MAG-3D is a training-free multi-agent framework for grounded 3D reasoning that uses off-the-shelf Vision-Language Models (VLMs). It achieves SOTA performance on Beacon3D and MSQA benchmarks by coordinating planning, open-vocabulary grounding, and programmatic geometric verification.
TL;DR
MAG-3D is a breakthrough framework that enables standard Vision-Language Models (like GPT-4o or Seed-1.6) to reason about complex 3D scenes without any 3D-specific training. By delegating tasks to a specialized trio of Planning, Grounding, and Coding agents, it achieves new State-of-the-Art (SOTA) results on the Beacon3D and MSQA benchmarks, significantly reducing hallucinations and improving grounding-QA coherence.
Problem & Motivation: The Gap Between 2D Semantics and 3D Reality
While current VLMs are masters of 2D image recognition, they stumbling when faced with the 3D world. Answering a question like "What is to the left of the chair behind the table?" requires more than just semantic understanding; it requires:
- Precise Grounding: Identifying specific objects across multiple fragmented video frames.
- Geometric Consistency: Understanding that "left" and "behind" are relative to 3D poses, not just 2D pixels.
- Generalization: Adapting to new environments without needing thousands of labeled 3D examples.
Prior works either relied on expensive 3D instruction tuning (which fails in new domains) or rigid tools that couldn't handle the "messiness" of open-world queries.
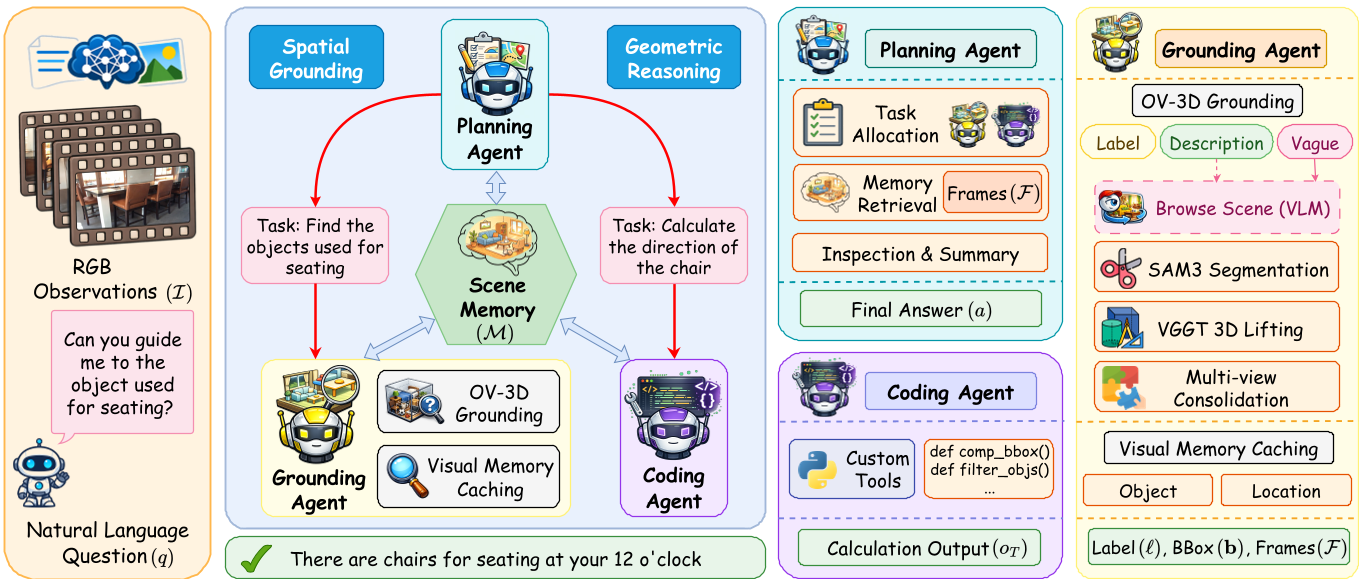
Methodology: The Multi-Agent Orchestration
The core innovation of MAG-3D is its agentic decomposition. Instead of one model trying to do everything, the process is split into three distinct roles:
1. The Planning Agent (The Brain)
The Planner acts as the coordinator. It breaks down a natural language query into sub-goals and decides which "expert" to call. If the evidence returned is ambiguous, the Planner can re-plan or re-invoke agents to "look closer."
2. The Grounding Agent (The Eyes)
This agent performs Open-Vocabulary 3D Grounding. It uses SAM3 for 2D segmentation and lifts these pixels into 3D space using VGGT (Visual Geometry Grounded Transformer). It maintains a 3D Visual Memory, storing 2D-3D correspondences that allow it to retrieve the most representative viewpoints of any given object.
3. The Coding Agent (The Calculator)
Geometric reasoning is notoriously hard for LLMs to do via text. MAG-3D's Coding Agent writes and executes Python code to perform spatial calculations (e.g., calculating the distance between two 3D boxes or determining relative orientations). This creates an explicit, verifiable reasoning chain.
Experiments & Results: Outperforming the Experts
MAG-3D was tested on two major benchmarks: Beacon3D and MSQA.
SOTA Performance Without Training
The results were striking. Even without any in-domain tuning, MAG-3D outperformed SceneCOT, a model specifically trained on 3D chain-of-thought data.
- Beacon3D: Achieved a Case-level QA score of 65.0, a significant leap over competitive baselines.
- Coherence: The framework showed a massive reduction in "Type-2" errors (getting the right answer for the wrong reason), indicating that its answers are truly grounded in scene geometry.

The Power of Visual Memory
In ablation studies, the authors found that their 3D-based visual memory was crucial. By selecting frames based on 3D volumetric coverage rather than just 2D mask size, the model could "see" through occlusions that traditionally confuse 2D models.

Critical Analysis & Takeaways
The success of MAG-3D highlights a shifting paradigm in AI: System 2 thinking for VLMs. Instead of relying solely on the intuitive, probabilistic "pattern matching" of a single transformer, MAG-3D implements a deliberate, iterative process of planning, perception, and verification.
Limitations: The system's performance is still tethered to the quality of the underlying 2D foundation models (SAM3, Seed-1.6). Furthermore, the multi-agent loop, while robust, introduces higher latency compared to single-pass end-to-end models.
Future Impact: MAG-3D paves the way for "automatic annotators." By using this framework to generate high-quality, grounded 3D reasoning data, researchers can bootstrap the training of smaller, faster end-to-end models for embodied robots.
Conclusion: MAG-3D proves that with the right orchestration, off-the-shelf VLMs are much more 3D-aware than we previously thought.