MegaStyle introduces a scalable data curation pipeline that leverages the consistent text-to-image (T2I) mapping of large generative models to create a high-quality style dataset. The authors release MegaStyle-1.4M, a massive dataset of style-consistent pairs, alongside MegaStyle-Encoder for style representation and MegaStyle-FLUX for generalizable style transfer.
TL;DR
MegaStyle addresses the long-standing "content leakage" and inconsistency issues in image style transfer by shifting from self-supervised learning to paired supervision. The authors leverage the innate ability of large T2I models (like Qwen-Image) to map a single text description to a consistent visual style across multiple contents. This results in MegaStyle-1.4M, a dataset that enables state-of-the-art style encoding and transfer models.
Problem & Motivation: The Consistency Gap
Why is style transfer still hard? Most current SOTA models use CLIP-based encoders. However, CLIP's latent space is primarily semantic, not stylistic. When you ask a model to "copy" the style of an image, it often captures the objects in that image too—this is known as content leakage.
Furthermore, existing datasets like WikiArt are biased: an artist's "style" actually changes over time or by subject matter. The authors argue that we need intra-style consistency and inter-style diversity. If we can't find these "perfect pairs" (same style, different content) in the wild, we must curate them synthetically.
Methodology: The MegaStyle Pipeline
The core innovation lies in the Consistent T2I Style Mapping. Instead of using traditional style transfer to create data (which is often low quality), they use a VLM to generate highly detailed style "recipes."
- Style Captioning: Using Qwen3-VL to describe color, light, medium, texture, and brushwork while ignoring objects.
- Content Captioning: Describing only the objects and relationships, ignoring aesthetics.
- Generation: Combining a single style prompt with multiple content prompts to generate "style pairs" that are perfectly aligned in aesthetic but distinct in structure.
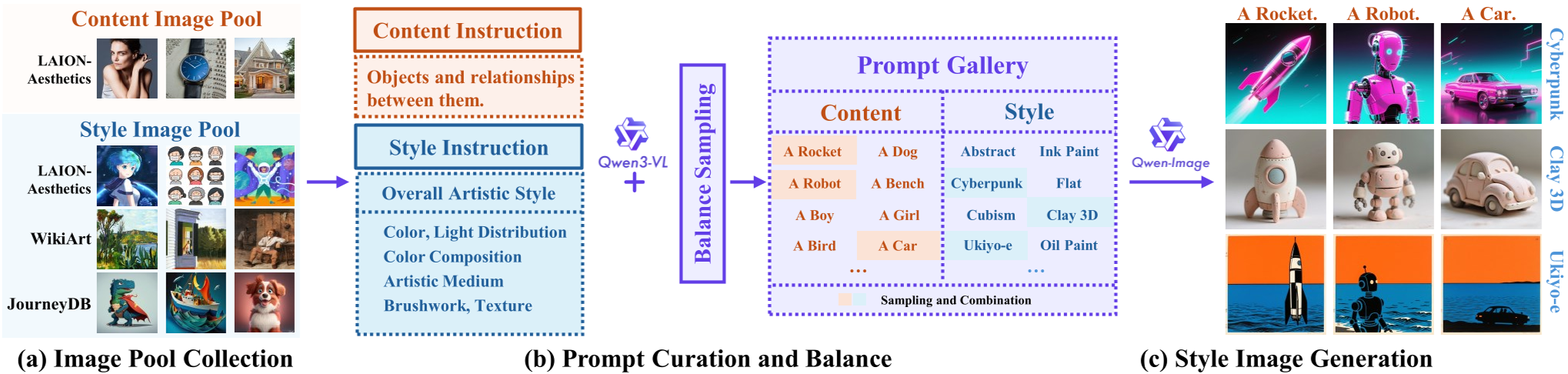 Figure 3: Overview of the MegaStyle data curation pipeline.
Figure 3: Overview of the MegaStyle data curation pipeline.
