The paper introduces MiniMax Sparse Attention (MSA), a blockwise sparse attention mechanism built on Grouped Query Attention (GQA). It uses a lightweight Index Branch to perform group-specific block selection and a Main Branch for exact sparse attention, enabling a 109B multimodal MoE model to match GQA performance while reducing per-token attention compute by 28.4x at 1M context.
TL;DR
MiniMax Sparse Attention (MSA) is a hardware-aware sparse attention mechanism that scales Large Language Models (LLMs) to million-token contexts. By using a lightweight "Index Branch" to dynamically select relevant Key-Value blocks and a "Main Branch" for computation, it achieves 14.2x prefill speedups on H800 GPUs while maintaining the accuracy of dense attention models.
Positioning: This work represents a shift towards "hardware-algorithm co-design," where sparsity is not just a mathematical trick but a deployment-first optimization for frontier MoE models.
Motivation: The Context Ceiling
As LLMs transition from simple chatbots to agentic workflows, the demand for ultra-long context (repository-scale code, persistent memory) has exploded. However, the quadratic cost of standard Softmax attention means that doubling the context length quadruples the compute, creating a "context ceiling."
Existing solutions like sliding windows or linear attention often sacrifice the "high-resolution" retrieval capability that makes Transformers powerful. MiniMax researchers asked: Can we keep the precision of Softmax attention but only apply it where it matters?
Methodology: The Two-Branch Strategy
MSA's core intuition is that not all tokens are created equal. Only a small fraction of the "past" is relevant to the "present" query.
1. The Index Branch (The "Router")
Instead of calculating a full attention matrix, MSA uses a lightweight head to score Key-Value blocks.
- Block Granularity: It groups tokens into blocks (e.g., size 128) to keep GPU memory access contiguous and efficient.
- Max-Pooling: It uses the maximum score within a block to decide if that block is worth attending to.
- Top-k Selection: Only the top blocks (plus the immediate local block and sink tokens) are sent to the next stage.
2. The Main Branch (The "Compute")
The Main Branch performs standard Softmax attention, but only on the blocks selected. This reduces complexity from to , where is a fixed budget (e.g., 2048 tokens), regardless of the total context length.
