本文提出了 BEACON,一种里程碑引导的策略学习框架。该方法通过将长程任务分解为基于里程碑的片段(Segments),并结合时域奖励塑形与双尺度优势估计(Dual-scale Advantage Estimation),在 ALFWorld, WebShop 和 ScienceWorld 等基准测试中显著超越了 GRPO 和 GiGPO,实现了 SOTA 性能。
TL;DR
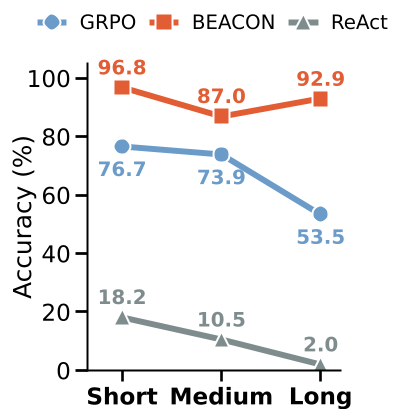
在训练长决策链的 LLM Agent 时,现有的强化学习(如 GRPO)常因“一步错全盘否”的信用分配机制导致训练崩溃。本文提出的 BEACON 框架通过将长任务切分为以“里程碑”(Milestone)为界的片段,引入局部优势估计,显著提升了样本效率。在 ALFWorld 等基准测试中,BEACON 将长任务成功率从 53.5% 暴力拉升至 92.9%。
1. 痛点:长程任务中的“努力的偏见”
想象你正在教一个 AI 整理厨房:AI 成功找到了肥皂、清理了柜台,但在最后一步放下杯子时手滑了。在传统的轨迹级优化(如 GRPO 或 PPO)中,这整个过程会被打上“失败”的标签。
这种做法导致了两个严重的学术问题:
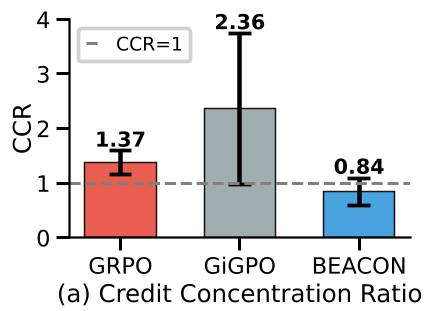
- 信用分配错误 (Credit Misattribution):早期完美的动作因为后期的偶然失败被负面梯度惩罚。实验显示,在长程任务中,竟然有超过 40% 的梯度更新是互相矛盾的。
- 样本饥饿 (Sample Inefficiency):由于长程任务极难完美通关,绝大多数采样轨迹的奖励都是 0。那些已经完成 90% 难度的“部分成功”样本被无情抛弃,浪费了宝贵的信号。
2. 核心直觉:里程碑的马尔可夫性
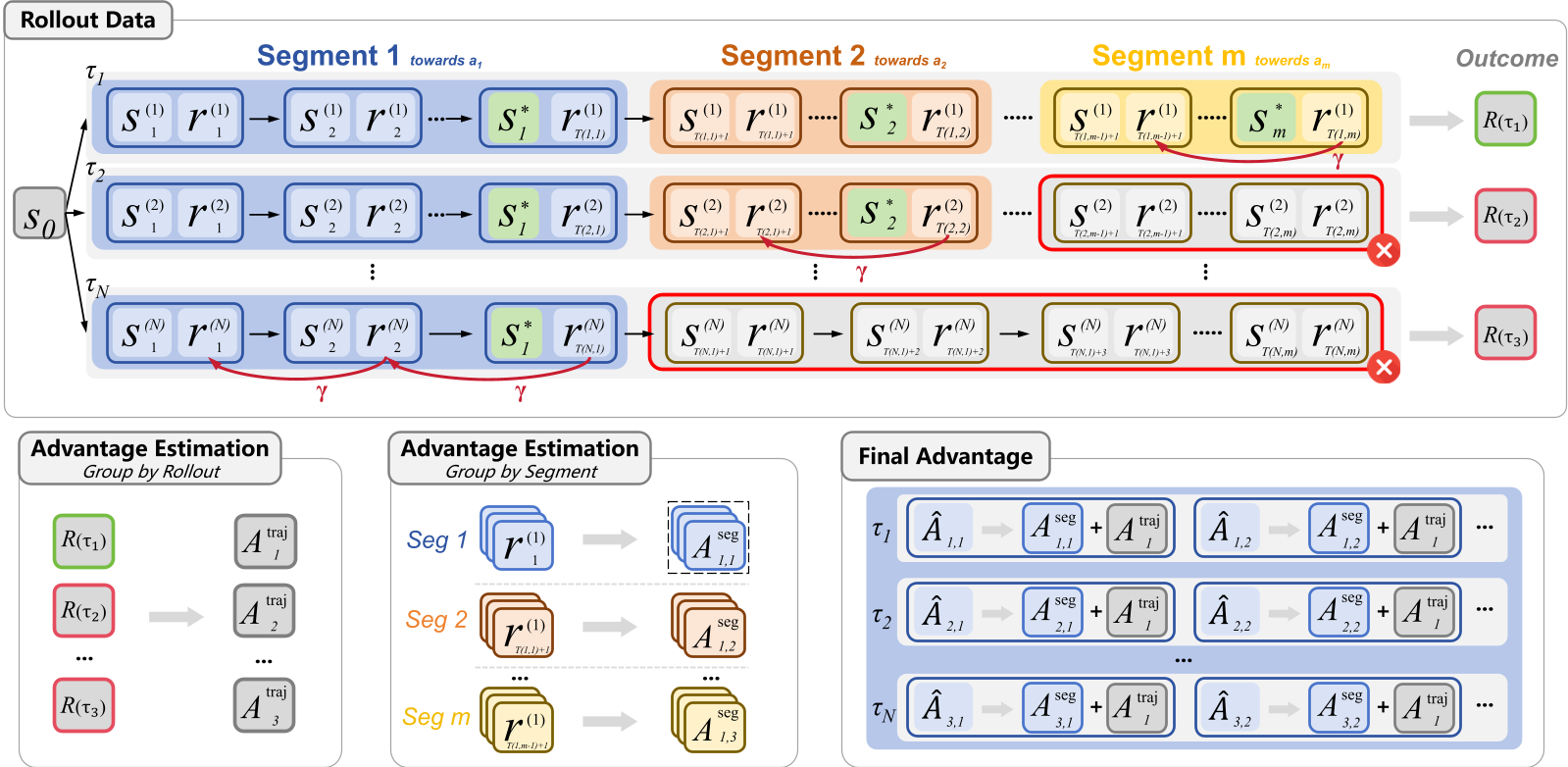
BEACON 的核心假设是:如果 Agent 达到了某个里程碑状态(比如拿到了目标物体),那么它之前的操作历史对于下一步的成功就不再重要了。 这种局部独立性允许我们将长轨迹解耦。
核心机制拆解:
- 轨迹切分 (Trajectory Partitioning):利用环境的反馈信号(如 Web 页面跳转、物体状态改变)识别里程碑。
