本文提出了 MegaStyle,这是一个可扩展的数据构建流水线,旨在生成风格内一致、风格间多样且高质量的风格迁移数据集。利用大型生成模型 Qwen-Image 稳定的文本到图像风格映射能力,作者构建了包含 140 万个风格对的 MegaStyle-1.4M 数据集,并据此训练了专用的风格编码器 MegaStyle-Encoder 和基于 FLUX 的风格迁移模型 MegaStyle-FLUX。
核心速览 (Executive Summary)
TL;DR:MegaStyle 通过一种创新的“文本驱动”思路,解决了风格迁移领域长期存在的高质量配对数据稀缺问题。它利用大模型 Qwen-Image 的稳定性,生成了风格高度一致、内容完全不同的 MegaStyle-1.4M 数据集。基于此数据集训练的 MegaStyle-Encoder 和 MegaStyle-FLUX 在风格检索和通用风格迁移任务上均刷新了记录。
背景定位:这是风格迁移领域向“数据驱动”范式转型的里程碑式工作。它不再纠结于复杂的训练无监督技巧,而是通过构建极高质量的配对数据集,利用配对监督(Paired Supervision)直接解决风格与内容的解耦难题。
痛点与动机 (Problem & Motivation)
在过去十年中,风格迁移(Style Transfer)一直被两个幽灵困扰:
- 特征耦合:像 CLIP 这样的预训练模型往往更关注语义(Semantic),而非纯粹的艺术风格。使用它们提取特征训练出的模型,往往会把参考图的内容(如构图、物体)也带入结果图,造成“内容泄露”。
- 数据质量陷阱:像 WikiArt 这样的传统数据集虽然作品丰富,但其分类逻辑是“作者”或“时期”。然而,凡高不同时期的画作风格可能天差地别(见下图 a),如果强行把它们作为“同一种风格”喂给模型,模型会感到“困惑”,最终只能学到粗浅的色调。
 左侧为传统艺术品数据集的混乱,右侧为 MegaStyle 构建的风格内极度一致的配对数据。
