本文提出了 MeMix,一种用于流式 3D 重建的无需训练、即插即用的状态更新模块。通过将循环状态(Recurrent State)重新构建为“存储混合体”(Memory Mixture),MeMix 实现了在长序列推理中显著降低几何漂移和灾难性遗忘,在 7-Scenes 等基准测试中将重建完整性误差平均降低了 15.3%。
TL;DR
在实时 3D 重建中,模型往往像个“健忘症患者”:为了记住当下的瞬间,它们不得不擦除掉几分钟前的记忆。清华大学与浙江大学的研究团队提出 MeMix,这是一种无需训练、即插即用的模块。它通过将模型状态分割成多个存储块,并只更新最不相关的部分(Bottom-k),实现了在不增加显存开销的前提下,显著增强了长序列重建的稳定性和精度。
1. 痛点深挖:为什么流式重建会“崩塌”?
目前的 3D 重建主要分为两种范式:
- 离线批处理 (Offline Batch):全局优化,质量高,但处理长序列会 OOM(显存溢出),且延迟高。
- 流式在线 (Streaming Online):逐帧处理,分为 KV-cache 式(显存随时间爆炸)和固定状态循环式 (Fixed-state Recurrent)。
循环式模型(如 CUT3R)虽然显存恒定(O(1)),但存在一个致命缺陷——全量覆盖写入。每一帧新图像都会强行改写所有的隐状态 Token。随着时间推移,早期的几何约束被冲刷殆尽,导致模型在处理 300 帧以上的序列时,会出现严重的轨迹漂移和表面“撕裂”现象。
2. 核心直觉:MeMix 的“选择性记忆”
研究者从 Mixture-of-Memories (MoM) 得到启发:既然全写会干扰记忆,那为什么不只写一部分?
MeMix 的逻辑非常简洁高效:
- 状态划分:将循环状态 划分为多个独立的 Patch。
- 相似度路由:计算当前帧特征 与状态候选值 的点积得分。
- Bottom-k 更新:得分越低,代表该 Patch 与当前观察最不匹配(信息最陈旧或最不相关)。MeMix 只通过二值掩码 更新这些得分最低的 Patch,而对其他高分 Patch 实行“精确保留”。
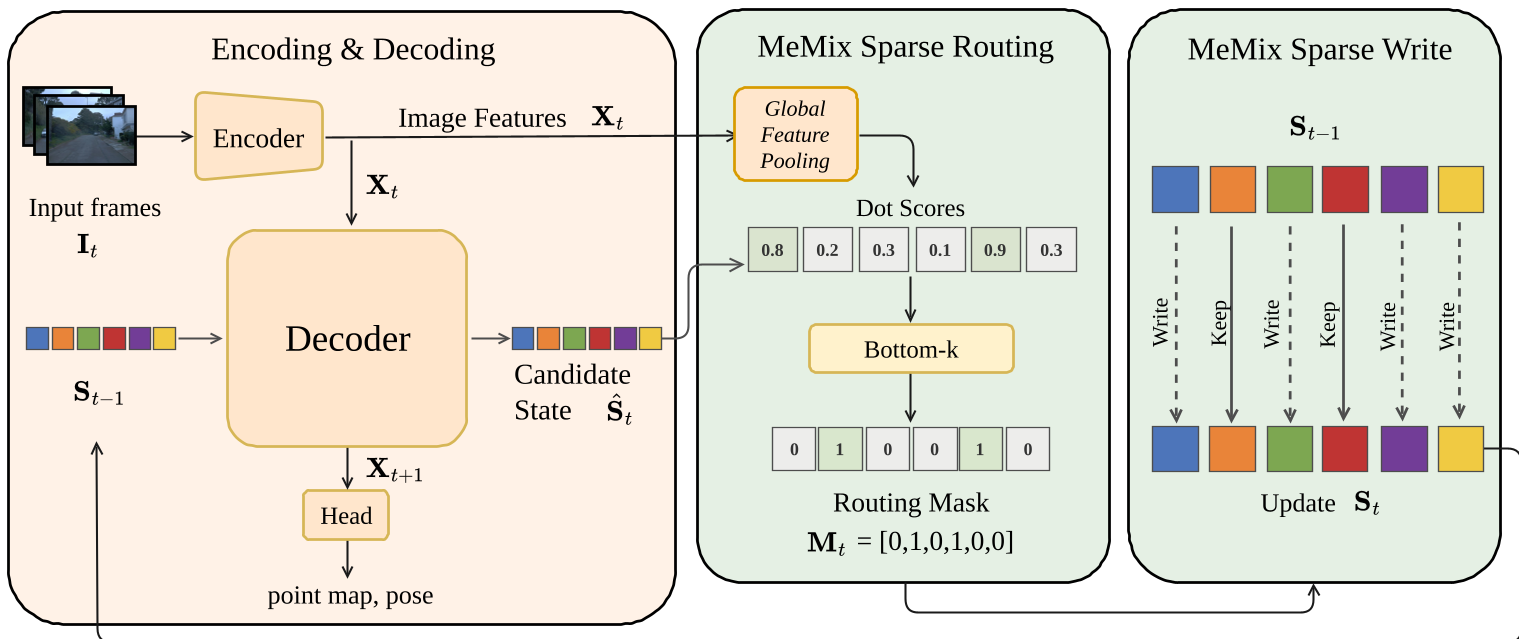 图 1:MeMix 整体流程,展示了从特征编码到选择性 Patch 更新的过程
