MMaDA-VLA is a native pre-trained Large Diffusion Vision-Language-Action model that unifies multi-modal understanding and generation within a single discrete token space. It achieves state-of-the-art results on robotics benchmarks, reaching a 98.0% success rate on LIBERO and an average length of 4.78 on CALVIN.
TL;DR
MMaDA-VLA represents a paradigm shift in robot manipulation by moving away from autoregressive "next-token" action prediction. By treating language, images, and actions as unified discrete tokens within a Large Diffusion Model (LDM), it enables the robot to "imagine" a goal state and plan its actions simultaneously. This approach shatters previous SOTA benchmarks, achieving near-perfect success rates on LIBERO and significantly improving long-horizon task consistency.
Problem & Motivation: The "Reversal Curse" and Temporal Drift
Traditional Vision-Language-Action (VLA) models usually append a policy head to a pre-trained Vision-Language Model (VLM). However, this creates a "module boundary" where information fidelity is lost. More importantly, autoregressive models predict actions one-by-one; if a mistake is made early in a sequence, the error compounds, leading to catastrophic failure in long-horizon tasks.
The authors argue that robotic actions within a chunk are inherently unordered (e.g., the 7 degrees of freedom in an arm move together). Imposing a sequential order via Transformers is an unnecessary inductive bias. MMaDA-VLA solves this by using Iterative Denoising, allowing the model to refine the entire action trajectory and the future visual outcome in parallel.
Methodology: The Power of Parallel Denoising
The core of MMaDA-VLA is its Native Discrete Diffusion framework. Unlike models that fine-tune an autoregressive backbone for diffusion, MMaDA is built from the ground up for masked token prediction.
1. Unified Tokenization
Everything—the instruction, the current image, the target goal image, and the action bins—is mapped into a common discrete token space.
- Vision: Uses MAGVIT-v2 for image quantization.
- Action: Discretizes continuous control into 256 bins per dimension.
2. Hybrid Attention & Parallel Generation
The model employs a unique attention strategy:
- Full Bidirectional Attention for intra-modal tokens (letting the action dimensions talk to each other freely).
- Causal Attention for inter-modal interactions (ensuring instruction influences generation, not vice-versa).
 Figure: The MMaDA-VLA unified architecture for instruction following and parallel generation.
Figure: The MMaDA-VLA unified architecture for instruction following and parallel generation.
3. Efficiency via Training-Free Caching
To handle the latency of iterative denoising (24 steps), the authors introduced dLLM-Cache. By caching stable instruction tokens and selectively refreshing generation tokens based on cosine similarity, they achieve the real-time speeds required for physical hardware.
Experiments & Results: Setting a New Bar
MMaDA-VLA was pre-trained on a massive dataset of 61 million steps crossing various robotic embodiments and human demonstrations.
Benchmarking SOTA
In the CALVIN challenge (ABC→D setting), MMaDA-VLA achieved an average execution length of 4.78 out of 5 sub-tasks, a massive leap over the previous SOTA of 4.44 (DreamVLA).
