本文提出了一个名为“Actor-Judge”的无监督自进化(Self-Evolution)框架,用于提升多模态大模型(MLLM)的数学推理能力。该方法通过结合 Actor 的自一致性信号与冷启动 Judge 模型的有界调制,在不依赖人工标注的情况下,显著提升了 Qwen2.5-VL 等模型在 MathVision (+5.9%) 等五个数学推理榜单上的表现。
TL;DR
多模态模型的推理能力一直高度依赖昂贵的“喂饭”式标注。本文提出了一种全新的无监督自进化框架,让模型同时扮演 Actor(执行者) 和 Judge(裁判)。通过组相对策略优化(GRPO)和精妙的 Judge 调制机制,模型在没有一个标准答案的情况下,在 MathVision 榜单上实现了 +5.9% 的惊人涨幅,性能逼近甚至超越了部分有监督蒸馏方法。
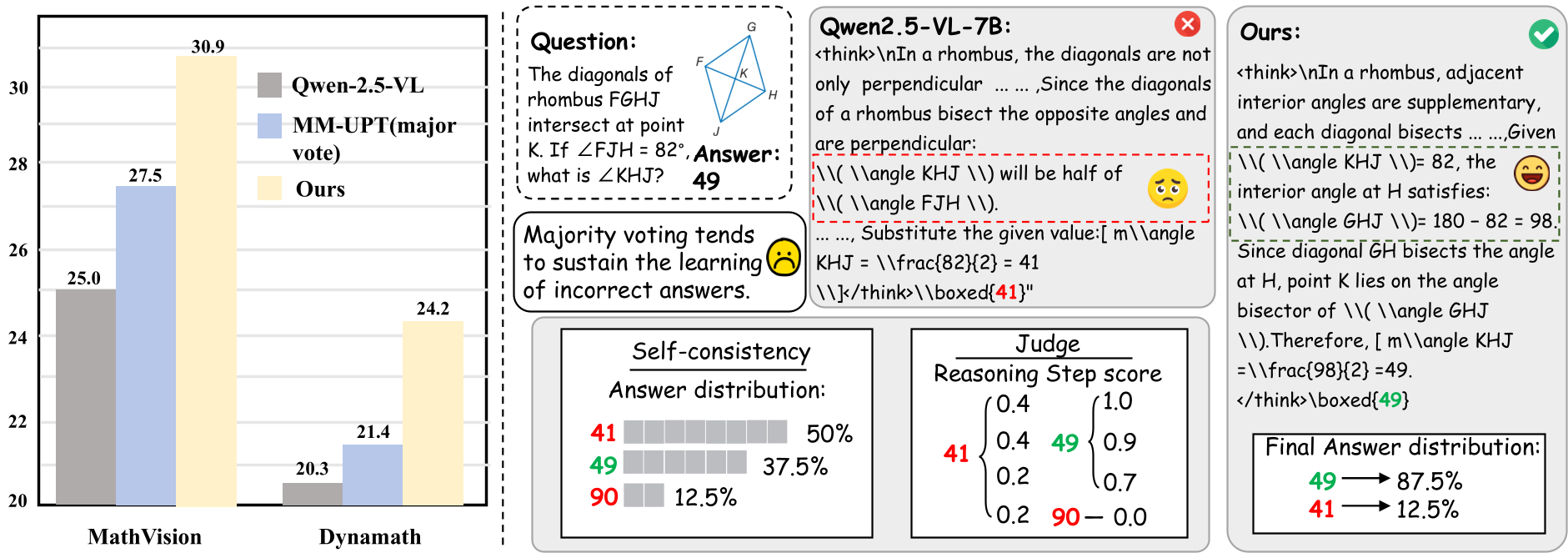
痛点深挖:多数投票的“陷阱”
在无监督学习领域,最常见的套路是“多数投票(Majority Voting)”:让模型对一个问题做 10 次,哪个答案出现最多,就把它当成真理(伪标签)来训练。
然而,作者指出这种做法存在严重的系统性偏见(见下图):
- 错误共识:如果模型自带某种偏见,它可能一致性地产生错误的推理路径。多数投票会进一步强化这种错误。
- 熵坍缩(Entropy Collapse):为了追求一致性,模型会迅速收敛到几种机械的回复模式,丧失探索能力。
- 回复长度塌陷:模型倾向于寻找捷径而非严密的逻辑,导致推理过程越来越短,最终丧失推理能力。
核心方法:Actor-Judge 联合建模
为了打破上述困局,该研究引入了两个关键角色:
1. 裁判员的“有界微操” (Judge Modulation)
模型不再盲目相信多数答案。研究者克隆了一个与 Actor 结构相同的冻结模型作为 Judge。Judge 会根据回答的准确性、推理质量和视觉对齐(Visual Grounding)给出一个分值。
- 物理直觉:Judge 的分数不直接作为奖励(防止过拟合 Judge 的偏见),而是作为一个调制器(Modulator)。它利用 Sigmoid 函数对一致性奖励进行微调:表现好的路径被放大,表现差但“合群”的路径被抑制。
2. 组内相对优势 (Group Relative Policy Optimization)
