本文推出了 MedSPOT,这是首个针对临床医疗 GUI 环境的工作流感知顺序定位(Sequential Grounding)基准测试。该基准涵盖 10 个医疗软件平台、216 个任务视频及 597 个关键帧标注,旨在评估多模态大模型(MLLM)在复杂、具有因果依赖的医疗操作流中的定位精度。
TL;DR
在医疗数字化转型中,辅助医生操作复杂的 DICOM 阅片系统是 AI 的核心愿景。然而,目前的 MLLMs 是否真的准备好了?MedSPOT 告诉我们:差得远。该基准展示了通用模型在处理具有因果依赖的医疗工作流时,任务完成率几乎全线跌破 10%,揭示了当前模型在“空间精度”和“推理持久性”上的致命缺陷。
背景定位:从“看图说话”到“精准手术”
目前的 GUI 智能体(GUI Agents)研究大多停留在网页点餐、订票等通用场景。但在医疗领域,操作 RadiAnt 或 3D Slicer 这种专业软件就像在驾驶舱内执行指令:UI 元素密集、图标语义高度专业。以往的基准测试通过评估单步点击是否准确来给模型发奖状,但这掩盖了一个残酷事实:在这一连串的操作中,第一步点歪了,后面全白费。
痛点深挖:为何医疗 GUI 这么难?
作者指出,医疗 GUI 存在以下三大挑战:
- 空间量化误差:Vision Transformer 将图像切成 Patch,很多医疗小图标甚至还没一个 Patch 大(Small Target),模型根本“看”不准。
- 顺序传播错误:一个典型的阅片任务包含“加载、调整窗位、测量、导出”三五个步骤,各步高度耦合。
- 表征 mismatch:LLM 用离散的文本符号(Token)去预测连续的坐标点,这种间接映射在精细操作下非常不稳定。
核心方法:MedSPOT 带来的“严刑峻法”
1. 工作流感知的建模
MedSPOT 不再让模型回答“导出按钮在哪”,而是模拟真实场景:
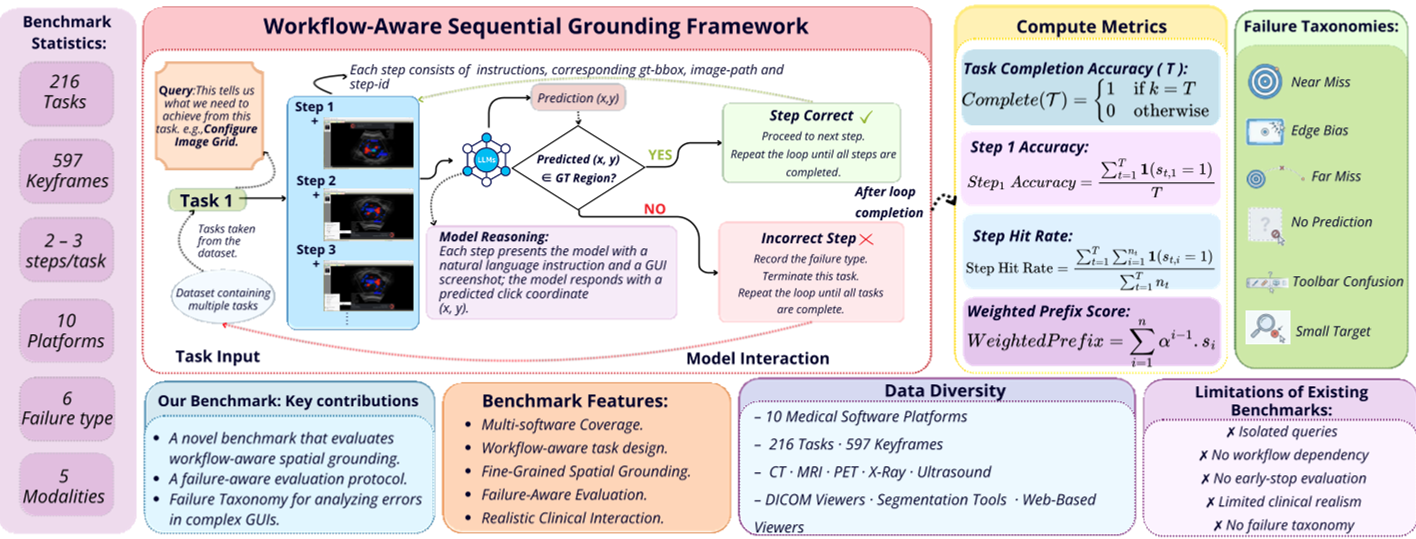 模型必须根据当前帧 、指令 和之前的历史 给出坐标。
模型必须根据当前帧 、指令 和之前的历史 给出坐标。
2. 早期停止协议 (Early Termination)
这是本文最“毒辣”的设计。如果任务共有 3 步,即使你第 2、3 步都对,只要第 1 步没点准,整个任务得分就是 0。这迫使模型必须保持长程的稳定性。
3. 失败分类学 (Failure Taxonomy)
作者系统归纳了 6 种死法:
- Toolbar Confusion:由于工具栏长得都差不多,模型点到了全局工具栏而不是工作区。
- Edge Bias:模型由于预训练偏差,喜欢往屏幕边缘点。
- Near Miss:点得非常近,但没进框。这反映了空间分辨率的瓶颈。
实验与结果:全军覆没的通用模型
在该榜单上,像 GPT-4o-mini, Llama 3.2 Vision 这种大名鼎鼎的模型在任务完成率(TCA)上几乎都是 0%。

关键发现:
- 专用胜过通用:只有针对 GUI 专门微调过的模型(如 GUI-Actor, UI-TARS)才能维持基本的执行逻辑,但也仅能达到 30%-40% 的完成率。
- 精度断崖:从单步准确率(S1A)到任务完成率(TCA),所有模型都出现了巨大的断崖式下跌,验证了错误在步骤间传播的破坏力。
深度洞察:AI 代理的未来在哪?
即便在相对“简单”的 ITK-SNAP 软件中,模型的表现也远未达到临床安全标准。
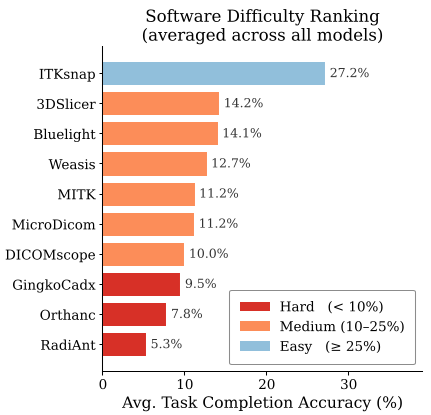
总结与局限性: MedSPOT 成功指出了 MLLM 在严肃软件场景下的无力感。虽然目前仅支持“点击(Click)”操作,未包含拖拽(Drag)和输入,但其严格的评估协议为医疗 AI 代理的安全性树立了标杆。
给读者的启示: 如果你正在开发垂直行业的 AI Agent,不要只看 Benchmarks 里的单跳准确率,去关注那些真正具有因果链条的顺序任务(Sequential Tasks),那才是模型真正崩溃的地方。