左侧为传统艺术品数据集的混乱,右侧为 MegaStyle 构建的风格内极度一致的配对数据。
方法论详解 (Methodology - The Core)
1. 数据生产流水线 (Data Curation Pipeline)
MegaStyle 的核心灵感是:如果文本能极其精准地描述风格,那么 T2I 模型就能生成无穷无尽的风格一致图。
- 精准描述:利用 Qwen3-VL 将参考图转化为包含色调、光影分布、艺术媒介(如水粉、丝网印刷)、纹理、笔触等五个维度的详细 Prompt。
- 风格对齐:固定风格 Prompt,更换内容 Prompt。例如:固定“日本浮世绘风格”,分别生成“一只猫”和“一座山”。
- 多样性保证:通过层次化 K-Means 对 170K 风格提示词和 400K 内容提示词进行去重和平衡。
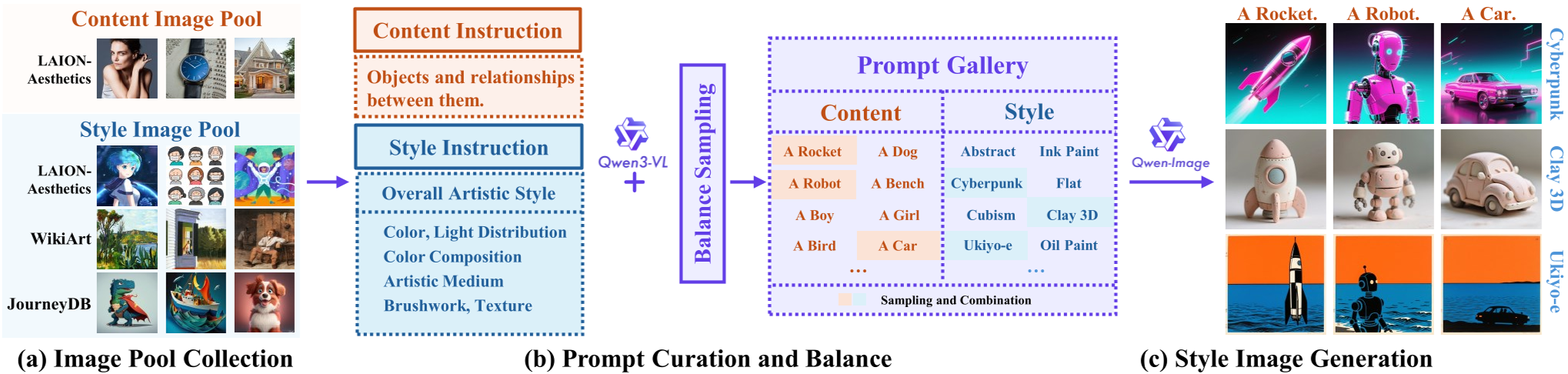 MegaStyle 处理流程:从图像池到 Prompt 平衡,再到 Qwen-Image 批量生产。
MegaStyle 处理流程:从图像池到 Prompt 平衡,再到 Qwen-Image 批量生产。
2. 风格监督对比学习 (SSCL)
为了得到最“懂艺术”的编码器,作者放弃了传统的 Image-Text 简单匹配,而是使用 MegaStyle-1.4M 进行监督对比学习。
- 核心逻辑:强制让 MegaStyle-Encoder 把属于同一种细粒度 Style Prompt 生成的、内容不同的图片,映射到特征空间中的邻近点。这迫使模型学会过滤掉语义内容,只提取纯粹的纹理和笔触特征。
3. MegaStyle-FLUX 架构
借鉴了最新 SOTA 模型 FLUX,作者通过拼接 Reference Image Tokens 和 Noisy Target Tokens,并引入位移旋转位置编码 (Shifted RoPE),有效防止了位置冲突导致的参考图内容污染。