这是本文最有学术深度的地方。作者没有使用绝对分数,而是将一组内(通常是 8 条路径)的所有奖励进行 能量归一化(Energy-based scaling)。
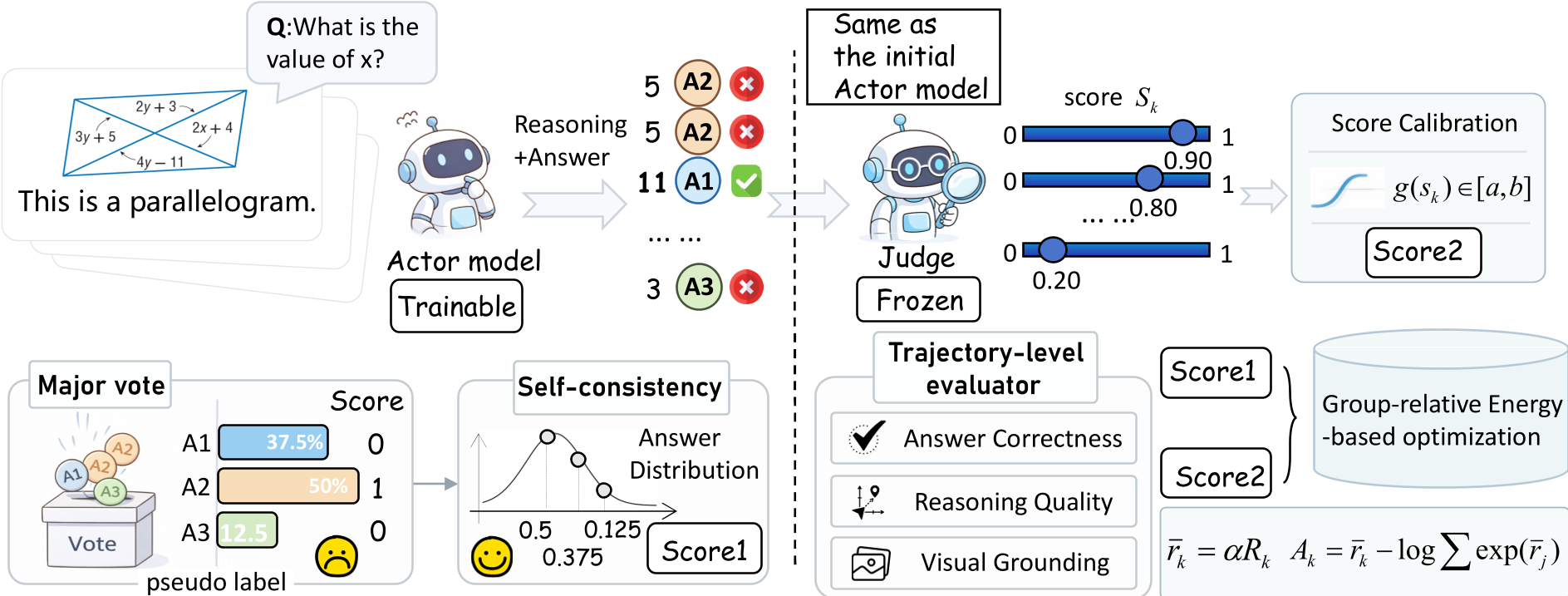
通过最小化 KL 散度,模型的目标从“学习正确答案”变成了“在组内重新分配概率质量”。这意味着:
- 模型不会一蹴而就地锁死在某个答案上。
- 只要组内还有更好的候选路径,模型就会平滑地向其偏移。这样保持了策略的多样性(Entropy),避免了过早的模式坍缩。
实验战绩:无监督胜过有监督?
实验在 Qwen2.5-VL-7B 基础上进行,结果令人振奋:
- 全线飘红:在 MathVision, DynaMath 等五个榜单上,无监督进化后的模型均显著超过了 Base 模型。
- 超越蒸馏:在某些设定下,该无监督方法(30.9%)甚至超过了使用强大教师模型蒸馏的 R1-Onevision 等对手。
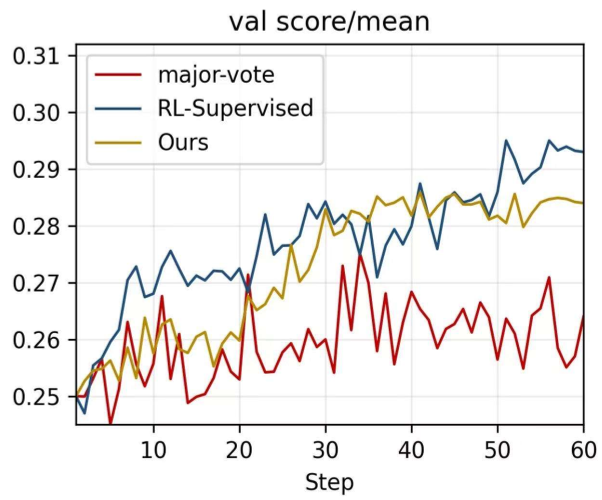
- 训练稳定性:从下图可以看出,相比多数投票(橘色线),本文的方法(蓝色线)在保持准确率增长的同时,**策略熵(Entropy)**下降更为平缓,回复长度也更稳定。
深度洞察:自我进化的边界在哪?
正如资深主编所关注的,这篇论文不仅仅是在刷榜,它揭示了自进化模型的两个深刻逻辑:
- 为什么不直接训练 Judge? 如果 Judge 也在变,整个系统很容易陷入自我强化的正反馈死循环(Self-reinforcing bias),最终导致模型逻辑崩坏。保持 Judge 冻结或使用外部验证是目前的稳健方案。
- 局限性分析: 作者坦诚,当 Actor 对于错误答案达成“极度强烈的共识”且 Judge 也被误导时(例如典型的视觉幻觉),该方法仍会失败。
总结:未来的启示
这篇论文提供了一个非常清晰的 无监督 Scaling Law 路径:即使没有人类标注,只要有海量的未标注多模态数据,通过合理的组内相对优化机制,模型就能实现“左脚踩右脚”的持续飞升。这对于那些垂直领域(如医学影像、特殊工业图纸)缺乏标注数据的场景,具有极高的实战价值。
Takeaway: 别再只盯着单一答案的准确率了,关注推理路径之间的相对结构,才是通往 AGI 推理的钥匙。