本文提出了 MoE-GRPO,这是首个将强化学习(RL)应用于混合专家模型(MoE)路由优化的框架。通过 Group Relative Policy Optimization (GRPO) 算法,该方法将专家选择建模为序列决策问题,在 InternVL3.5-1B 等视觉语言模型(VLM)上实现了性能的显著提升(平均准确度提升约 2%)。
TL;DR
在 Mixture-of-Experts (MoE) 架构中,如何选专家一直是个“贪心”的问题。传统的 Top-K 路由虽然快,但选得死板。本文提出 MoE-GRPO,破天荒地将神经网络内部的专家路径选择看作是一个强化学习任务。通过奖励反馈,模型学会了如何“聪明地”组合专家,不仅在多模态基准测试中刷出了新高度,还解决了 MoE 长期存在的专家过拟合痛点。
背景定位:打破确定性路由的桎梏
目前的视觉语言模型(VLM)为了兼顾规模与效率,纷纷拥抱 MoE 架构。但瓶颈在于:绝大多数模型使用的是确定性 Top-K 路由(Deterministic Top-K Routing)。
- 痛点:这种方式本质上是贪婪选择。如果模型在训练早期认定某几个专家好用,路由就会产生某种“偏见”,导致其他潜力专家被埋没,最终演变为严重的专家过拟合(Expert Overfitting)。
- 直觉:如果把“选哪个专家”看作是强化学习里的“Action”,把“回答准确率”看作是“Reward”,模型是否能通过不停地试错(Exploration),找到比 Top-K 更优的激活路径?
核心内容:MoE 与 GRPO 的深度融合
作者基于 DeepSeek 提出的 GRPO (Group Relative Policy Optimization) 算法,构建了一套端到端的优化流程。
1. 专家选择即决策 (Sequential Decision Making)
在 MoE-GRPO 中,模型的动作空间(Action Space)从单纯的“预测下一个 Token”,扩展到了“为每一层的每个 Token 选择最佳专家序列”。
- Token-GRPO:确保模型生成的答案是正确的(宏观对齐)。
- Gate-GRPO:给路由网络提供密集信号,直接告诉它选哪些专家能获得更高的相对奖励(微观优化)。
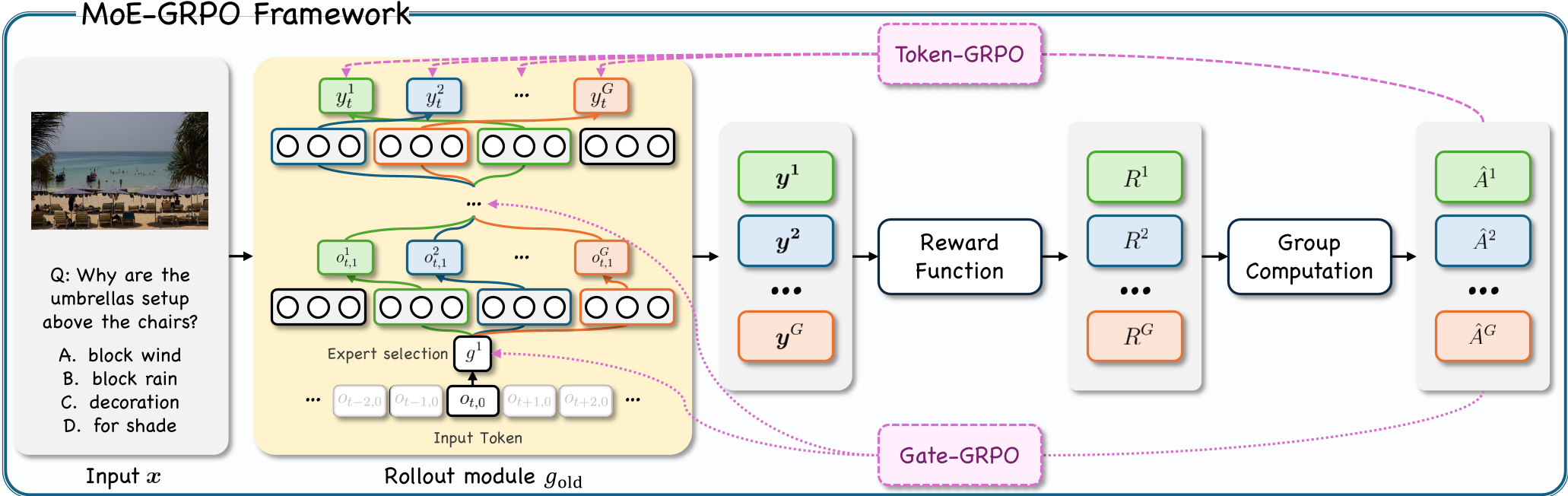 图 1:MoE-GRPO 整体流水线,展示了通过 Rollout 采样不同路径并计算 Advantage 的逻辑。
图 1:MoE-GRPO 整体流水线,展示了通过 Rollout 采样不同路径并计算 Advantage 的逻辑。