图 1:MeMix 整体流程,展示了从特征编码到选择性 Patch 更新的过程
3. 统一框架:从 CUT3R 到 MeMix
作者巧妙地将多种模型统一到了一个公式下:
- 当 时,是传统的 CUT3R(全量覆盖)。
- 当 由注意力权重决定时,是 TTT3R(测试时训练)。
- 当 是二值路由掩码时,就是 MeMix。
这种设计使得 MeMix 能够完美兼容现有的 SOTA 模型。
4. 实验战绩:极致的性价比
实验在 7-Scenes, ScanNet 和 KITTI 等多个数据集上展开。
几何结构的“起死回生”
在长时间运行后,原生模型往往会出现“幽灵影像”或几何缺失,而加入 MeMix 后,重建的表面更加平整、连贯。
 图 2:定性对比,红框显示了 MeMix 如何通过减少漂移来修复表面撕裂和缺失
图 2:定性对比,红框显示了 MeMix 如何通过减少漂移来修复表面撕裂和缺失
推理开销近乎为零
下表数据展示了 MeMix 的工程优势:它几乎不改变 FPS,也不增加显存占用。 | 方法 | FPS (w/o MeMix) | FPS (w. MeMix) | GPU (GB) | | :--- | :--- | :--- | :--- | | TTT3R | 12.72 | 12.81 | 6.96 | | TTSA3R | 12.58 | 12.78 | 6.63 |
5. 深度洞察:为什么是 Bottom-k?
在消融实验中,作者发现了一个有趣的现象:Bottom-k 远优于 Top-k。
- Top-k:导致少数 Patch 被反复改写,产生正反馈效应,其他 Patch 则逐渐“僵化”,导致记忆多样性下降。
- Bottom-k:强制模型去更新那些最不相关的部分,使得写入操作在所有 Token 上分布更均匀,实现了更高效的“存储空间回收”。
6. 总结与展望
MeMix 证明了在线 3D 重建的瓶颈不在于模型参数量,而在于状态管理的策略。尽管 MeMix 在数百帧级别表现优异,但在面对数公里的超大规模场景(数千甚至上万帧)时,如何动态调整 值以及引入几何先验的更新规则,仍是未来值得探索的方向。
对于开发者而言,MeMix 的代码已开源,这种无需重新训练即可提升模型上限的“免费午餐”,无疑是空间智能领域的一件利器。