The paper introduces MCLR (Maximum Inter-Class Likelihood-Ratio), a training-time alignment objective designed to enhance class-specificity in visual generative models (Diffusion and Autoregressive). It achieves performance comparable to Classifier-Free Guidance (CFG) without requiring additional inference-time computation, establishing SOTA results for guidance-free generation on ImageNet-512.
TL;DR
Researchers from the University of Michigan have solved a long-standing mystery in generative AI: Why is Classifier-Free Guidance (CFG) so effective yet theoretically disconnected from training? They introduce MCLR (Maximum Inter-Class Likelihood-Ratio), a training objective that forces models to distinguish classes more sharply. Most importantly, they prove that CFG is essentially a "lazy" version of their alignment objective performed at inference time. Using MCLR, you can get CFG-quality images at 2x the speed because no dual-score sampling is required.
The Problem: The "Inter-Class Leakage" Tax
If you've ever run a Diffusion model without CFG, you know the results are often "muddy"—the model understands the general layout but fails to commit to class-specific features. This is because standard Denoising Score Matching (DSM) doesn't explicitly penalize the model for confusing "Golden Retrievers" with "Labradors."
To fix this, we've historically paid the CFG Tax: calculating both a conditional and unconditional score at every single step of inference.
Methodology: The Alignment Insight
The authors propose that instead of fixing the trajectory at inference, we should align the model during training. MCLR adds a simple but powerful regularization term:
$$ \max_{ heta} \mathbb{E} \left[ \log \frac{p_{ heta}(x|c)}{p_{ heta}(x| ilde{c})} \right] $$
This forces the model to maximize the gap between the likelihood of the correct class ($c$) and a random mismatched class ($ ilde{c}$).
The Unified Framework
The core contribution is the "Mechanistic Interpretation." The authors prove that the standard CFG formula is actually the gradient of a weighted version of the MCLR objective. This places CFG on the same theoretical footing as Direct Preference Optimization (DPO) used to align LLMs like GPT-4.
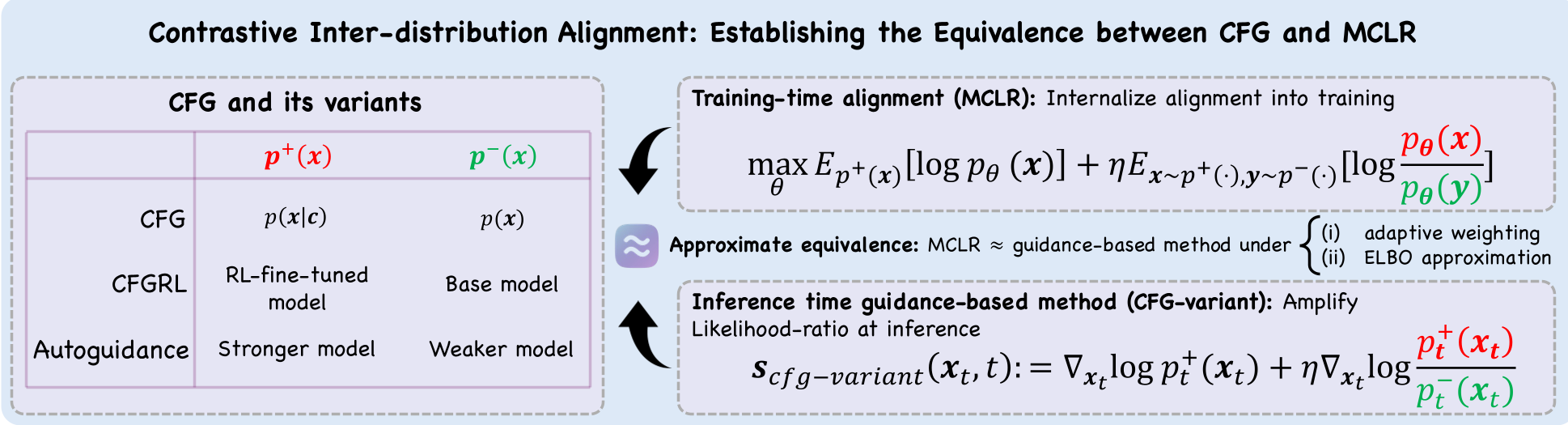 Figure 1: MCLR provides a unified interpretation, connecting various guidance methods (Autoguidance, DPO, CFG) to contrastive alignment.
Figure 1: MCLR provides a unified interpretation, connecting various guidance methods (Autoguidance, DPO, CFG) to contrastive alignment.
Experimental Battleground: MCLR vs. The World
The authors tested MCLR on ImageNet-64 (EDM2-S), ImageNet-256 (VAR), and ImageNet-512 (EDM2-L).
1. Qualitative Purity
As shown in the emergence visualization, MCLR training mirrors the effect of increasing CFG scale. It sharpens features and separates class identities progressively without the artifacts (like over-saturation) often seen when CFG scales are set too high.
 Figure 2: Visualizing the progressive emergence of class-specific structures under MCLR fine-tuning.
Figure 2: Visualizing the progressive emergence of class-specific structures under MCLR fine-tuning.
2. Quantitative SOTA
MCLR doesn't just match CFG; it out-optimizes previous alignment methods like CCA (Conditional Contrastive Alignment) and DDO.
| Method | Model | FD_DINOv2 (Lower is better) | Precision | | :--- | :--- | :--- | :--- | | Base Model | EDM2-L | 67.70 | 0.753 | | + CFG (Inference) | EDM2-L | 39.86 | 0.844 | | + MCLR (Training) | EDM2-L | 42.50 | 0.849 | | + CC-DPO | EDM2-L | 51.92 | 0.812 |
While CFG still holds a slight edge in distributional distance (FD), MCLR actually achieves higher Precision, meaning the images it generates are more faithful to the target class and visually "cleaner."
Deep Insight: Why not just use DPO?
The paper compares MCLR to CC-DPO (a conditional adaptation of Direct Preference Optimization). They found that while DPO works, it uses a multiplicative "gamma-powered" reweighting that can be unstable if the probability of a class is near zero. MCLR's additive density modification is more robust, resulting in smoother training and better convergence on high-resolution ImageNet-512 tasks.
Conclusion and Future Outlook
MCLR marks a shift in how we think about "Guidance." We are moving from a world of Inference-Time Control to Training-Time Alignment.
Key Takeaways for Practitioners:
- Speed: If you are deploying models at scale, MCLR lets you drop the unconditional branch, doubling your throughput.
- Stability: MCLR avoids the "oversaturation" artifacts common in CFG.
- Theory: We now know that aligning a model for class-specifity is mathematically equivalent to the guidance tricks we've used for years.
The next frontier? Applying MCLR to text-to-video and 3D generation, where the "CFG Tax" is even more expensive.