字节跳动团队推出的 Mamoda2.5 是一个统一的 AR–Diffusion 框架,通过引入细粒度 DiT-MoE (128专家,Top-8 路由) 设计,在单个架构中整合了多模态理解与生成。该模型拥有 25B 总参数量,但在推理时仅激活 3B 参数,不仅在视频编辑质量上创下新纪录,还显著降低了训练和推理成本。
TL;DR
字节跳动 Mamoda 团队发布的 Mamoda2.5 是一项里程碑式的工作。它通过 Fine-grained DiT-MoE 架构,成功在 25B 参数的规模下实现了极高的效率:仅需激活 3B 参数即可运行。更令人印象深刻的是,它将曾经极其缓慢的视频编辑任务加速了 95.9 倍,甚至在多个基准测试中击败了顶级的闭源模型 Kling O1。
背景:视频生成的“计算墙”
在视频生成领域,Scaling Laws 依然有效,但代价沉重。随着视频时长和分辨率的增加,Transformer 内部的 Full Attention 会产生巨大的开销。现有的 dense(稠密)架构在面对 10B 以上参数时,推理延迟往往会让实时应用变得遥不可及。Mamoda2.5 的核心使命就是:既要 Scaling 的质量,又要 Sparse 的速度。
核心方法:细粒度专家系统与极致蒸馏
1. 细粒度 DiT-MoE (The Scaling Engine)
不同于传统的粗粒度 MoE,Mamoda2.5 采用了 128 个路由专家。这种细粒度设计允许模型在固定的计算预算内,通过 Top-8 路由获得无穷的专家组合可能性(约 种组合)。
- Expert Bias 负载均衡:一种无损的平衡策略,通过动态偏置避免“热点专家”产生,提高设备利用率。
- Upcycling 策略:为了不从零开始训练,作者发明了随机神经元采样(Random Neuron Sampling),直接从 5B 的稠密预训练模型中“继承”知识到 25B 的 MoE 中,收敛速度提升了 5 倍。
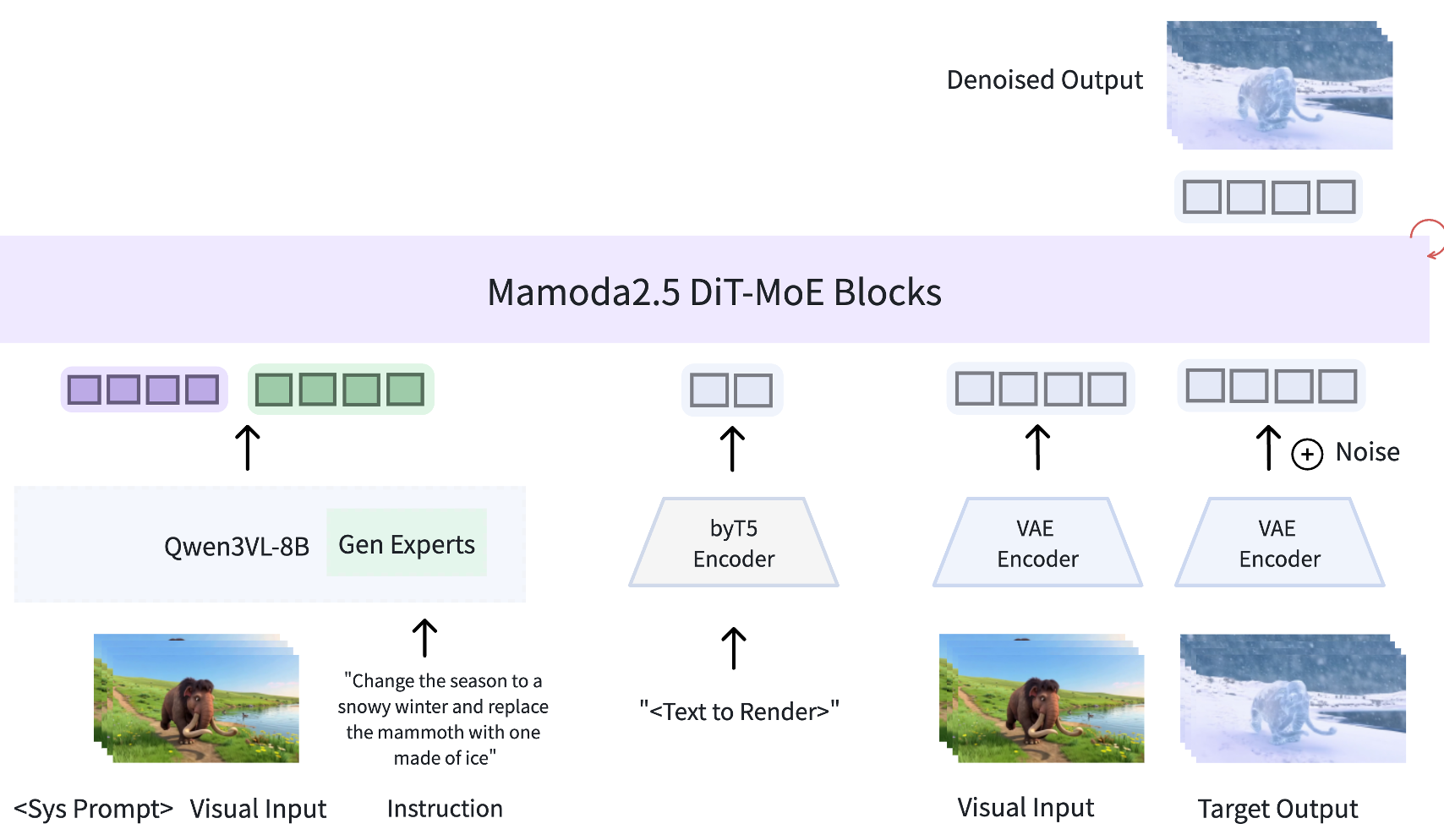 图 1: Mamoda2.5 整体架构,集成了 AR 理解模块与 DiT-MoE 生成模块。
图 1: Mamoda2.5 整体架构,集成了 AR 理解模块与 DiT-MoE 生成模块。