2. 模态感知路由引导 (Modality-Aware Guidance)
RL 的探索空间巨大,漫无目的地乱选会导致训练崩溃。作者观察到:视觉 Token 和文本 Token 对专家的偏好天然不同。
- 策略:根据专家在预训练阶段对不同模态的激活频率,计算出“模态觉察分数”。在 RL 探索时,强制“屏蔽”掉那些与其模态匹配度极低的专家(倒数 25%)。这就像是给 RL 训练加了“护栏”,让收敛更稳、更快。
实验战绩:不只是性能提升
研究团队将 InternVL3.5-1B 转换为 MoE 架构进行验证。实验结果显示,MoE-GRPO 在 image 和 video 理解基准上全面超越了传统微调(Det-FT)和随机扰动(Stoch-FT)方法。
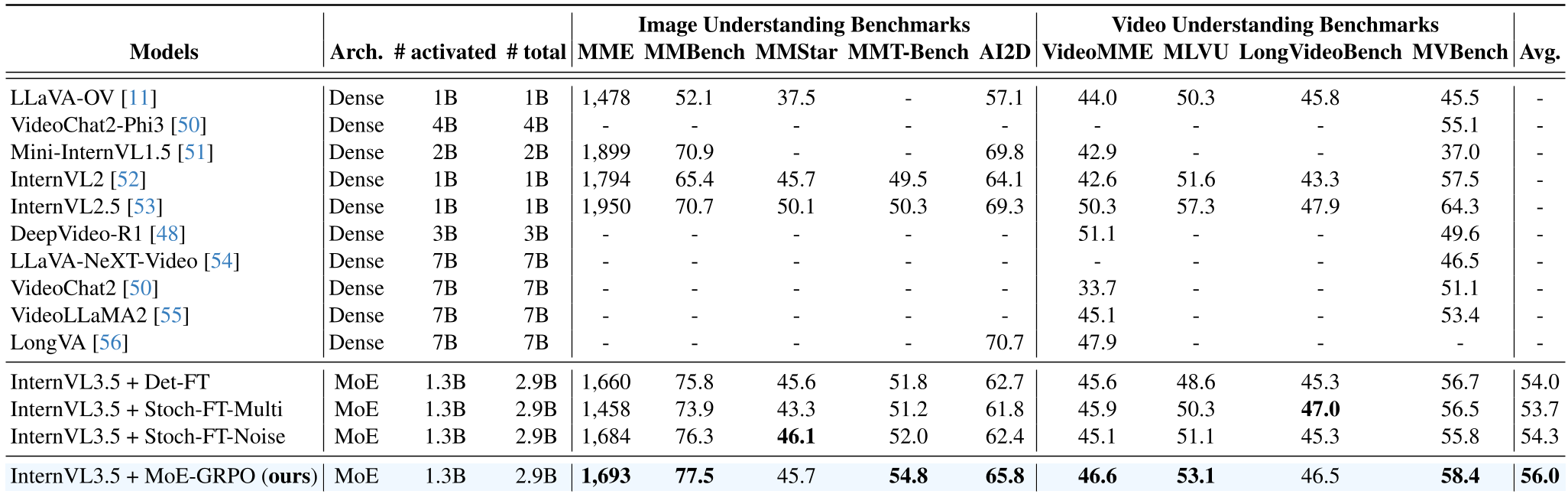 表 1:在 MME, MMBench, MVBench 等多个测试集上,MoE-GRPO 均取得了领先。
表 1:在 MME, MMBench, MVBench 等多个测试集上,MoE-GRPO 均取得了领先。
深度分析:专家真的“变聪明”了吗?
- 多样性增强:如图 4 所示,MoE-GRPO 的专家激活分布更加均匀,熵值从 1.05 飞跃到 1.82。这意味着模型不再只逮着一只羊薅羊毛,而是充分利用了总体的模型容量。
- 任务级特化:分析发现,不同的任务(如视频中的 Action Recognition 对比 Object Interaction)激活的专家组合出现了明显的差异,这证明了模型通过 RL 真正学到了不同任务的底层处理逻辑。
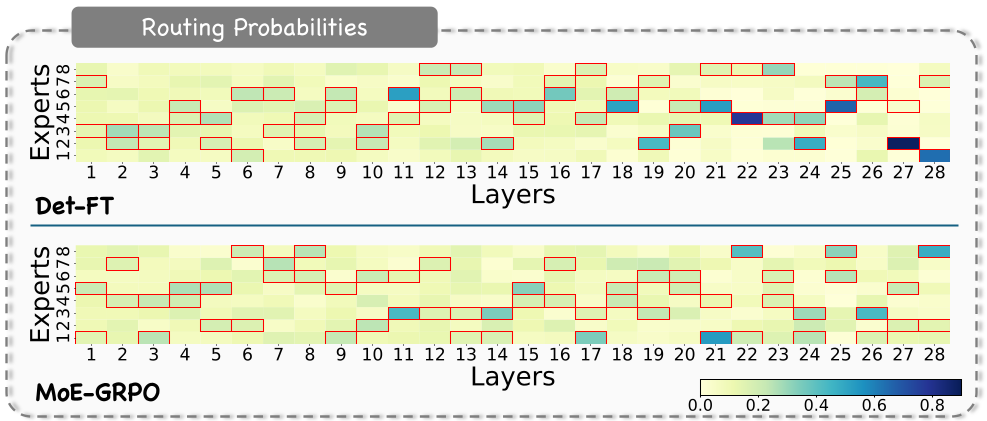 图 4:MoE-GRPO 显著改善了专家利用的均衡性和多样性。
图 4:MoE-GRPO 显著改善了专家利用的均衡性和多样性。
深度洞察与总结
MoE-GRPO 的价值在于它重新审视了 Sparsity (稀疏性) 的本质。
- 从规则到策略:以前我们认为路由是一个由公式定义的静态“选择题”,而现在我们看到它可以是一个动态进化的“策略”。
- 可验证性的红利:该方法高度依赖于“可验证奖励(Verifiable Rewards)”。在数学推理、代码或多项式选择等有明确答案的任务中,这种方法的潜力被放到了最大。
局限性:由于需要多次采样(G=8)进行 Rollout,训练期间的显存占用和计算开销不容小觑。此外,对于答案开放的生成式任务,如何构建更精准的 Reward 依然是未来的挑战。
总结:MoE-GRPO 为如何高效利用模型参数提供了一个全新的视角,是 MoE 走向精细化运营的重要一步。