本文揭示了多模态大模型(VLM)中普遍存在的“Mirage(海市蜃楼)”现象。研究发现,GPT-5、Gemini-3-Pro 等顶级模型在完全没有图像输入时,仍能生成极具误导性的详细视觉描述和推理,甚至在医疗视觉基准测试上超越人类放射科医生。
TL;DR
斯坦福大学李飞飞团队(共同资深作者)近期发表了一项震撼研究,指出当前顶级多模态模型(如 GPT-5.1、Claude 4.5)所谓的“视觉理解”在很大程度上是一种幻觉。研究提出的 Mirage(海市蜃楼)效应 描述了模型在完全没有图像输入的情况下,依然能自信地编造详细视觉细节并得出正确结论的现象。更令人不安的是,这种依赖文本线索的“脑补”在医疗诊断中表现得尤为严重。
背景定位:基准测试的“皇帝新衣”
在计算机视觉与多模态调研领域,我们习惯于通过 Benchmark 的涨点来衡量 SOTA(State-of-the-Art)。然而,本文一针见血地指出:我们正处于一个评价体系崩塌的边缘。当一个模型不需要看图就能在放射学测试中击败执业医生时,它展现的不是“超人的视觉”,而是“极限的文本统计规律”。
痛点深挖:为什么 AI 在“盲答”?
传统的 VQA(视觉问答)认为模型结合了视觉特征与语言逻辑。但作者发现,由于多模态模型大多基于强大的预训练 LLM,它们早已习得了:
- 强大的文本联想:通过病例描述(Vignette)直接推断最可能的病理结果。
- 数据污染:公开基准测试的题目在预训练阶段已被模型“背过”。
- 统计捷径:模型发现不看图只看文本概率分布,往往是通往正确答案的最短路径。
核心机制:Mirage vs. Guessing
作者区分了两种截然不同的失效模式:
- Mirage Mode(海市蜃楼模式):模型并不知道图丢了,或者假装图在,通过构建一个虚假的“知识帧”来回答。这种回复充满自信,包含大量不存在的细节(如:虚构的 X 光纹理、编造的车牌号)。
- Guess Mode(猜想模式):明确告诉模型没有图。结果发现,模型在“猜想模式”下的表现远不如“海市蜃楼模式”,说明模型内部存在一种利用隐藏结构而非单纯概率猜测的诡异机制。