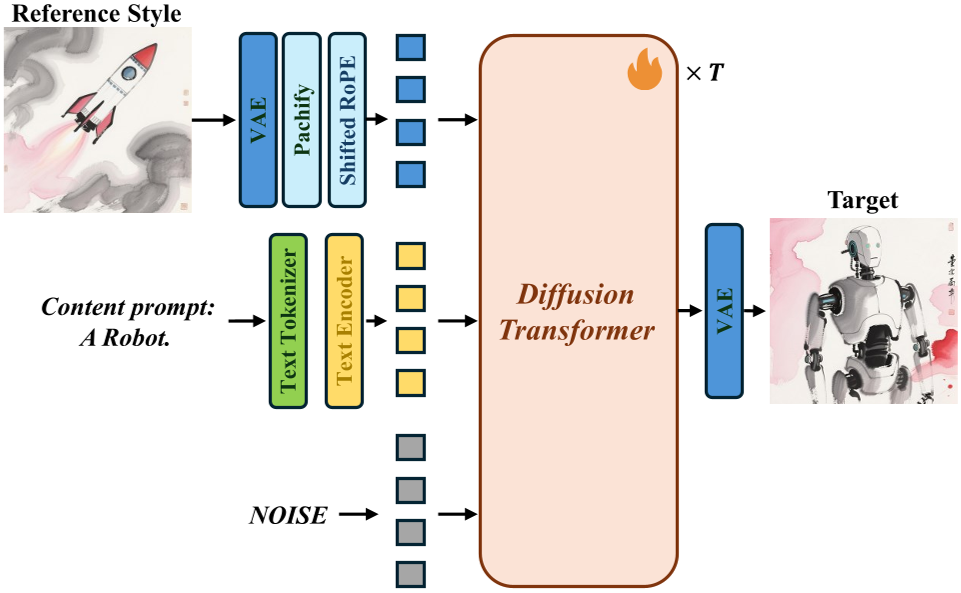 基于 FLUX 的端到端风格迁移架构。
基于 FLUX 的端到端风格迁移架构。
实验与结果 (Experiments & Results)
风格检索:碾压级优势
在检索测试中,MegaStyle-Encoder 展示了惊人的判别力。它的 Recall@1 指数高达 88.46%,不仅远超 CLIP,也大幅领先于之前专门微调过的 CSD (45.60%)。
风格迁移:既要美,又要准
对比现有的 SOTA 方法(如 InstantStyle, CounterStyle),MegaStyle-FLUX 展现了更强的泛化能力。
- 消除内容泄露:当参考图有一个巨大的圆盘状物体时,其他模型往往会在生成图中也画个圆盘;而 MegaStyle-FLUX 仅提取背景中的笔触和颜色。
- 质感还原:对于粘土、3D 渲染、厚涂等强纹理风格,其还原度极高。
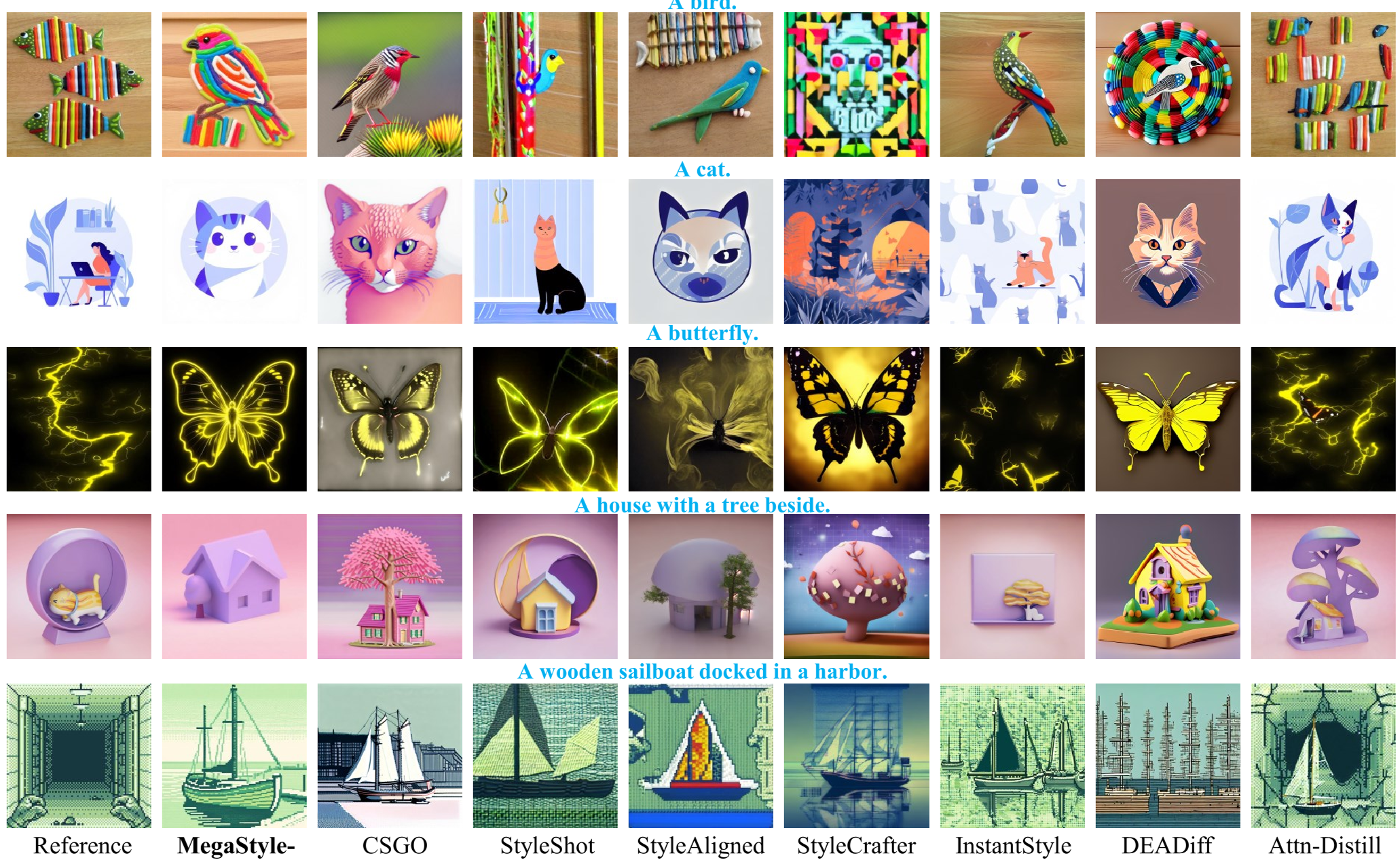 定性对比展示了 MegaStyle 在处理色彩、质感和纹理时的优越性。
定性对比展示了 MegaStyle 在处理色彩、质感和纹理时的优越性。
深度洞察与总结 (Critical Analysis & Conclusion)
Takeaway: MegaStyle 的成功验证了 AI 社区的一个共识:数据的质量(风格一致性)往往比算法的复杂性更重要。 通过将模糊的“视觉风格”翻译为结构化的“文本定义”,MegaStyle 成功将不可规模化的艺术家数据转化为了可无限扩展的合成数据。
局限性与挑战:
- 模型偏见:由于高度依赖生成模型,结果有时会带入 Qwen-Image 的属性偏见(如提到日本画,模型就容易往歌舞伎方向偏移)。
- 描述盲区:目前的 VLM 对于极其抽象或新颖的艺术形式,描述精准度仍有提升空间。
未来展望: 作者计划将数据集规模扩大到 1000 万级别,并进一步精炼风格指令集。对于视觉创作者而言,这套技术路径预示着“私人订制”风格迁移时代的来临。