本文推出了 ManiTwin,一个自动化的大规模机器人操作数字孪生资源生成管线,并发布了包含 10 万个高质量 3D 资源的 ManiTwin-100K 数据集。该工作实现了从单张图像到具备语义标注、物理属性和碰撞验证的仿真就绪(Simulation-ready)资源的自动化转化,显著提升了机器人学习的数据规模。
TL;DR
在机器人操作领域,高质量的仿真环境资产一直是限制策略泛化的“窄门”。本文提出的 ManiTwin 建立了一套全自动化的数字孪生生成管线,仅需单张图片即可生成具备物理参数、功能语义和仿真验证的 3D 模型。利用该工具,作者构建了 ManiTwin-100K 数据集,提供了 10 万个可直接用于操作训练的资源,为机器人通用策略学习构筑了坚实的“数据粮仓”。
背景定位:从“几何多样性”迈向“操作就绪”
当前的 3D 资源库正处于一个尴尬的境地:Objaverse 等数据集虽然大,却只能看不能“玩”(缺乏物理属性和交互逻辑);而像 YCB 这样能“玩”的,规模又太小(仅几十个物体)。
ManiTwin 的核心动机在于填补这两者之间的空白——构建一个既具备海量规模,又拥有严谨物理校验和丰富语义标注的机器人操纵中心化数据集。
核心方法论:ManiTwin 的三阶跃迁
ManiTwin 的管线分为:资产生成 (Asset Generation)、语义标注 (Asset Annotation) 与物理验证 (Verification)。
1. 资产生成:从 2D 到 3D 仿真就绪
管线首先利用生成模型(如 CLAY)从输入图像提取几何结构,并通过 VLM(Vision-Language Model)对多视图渲染图进行推理,估计物体的定向边界框(OBB)、质量、表面摩擦力等关键物理参数。
2. 语义标注:赋予物体“灵魂”
不同于传统的全自动抓取采样,ManiTwin 引入了 VLM 引导的深度标注:
- Functional Points:识别物体的功能区(如水壶的嘴、刀的刃、按钮等)。
- Grasp Proposals:利用 GraspGen 生成密集的抓取位姿,并根据 VLM 识别的语义点进行空间过滤。
