本文提出了流形匹配自动编码器(MMAE),一种通过在隐空间和输入/参考空间之间对齐成对距离(Pairwise Distances)来实现非监督正则化的方法。该方法在不需要计算复杂的持久同调(Persistent Homology)的情况下,实现了 SOTA 级别的拓扑保持效果,并提供了可扩展的 MDS(多维尺度分析)近似。
TL;DR
在降维和表征学习中,如何让模型“记住”数据的原始形状(拓扑结构)一直是难题。传统的拓扑自动编码器(TopoAE)虽然效果好,但计算极其缓慢。本文提出的 Manifold-Matching Autoencoders (MMAE) 另辟蹊径:它不计算复杂的数学拓扑指标,而是通过简单的成对距离对齐(Pairwise Distance Matching),以极低的计算开销达成了甚至超越拓扑算法的结构保持效果。
痛点深挖:拓扑保护的“高昂代价”
在深度学习中,虽然 Autoencoder 可以压缩数据,但它往往是“不讲道理”的。例如,在原始空间中嵌套在一起的球体,压缩到 2D 隐空间后可能会被拆散或颠倒。
为了解决这一问题,前人提出了基于**持久同调(Persistent Homology)**的方法。虽然理论完美,但它们存在两大致命伤:
- 不可扩展性:计算持久同调的成本随 Batch Size 剧增,导致模型只能在小 Batch 下训练。
- 不连续性:微小的点位偏移可能导致最小生成树(MST)发生剧变,使得梯度下降变得不稳定。
核心直觉:距离保持即拓扑保持
MMAE 的核心 Insight 建立在一个强大的数学推论上:如果一个变换能保持点与点之间的 Euclidean 距离,那么它必然能保持数据的拓扑性质(如连通性、环洞数量等)。
这意味着,我们不需要去显式地计算什么“拓扑特征”,只需要让隐空间 的距离矩阵 尽量贴合输入空间 (或其 PCA 降维后的参考空间 )的距离矩阵 即可。
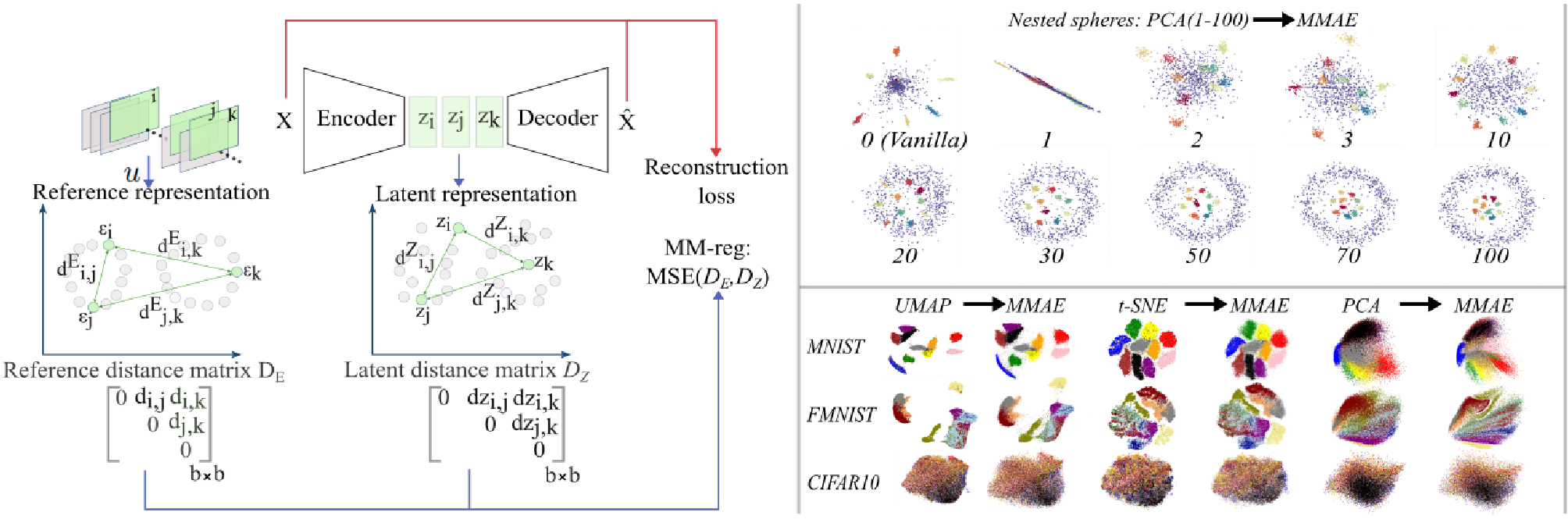 图 1:左侧为 MMAE 架构,右侧展示了它在 Nested Spheres 任务中完美恢复了嵌套结构。
图 1:左侧为 MMAE 架构,右侧展示了它在 Nested Spheres 任务中完美恢复了嵌套结构。
方法论详解:Manifold-Matching