2. 联合蒸馏与 RL (The Inference Booster)
视频编辑通常需要 30-50 步的降噪,以及昂贵的 Classifier-Free Guidance (CFG)。 作者提出了 Joint Few-Step Distillation & RL:
- DMD (分布匹配蒸馏):将模型直接压缩到 4 步。
- DiffusionNFT (强化学习):利用美学、指令遵循和背景一致性等多个奖励函数进行训练。
- 奇迹发生:RL 训练后的 4 步学生模型,在编辑质量上竟然反超了 30 步的老师模型!
实验战绩:开源界的“编辑之王”
在视频编辑权威榜单 OpenVE-Bench 上,Mamoda2.5 斩获了 3.86 的高分,不仅横扫了所有开源模型(如 VInO, OmniVideo),甚至超过了知名的闭源模型 Kling O1 (3.69)。
 图 2: Mamoda2.5 与其他 SOTA 模型的推理速度与任务耗时对比。
图 2: Mamoda2.5 与其他 SOTA 模型的推理速度与任务耗时对比。
在实际视觉效果中,Mamoda2.5 表现出极强的空间推理能力(能够准确判断背包该挂在哪个肩膀上)和细节保留能力(在移除物体时不会弄乱背景纹理)。
工业应用:不只是学术纸面
Mamoda2.5 已经在字节跳动的广告业务中实战:
- 自动内容审核:评估视频广告的文字准确性和美学质量。
- 创意修复:通过自然语言指令,一键修复视频素材中的伪影或低分辨率区域。 其在内部广告视频编辑测试中达到了 98% 的成功率。
局限与未来
尽管 Mamoda2.5 在视觉上非常强大,但它目前还不支持音频同步生成。作者在展望中提到,未来的 Omni Audio-Video 模型将是下一个高地。
总结
Mamoda2.5 告诉我们:稀疏化(Sparsity)不是对性能的妥协,而是通往更大规模参数之路的唯一门票。 通过将 DiT 与细粒度 MoE 结合,视频生成的门槛被再次向下拉低了一大截。
关键词: #Mixture-of-Experts #VideoGeneration #DiffusionTransformer #ByteDance #DiT-MoE