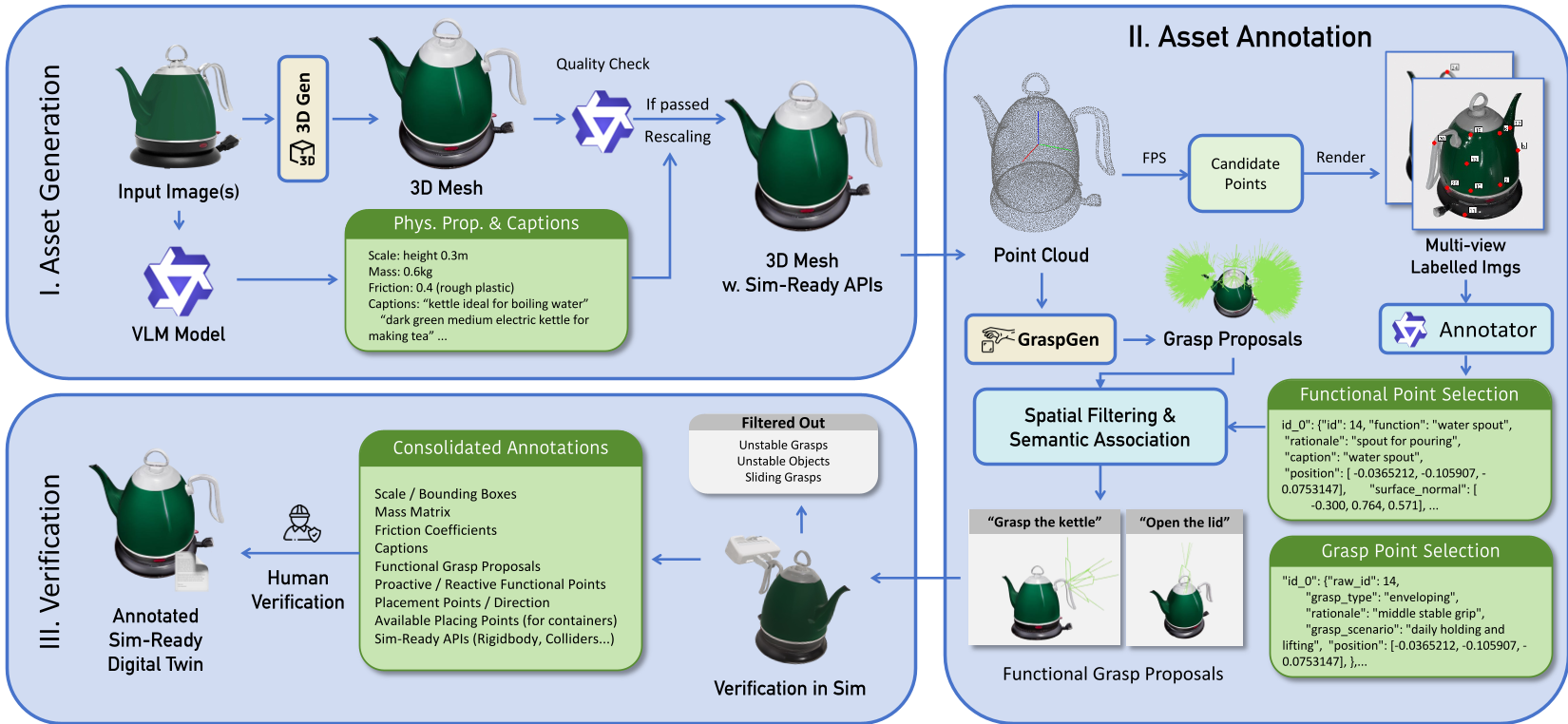 Figure 1: ManiTwin 自动化管线概览
Figure 1: ManiTwin 自动化管线概览
3. 物理验证:仿真器内的“终极炼金计划”
这是 ManiTwin 区别于其他生成工作的关键环节。每一个抓取候选位姿都会在 SAPIEN/PhysX 仿真器中进行严格测试:
- 稳定性验证:夹爪闭合后能否稳定提起物体而不滑落。
- 抗滑移测试:沿正交方向移动物体,确保位姿具有足够的鲁棒性。
实验与结果:10 万资产的震撼力量
ManiTwin-100K 统计特征
该数据集涵盖了从厨房用具到工业工具的 512 个类别,支持跨具身(Cross-Embodiment)的数据生成。这意味着同一个物体的标注可以同时驱动平行夹爪、灵巧手或自定义末端执行器。
质量评估
- 标注准确率:VLM 在类别分类上达到 100% 精度,在功能点识别上达到 92.2%。
- 抓取规模:累计产生 500 万个验证后的抓取位姿,生成的操纵轨迹长达 1000 万条。
 Figure 2: ManiTwin-100K 示例资产展示,从左至右依次为原图、生成模型、网格几何与抓取语义
Figure 2: ManiTwin-100K 示例资产展示,从左至右依次为原图、生成模型、网格几何与抓取语义
深度洞察与总结
为什么 ManiTwin 如此重要?
ManiTwin 的出现预示着机器人学习正在进入“基础模型”时代。过去我们需要人工为每个任务编写代码或示教,而现在我们可以:
- 自动生成任务:根据 functional points 自动组合指令(如“拿起水壶把手并对准杯口”)。
- VQA 数据生成:基于语义标注自动合成百万级的机器人视觉问答数据,训练具备推理能力的具身大模型。
局限性与未来
目前的资源仍集中在**刚性(Rigid)**物体,尚未触及具有关节的(Articulated,如抽屉)或可变形的(Deformable,如绳子)资产。此外,物理参数目前通过视觉推理而非真值测量。
总结:ManiTwin 为机器人社区提供了一个规模化解决 Assets Gap(资源鸿沟)的范式。通过自动化的“生成+验证”闭环,它让“为每一个机器人任务提供无限训练数据”的目标变得触手可及。