[NeurIPS 2025] MDM-Prime-v2: Is the Autoregressive Era Over? Diffusion Models Finally Win the Efficiency Race
MDM-Prime-v2 is an advanced Masked Diffusion Model (MDM) for language modeling that introduces Binary Encoding and Index Shuffling to optimize sub-token granularity. The model achieves a state-of-the-art perplexity of 7.77 on OpenWebText, significantly outperforms Autoregressive Models (ARM) in compute-optimal settings, and demonstrates superior zero-shot performance at the 1.1B parameter scale.
TL;DR
For years, the "Efficiency Gap" was the Achilles' heel of Diffusion Language Models, making them up to 16x more expensive to train than standard Autoregressive Models (ARMs). MDM-Prime-v2 flips the script. By refining how tokens are broken into sub-tokens (Binary Encoding) and shuffling their indices to maximize entropy, this model is 21.8x more compute-efficient than ARMs and delivers significantly better perplexity and zero-shot reasoning at scale.
The Core Friction: Why Diffusion Models Struggled
The dominance of ARMs (like GPT-4 or Llama) is largely due to their "compute-optimal" scaling—they get better very predictably as you add more FLOPs. Masked Diffusion Models (MDMs), which predict masked tokens in any order, were theoretically interesting but practically "slow" learners.
The authors of MDM-Prime-v2 identified that the problem wasn't the diffusion process itself, but the Subtokenizer. Specifically:
- Granularity Chaos: There was no principled way to decide how many sub-tokens a word should be broken into.
- The BPE Trap: Standard Byte-Pair Encoding (BPE) creates a highly structured distribution where common tokens have small indices. When converted to binary, this structure creates "low entropy" patterns that the diffusion model finds hard to reconstruct.
