。
深度洞察:状态容量才是王道
作者通过消融实验揭示了一个被长期忽视的事实(见下表):
- 406M 的传统 RNN 困惑度高达 33.74。
- 410M 的 M2RNN 困惑度降至 22.92。 本质区别在于隐藏状态大小从 1,360 飙升到了 86,016。这说明之前的非线性 RNN 之所以输,不是输在算法,是输在了“内存条”不够大。

总结与展望
M2RNN 重燃了非线性 RNN 的研究热情。它告诉我们:通过合理的数学结构(矩阵化)和现代硬件加速技术(Triton/Flash 执行),我们可以找回被 Transformer 遗忘的逻辑表达力。
对于未来的 LLM 设计,M2RNN 给出了一个明确的信号:回归非线性循环,但必须带着大容量的矩阵状态回归。
局限性:由于 tanh 无法像线性模型那样通过 Parallel Scan 彻底并行化,在大 Batch 之外的长序列垂直扩展上仍面临挑战。