MegaFlow 是一种专为解决大位移(Large Displacement)光流估计设计的统一生成架构。该方法通过将冻结的 DINOv2 视觉基础模型(Vision Priors)与全局匹配及轻量化迭代细化评估相结合,在多个光流和任意点追踪(TAP)基准测试中实现了 Zero-shot SOTA 性能。
TL;DR
光流估计领域长期被“局部相关性搜索”范式统治,但在面对快速运动(大位移)时往往束手无策。来自 ETH Zurich 和微软的研究团队推出了 MegaFlow,它不再试图从头学习复杂的运动规律,而是巧妙地“搬运”了 DINOv2 的强大视觉先验,通过简单的全局匹配建立初始联系,再辅助以轻量级迭代更新。结果令人侧目:它在未经过训练的任务上(Zero-shot)直接刷写了多项 SOTA,甚至在点追踪(TAP)任务上也让一众专用模型相形见绌。
核心痛点:为什么 SOTA 在“瞬移”面前会失效?
传统的深度学习光流方法(如 RAFT)本质上是在做一个“循迹”游戏:模型在局部像素范围内通过构建 Cost Volume 来寻找最像的对应点。
- 搜索窗口限制:如果物体移动速度太快,超出了搜索范围,模型就会彻底迷路。
- 过拟合困境:很多模型在合成数据集(如 FlyingChairs)上表现优异,但在真实世界复杂的光照、模糊和遮挡下,其泛化能力(Zero-shot)往往断崖式下跌。
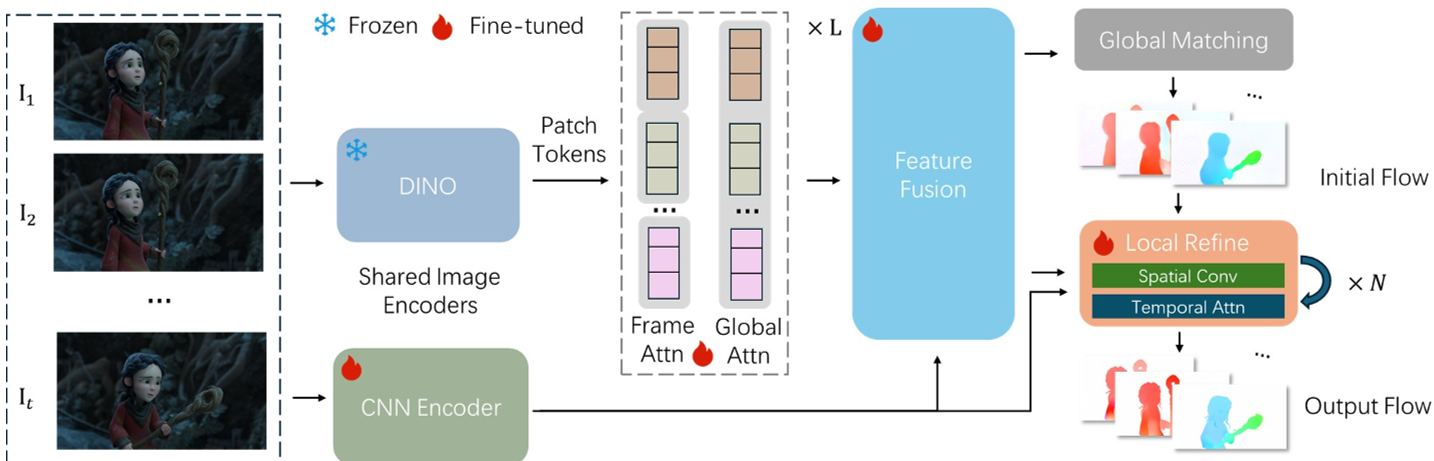
架构解析:MegaFlow 的“先修后精”哲学
MegaFlow 的核心直觉是:既然视觉基础模型(Visual Foundation Models)已经学到了丰富的语义和几何规律,为什么不直接拿来做全局匹配?
1. 强力特征提取与融合
模型使用冻结的 DINOv2 作为骨干,配合可学习的 VGGT 块。它不仅提取语义特征,还叠加了一个轻量级 CNN 分支来补偿 ViT 贴片化(Patchification)丢失的亚像素细节。
2. 全局匹配(Global Matching):解决生存问题
不同于局部搜索,MegaFlow 在特征图上计算所有像素对的相关性: 通过对所有候选位置进行 Softmax 归一化求期望,模型可以瞬间锁定哪怕处于图像另一端的匹配点。这一步解决了大位移的“有无”问题。
3. 多帧迭代细化(Iterative Refinement)
在获得全局初始值后,模型引入了一个包含 Temporal Attention(时间注意力) 的循环模块。
- 卷积动力:利用 ConvNeXt 处理局部相关性。
- 时间一致性:通过跨帧注意力确保物体在长序列中的运动轨迹是平滑且符合逻辑的。
实验战绩:Zero-shot 的降维打击
MegaFlow 最惊艳的地方在于其 Zero-shot 泛化性。
- 极端大位移能力:对比 Sintel 数据集,在位移大于 40 像素(s40+)的场景下,传统方法的误差曲线陡峭上升,而 MegaFlow 的误差曲线极其平缓。在 Sintel Final pass 中,它将误差从此前基线的 26.8 降低到了 11.1。
- 通用性:同一个模型,直接去跑点追踪(Point Tracking)任务,其精度竟然超越了专门为此设计的 CoTracker2。

深度洞察:为什么这种做法能行?
以往大家认为光流是单纯的几何对齐,不需要太多的语义理解。但 MegaFlow 证明了,在图像出现极度模糊或大跨度位移时,语义先验(What is the object) 能有效地指导 位置对齐(Where it goes)。 此外,通过将时间注意力引入细化阶段,模型不仅仅在做两帧比较,而是在理解一个“连续运动的过程”。这种从 2-frame 到 multi-frame 的进化,是其在遮挡(Occlusion)场景下稳健的关键。
总结与局限
MegaFlow 为光流和点追踪的统一提供了新的范式。它的局限性依然存在:
- 计算开销:由于使用了大规模 Transformer 骨干和全局相关性计算,显存占用相对较高(Full model 约 936M 参数)。
- 特定细节:在 KITTI 等特定分辨率和畸变较大的场景下,受限于 Patch 尺度的固定,其性能还有进一步优化的空间。
但不可否认,MegaFlow 标志着光流研究正从“单纯卷积迭代”迈向“深利用视觉大模型先验”的新阶段。
本文由资深学术技术主编重构。