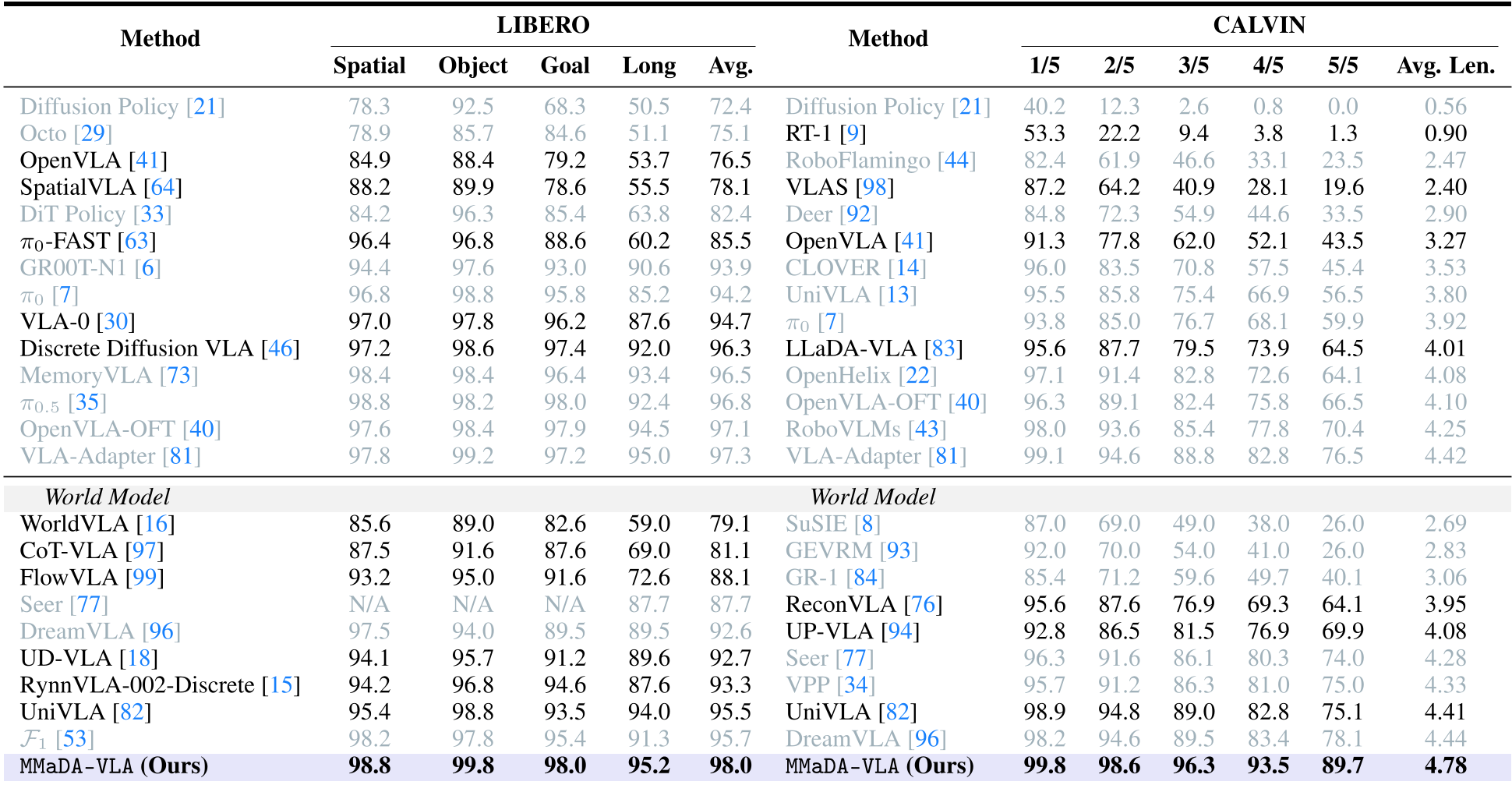 Table: MMaDA-VLA consistently outperforms both discrete and continuous-action baselines.
Table: MMaDA-VLA consistently outperforms both discrete and continuous-action baselines.
The "World Model" Insight
A critical ablation study (Table 4 in the paper) reveals that predicting the Goal Image is not just an auxiliary task—it is vital. Removing the goal prediction dropped performance significantly. This confirms that the model uses the "imagined" future to ground its physical actions.
Critical Analysis & Conclusion
MMaDA-VLA proves that the "Diffusion Paradigm" is likely superior to the "Autoregressive Paradigm" for embodied AI. By allowing order-free refinement, the model can recover from intermediate errors that would typically derail a standard VLA.
Limitations: As noted in the visual generation analysis, while the model understands dynamics, it lacks pixel-level fidelity. Fine-grained details of grippers are often blurred. Future work may need to bridge the gap between "semantic future prediction" and "high-fidelity visual rendering" to handle microscopic assembly tasks.
Takeaway: If you are building a VLA, move away from simple next-token prediction. Grounding your actions in an "imagined" visual goal via discrete diffusion is the current gold standard for long-horizon consistency.