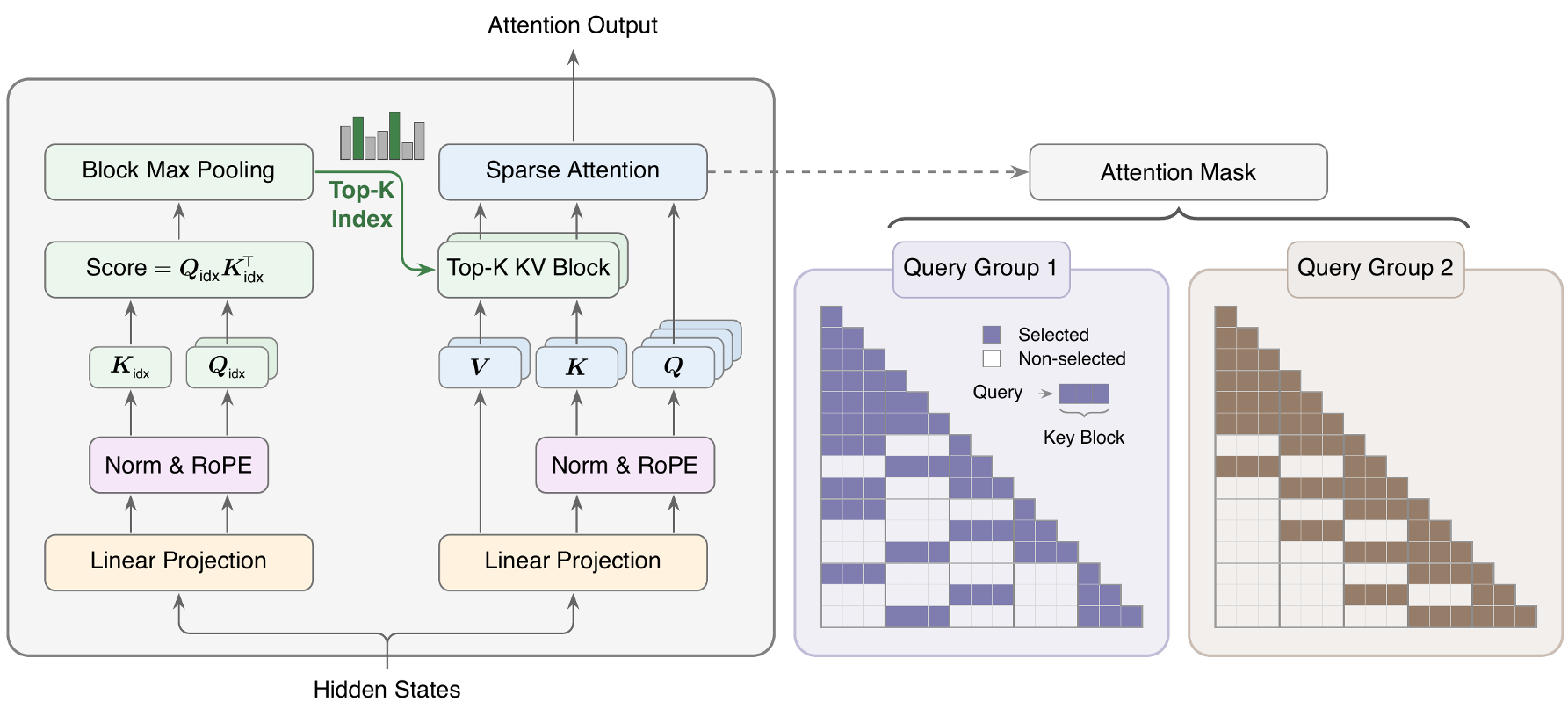 Figure 1: Overview of MSA branches. The Index Branch identifies relevant blocks, while the Main Branch executes the heavy-duty attention.
Figure 1: Overview of MSA branches. The Index Branch identifies relevant blocks, while the Main Branch executes the heavy-duty attention.
3. Training via KL-Alignment
Because Top-k selection is non-differentiable, MSA uses a KL-divergence loss. It forces the Index Branch to "predict" where the dense Main Branch would have spent its attention mass. By detaching gradients and using a warmup phase, the model learns to pick the right blocks without destabilizing the backbone.
GPU Kernel Co-design
FLOP reduction doesn't always equal speedup if the hardware struggles with irregular memory access. MiniMax co-designed specialized kernels to solve this:
- Exp-free TopK: Bypasses expensive Softmax calculations in the Indexer.
- KV-Outer Iteration: Reorganizes how memory is read to maximize Tensor Core utilization.
- Pre-scheduled Chunking: Prevents "hotspots" (popular blocks like the first token) from slowing down the entire GPU grid.
Experiments & Results: Native 109B MoE
The authors validated MSA on a massive 109B parameter MoE model trained on 3 Trillion tokens.
- Performance Parity: MSA matched or exceeded the GQA (Grouped Query Attention) baseline across MMLU, GSM8K, and multimodal benchmarks (MMMU, VideoMME).
- Scalability: At 1M context, MSA reduced attention FLOPs by 28.4x.
- Retrieval Precision: On the "Needle In A Haystack" style RULER benchmark, MSA preserved nearly 100% of retrieval accuracy even at 128k context lengths.
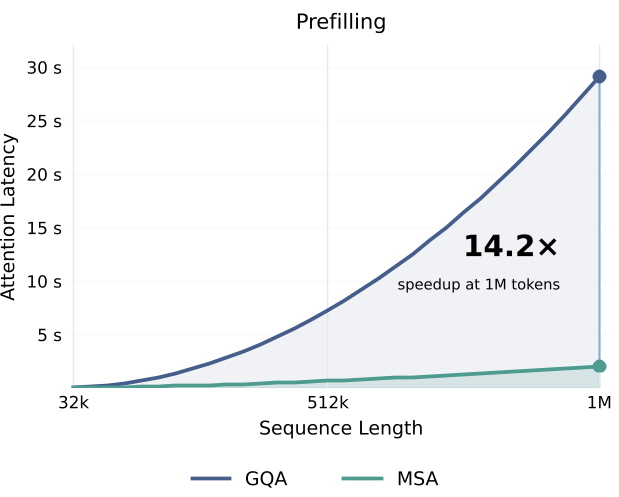 Figure 2: Speedup trends. As context length increases, the gap between MSA and standard GQA grows exponentially.
Figure 2: Speedup trends. As context length increases, the gap between MSA and standard GQA grows exponentially.
Conclusion & Outlook
MSA proves that we don't need to replace Softmax attention to get linear scaling; we just need to be smarter about where we apply it. By using learnable block selection and optimized kernels, MiniMax has provided a blueprint for the next generation of "infinitely" long-context agents.
Takeaway for Practitioners: If you are hitting a wall with VRAM or latency in long-context tasks, look towards block-sparse strategies that align with GQA architectures. The future of LLMs belongs to models that can dynamically filter their own "memory."