MMAE 的目标函数非常纯粹:
两个关键点:
- 参考空间(Reference Space)的选择: 在处理高维噪声数据(如 single-cell RNA 数据)时,直接使用原始空间距离会受“维度灾难”影响。MMAE 允许使用 PCA 降维后的空间作为参考,既过滤了噪声,又保留了全局几何。
- Batch-wise 优化: 虽然经典的 MDS 也做距离对齐,但它需要计算 的全量矩阵,显存吃不消。MMAE 将其转化为 Batch 级别的 MSE 损失,使其能够利用标准的随机梯度下降(SGD)进行大规模扩展。
实验结果:速度与质量的双重碾压
作者在合成数据集(Linked Tori, Earth)和真实数据集(MNIST, CIFAR10, 生态细胞数据)上进行了全面评测。
 图 2:在 2D 隐空间中,MMAE(图 b)展现了比其他几何方法(如图 e, f)更严谨的比例保持能力。
图 2:在 2D 隐空间中,MMAE(图 b)展现了比其他几何方法(如图 e, f)更严谨的比例保持能力。
核心发现:
- 计算效率:图 3 显示,MMAE 的训练时间几乎与 Vanilla AE 持平,而 RTD-AE 在 Batch Size 达到 80 后便不可用。
- 拓扑保真度:在最重要的拓扑指标 (Wasserstein distance on persistence diagrams)上,MMAE 甚至优于一些专门为拓扑设计的模型,这印证了“距离对齐”的强大威力。
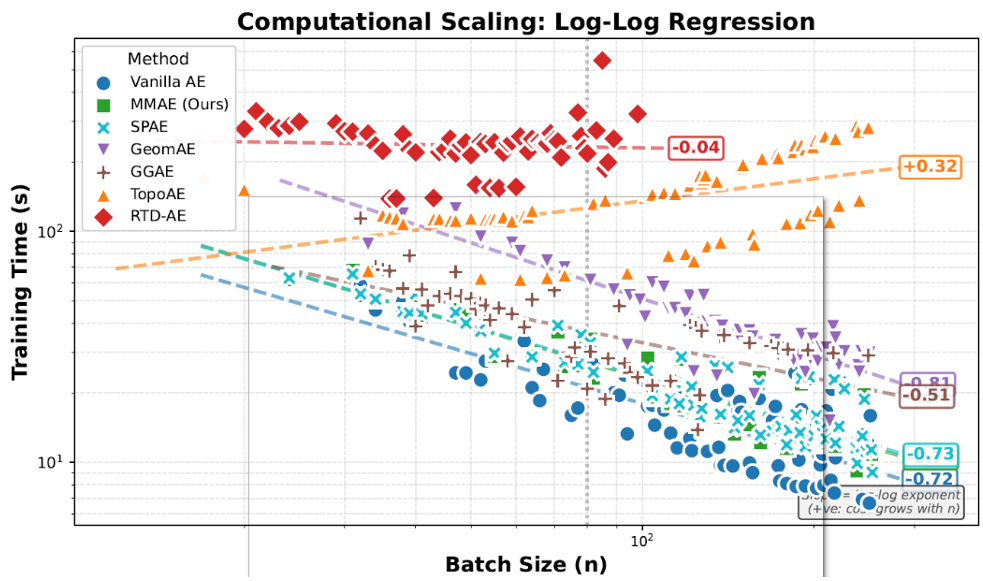 图 3:MMAE 与各 baseline 的训练时间随 Batch Size 变化曲线。
图 3:MMAE 与各 baseline 的训练时间随 Batch Size 变化曲线。
深度总结与未来展望
MMAE 的成功在于它化繁为简。它告诉我们,与其追求复杂的拓扑闭式解,不如回归几何直觉。
局限性:MMAE 倾向于“对齐”而非“展开”。如果原始流形本身极其扭曲,简单的距离对齐可能无法像 UMAP 那样将其完全摊平。
未来启示:这一方法可以轻易扩展到生成模型(如 VAE / Diffusion)的隐空间正则化中。在需要保持数据全局结构的科学计算、生物信息学领域,MMAE 提供了一个高性能、高保真的新工具箱。