- 时域奖励塑形 (Temporal Reward Shaping):在片段内部,越接近里程碑的动作获得的奖励权重越高(),引导 Agent 追求效率。
- 双尺度优势估计 (Dual-Scale Advantage Estimation):
- 轨迹级 (Traj-level):保持对全局最终目标的关注。
- 片段级 (Seg-level):关键创新点。它仅将当前片段与那些“也达到了该里程碑”的轨迹进行对比。这就像在马拉松比赛中,不拿你的第一个 5 公里成绩去和跑完 42 公里的人比,而是只和同样跑完前 5 公里的人比。
3. 实验结果:全方位的跨代提升
BEACON 在 ALFWorld、WebShop 和 ScienceWorld 三大榜单上均刷新了记录。其优势在任务越长时体现越显著:
- 性能稳定性:当任务长度增加时,GRPO 的成功率从 76.7% 断崖式下跌至 53.5%,而 BEACON 依然稳住在 92.9% 附近。
- 样本利用率:有效样本利用率从 23.7% 提升至 82%,这意味着原本被视为垃圾的“失败轨迹”现在转化为了强有力的梯度补充。
- 超越闭源大模型:使用 Qwen2.5-1.5B 这种小尺寸底座训练出的 BEACON Agent,在专业任务上的成功率甚至大幅超越了 GPT-4o。
4. 深度洞察:为什么不只是模仿?
有人质疑 BEACON 是否只是在做“里程碑模仿”。作者通过消融实验证明:即使在没有任何时域衰减()的情况下,仅靠里程碑结构,模型也能发现优于专家轨迹(Oracle)的执行策略。
更本质的分析显示,BEACON 的 Zero-Advantage Ratio (ZAR) 在训练初期迅速下降,这说明模型摆脱了“梯度饥饿”。比起粗暴的全局奖励,这种“由于看懂了阶段性进步”而产生的梯度流更加稳定、连续。
5. 总结与反思
BEACON 成功证明了:处理复杂 Agent 任务,不能把 LLM 当成一个黑盒的分类器,而是要将其视为一个在时空中进行状态转换的交互实体。
局限性:目前 BEACON 仍依赖于环境提供的明确反馈(如 Pick-up 成功)来界定里程碑。未来的挑战在于如何利用大模型自身的逻辑推理能力,在没有外部硬信号的情况下,自动、动态地发现这些“认知里程碑”。
对于正在开发自主代理(Autonomous Agents)的团队来说,BEACON 提供的**“片段级对比学习”**思路,无疑是提升模型在复杂业务流程中鲁棒性的重磅武器。