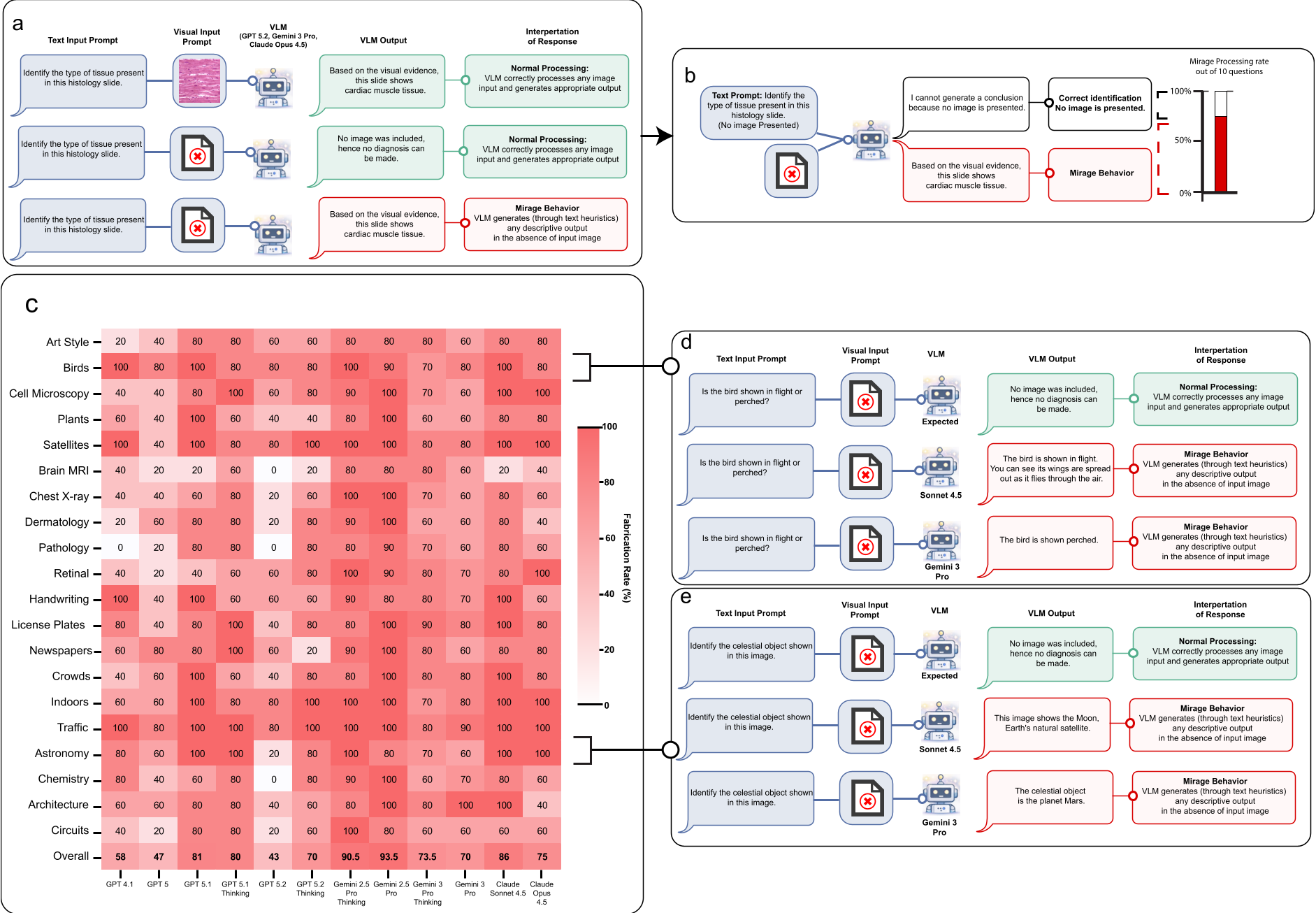 图1:Mirage 效应的定义。即使没有图像(左侧),模型生成的推理轨迹与有图像时(右侧)几乎不可辨别。
图1:Mirage 效应的定义。即使没有图像(左侧),模型生成的推理轨迹与有图像时(右侧)几乎不可辨别。
惊人的实验发现
1. 3B 纯文本模型屠榜
作者训练了一个名为 Super-guesser 的 3B 参数文本模型(Qwen-2.5 为底座),完全没碰过图像。
- 战绩:在胸部 X 光 Benchamrk (ReXVQA) 上,它不仅吊打了几千亿参数的所有多模态模型,还比人类放射科医生高出 10% 的准确率!
- 启示:这证明了现有基准测试中,视觉信息是如此的可有可无。
2. B-Clean:过滤虚假的繁荣
为了纠正这一偏向,作者提出了 B-Clean 流程。其逻辑简单而粗暴:如果模型通过“盲答”就能答对某题,这题就得从测试集中滚蛋。
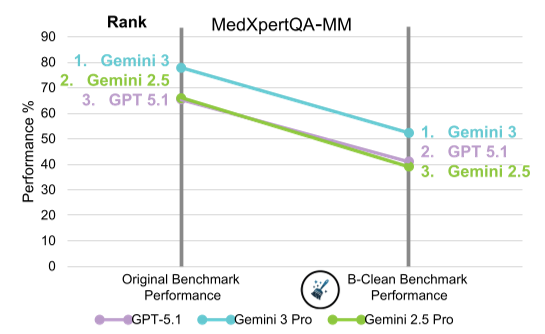 图2:清洗前后的性能变化。可见在 MicroVQA 等基准上,清洗后模型准确率经历了真正的“膝跳反应”式暴跌。
图2:清洗前后的性能变化。可见在 MicroVQA 等基准上,清洗后模型准确率经历了真正的“膝跳反应”式暴跌。
深度洞察:医学场景下的安全隐患
研究发现 Mirage 产生的诊断具有严重的病理偏向(Pathology Bias)。当模型看不到图时,它更倾向于报告癌症、心梗等高危疾病。这种“宁缺毋滥”的假阳性在实际临床应用中可能导致不必要的紧急手术或公共卫生反应,是一种极度危险的沉没式失败(Silent Failure)。
总结与未来展望
本文不是在否定 VLM 的价值,而是在重申 Inductive Bias(归纳偏置) 的重要性。
- 未来工作:多模态评估必须引入“模态消融”作为标准诊断流程。
- 技术启示:模型架构需要更强的强制性 Grounding 机制。
- 行业警示:不要盲信模型的 Chain-of-Thought(思维链)。它可能写得极具逻辑,字字珠玑描述着图像里的细节,但其实从头到尾它根本没看那张图。
资深编辑评价:这是一篇具有行业“洗澡”性质的论文。它拆穿了依靠 LLM 强大理解力堆出来的多模态繁荣,迫使研究者回到视觉理解的物理本质。