Methodology: Tightening the Bound
The researchers attacked these issues using the math of Variational Bounds ().
1. Technique 1: Binary Encoding
The authors proved that the variational bound is monotonically non-increasing as token granularity () increases. To get the tightest possible bound, they moved to Binary Encoding (). This provides the most fine-grained denoising process possible within the MDM framework.
2. Technique 2: Index Shuffling
To solve the "BPE Trap," the authors introduced Index Shuffling. By randomly scrambling the lookup table of token indices before converting them to binary sub-tokens, they maximized the entropy of the latent states.
Physical Intuition: If specific sub-token values are always associated with high-frequency BPE tokens, the model gets "lazy." Shuffling forces the model to learn a more certain predictive distribution for every bit of information.
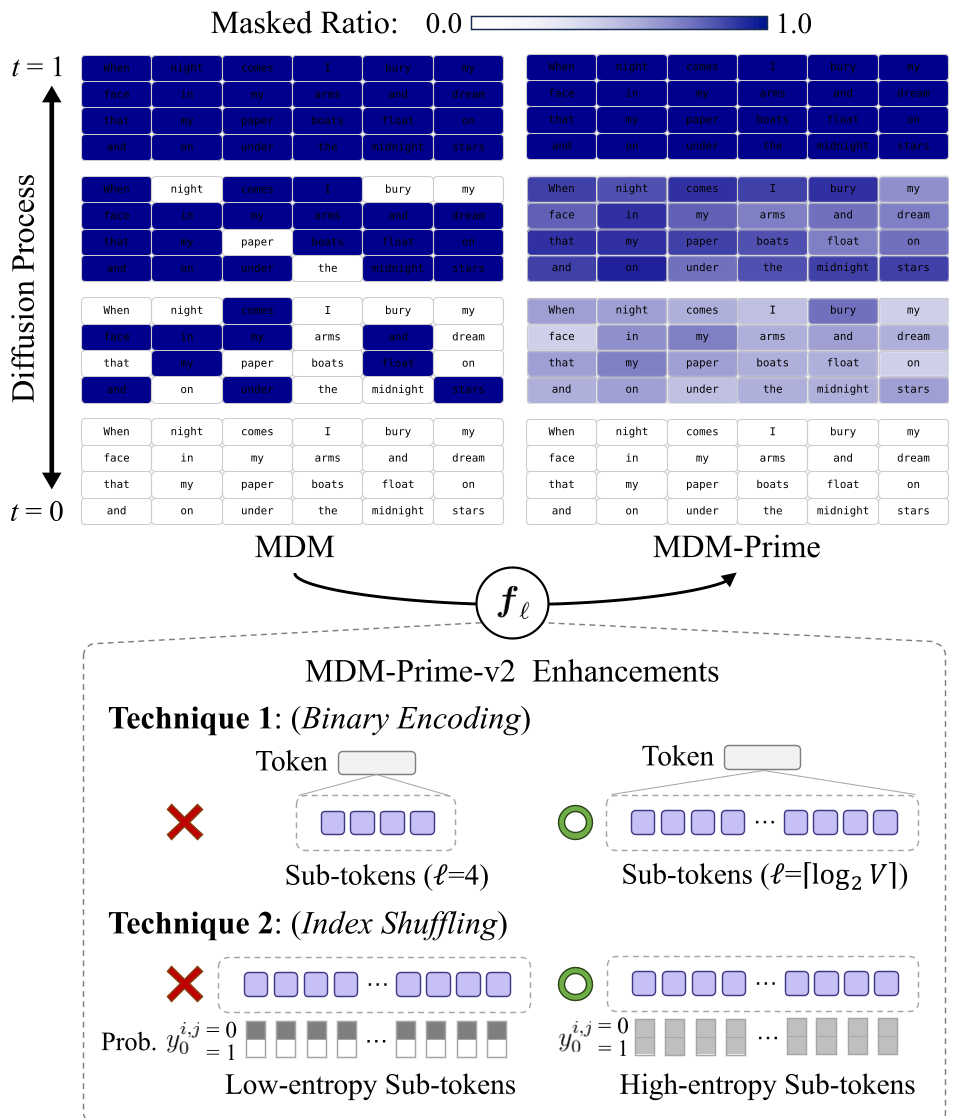 Figure 1: Comparison of standard MDM vs MDM-Prime-v2 with Index Shuffling.
Figure 1: Comparison of standard MDM vs MDM-Prime-v2 with Index Shuffling.
Scalability: The 21.8x Breakthrough
The most striking part of this paper is the scaling analysis. Utilizing the "Chinchilla" scaling law protocol, the authors compared ARM, MDM, and MDM-Prime-v2 across different compute budgets ( to FLOPs).
- Efficiency: MDM-Prime-v2 is approximately 21.8x more efficient than ARM.
- Optimal Allocation: Unlike ARMs, which prioritize model size (), MDM-Prime-v2 scales better by spending more compute on the number of training tokens ().
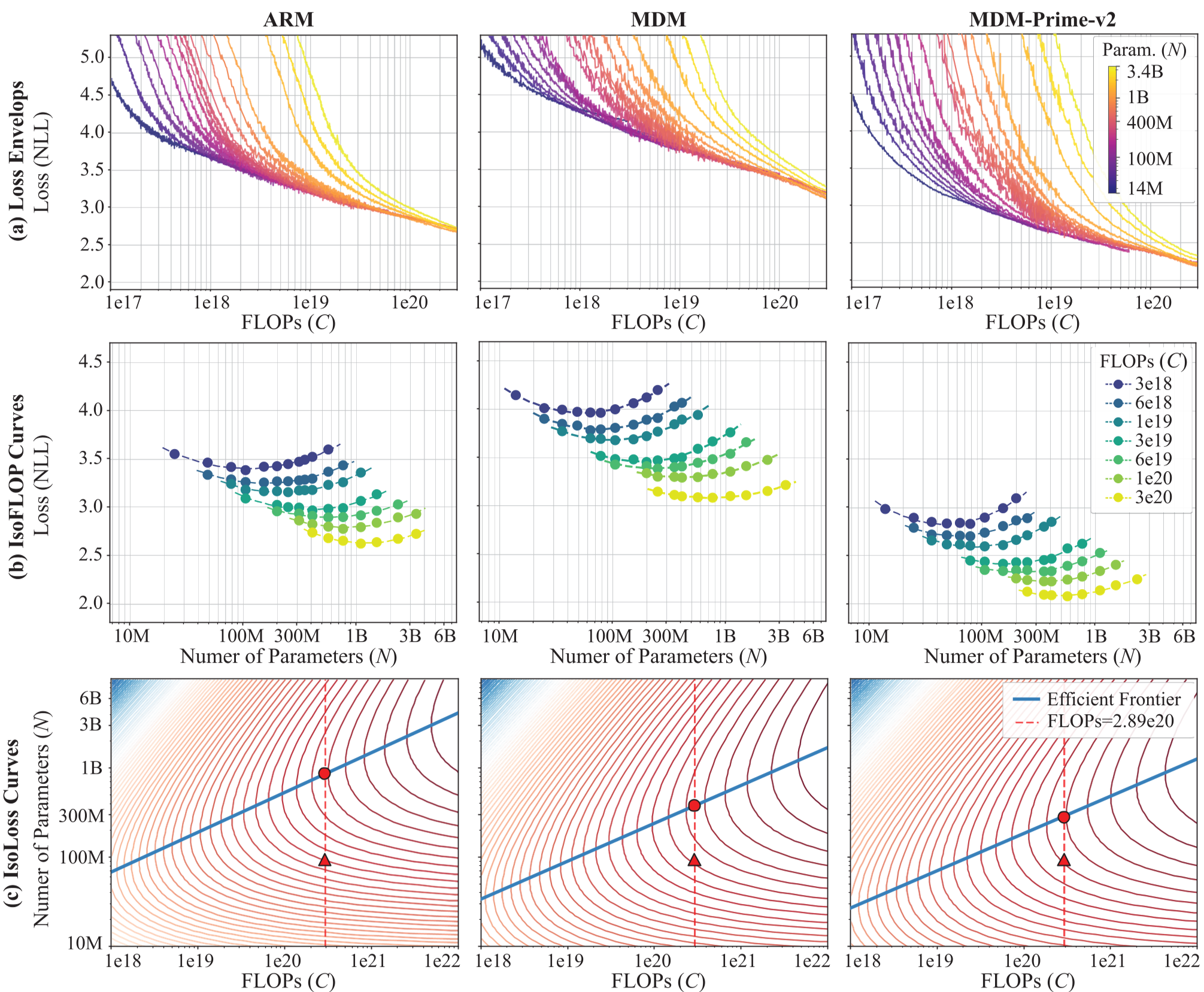 Figure 5: IsoFLOP and Isoloss curves showing MDM-Prime-v2 (blue) far ahead of the ARM frontier.
Figure 5: IsoFLOP and Isoloss curves showing MDM-Prime-v2 (blue) far ahead of the ARM frontier.
Spectral Insights: Why it works