MegaStyle-Encoder & SSCL
To measure style similarity accurately, the authors proposed Style-Supervised Contrastive Learning (SSCL). By using the known style labels from their synthetic dataset, they force the encoder to pull images with the same "style prompt" together in latent space, regardless of their content. This creates a representation that is truly "style-specific."
MegaStyle-FLUX
For the transfer model, they utilized the FLUX.1 (DiT) architecture. By concatenating reference style tokens with noisy target tokens and using shifted RoPE (Rotary Positional Embeddings), they prevent positional collisions, ensuring the model knows which image provides the style and which provides the canvas.
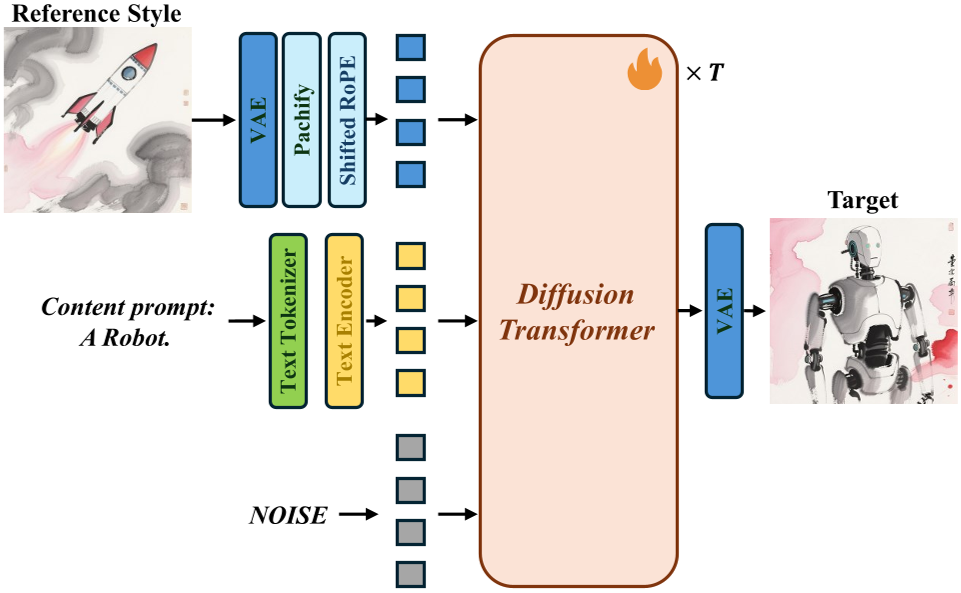 Figure 7: The architecture of MegaStyle-FLUX showing the token concatenation and shifted RoPE.
Figure 7: The architecture of MegaStyle-FLUX showing the token concatenation and shifted RoPE.
Experiments & Results: A New Benchmark
The results on the new StyleRetrieval benchmark are staggering. While standard CLIP models struggle to find similar styles when content changes, MegaStyle-Encoder identifies the correct style with nearly 90% accuracy.
 Figure 1: Visualizations showing high intra-style consistency in the dataset and precise transfer in the FLUX model.
Figure 1: Visualizations showing high intra-style consistency in the dataset and precise transfer in the FLUX model.
In the human preference study, MegaStyle-FLUX dominated in both style consistency and text alignment. Unlike previous methods (like Attention-Distillation) which often produce "carbon copies" of the reference image, MegaStyle-FLUX successfully creates new content in the target style.
Critical Analysis & Conclusion
The main takeaway from MegaStyle is the transition from "Retrieval-based" styles to "Prompt-defined" styles. By defining style through language and then synthesizing a dataset, the authors have bypassed the "messiness" of real-world art datasets.
Limitations: The model's "imagination" is limited by the VLM's vocabulary and the T2I model's biases (e.g., "Japanese painting" prompts often forcing traditional Japanese subject matter). However, the scalability of this pipeline suggests that as VLMs improve, MegaStyle can scale to 10M+ images, potentially "solving" the style transfer problem for good.