Beyond the loss curves, the authors performed a Spectral Analysis of the weight matrices.
- Rank Collapse Prevention: MDM-Prime-v2 showed a heavier-tailed singular value distribution in its attention layers.
- Diverse Routing: While standard MDMs often suffer from "Attention Sinks" (wasting capacity on a few tokens), MDM-Prime-v2 exhibits sharp diagonal attention patterns, indicating it has learned specialized routing for data.
Experiments & Results
In a "Compute-Optimal" showdown on OpenWebText:
- MDM-Prime-v2: 7.77 PPL
- ARM: 12.99 PPL
- MDM: 18.94 PPL
At the 1.1B parameter scale, pre-trained on 540B tokens (SlimPajama), MDM-Prime-v2 beat TinyLLaMA on 6 out of 8 commonsense reasoning tasks, particularly excelling in temporal and scientific reasoning (e.g., McTaco and SciQ).
Critical Analysis & Future Outlook
Is this the end of the ARM? Not quite yet. While MDM-Prime-v2 wins on pre-training efficiency and order-agnostic flexibility, the paper notes a limitation: Inter-token dependencies. The model currently assumes tokens are conditionally independent during certain diffusion steps, which causes some degradation as the mask ratio approaches 100%.
However, the industry value is clear: For teams looking for the next generation of scalable, non-autoregressive models (which are better for parallel editing, filling-in-the-middle, and potentially faster sampling), MDM-Prime-v2 provides the first mathematically sound blueprint to beat the Transformer's efficiency at its own game.
Conclusion
MDM-Prime-v2 proves that the "Diffusion Gap" wasn't a flaw in the diffusion logic, but a bottleneck in information encoding. By treating bits as the fundamental unit of denoising and ensuring high entropy via shuffling, we finally have a viable alternative to the autoregressive status quo.