本文提出了 MosaicMem,一种用于可控视频世界模型(World Models)的混合空间记忆机制。该方法通过一种“Patch-and-Compose”接口,将视频片段提升为 3D 补丁,结合了显式几何定位的可靠性与隐式注意力机制的动态生成能力,实现了长时程、高一致性且支持相机控制的视频生成。
TL;DR
MosaicMem 彻底解决了视频生成模型在“长周期导航”中常见的视觉漂移和记忆缺失问题。它通过将视频 Patch 提升至 3D 空间,创造了一种“拼贴画(Mosaic)”式的记忆管理机制,既保留了 3D 结构的严谨性,又维持了扩散模型处理动态场景的灵活性。在 2 分钟的长路径生成任务中,它展现了惊人的场景复现能力。
核心速览
随着 Sora 和 Genie 的出现,视频生成正在从单纯的“短片合成”转向“世界模型”的构建。一个真正的世界模型必须具备物体恒常性(Object Permanence)和环境一致性。
本文在领域坐标系中属于空间记忆(Spatial Memory)的架构革新。它打破了单纯显式(Explicit)几何重建和单纯隐式(Implicit)特征记忆的对立,开创了 Patch 级别的混合记忆范式。
痛点与动机:为什么你的 AI 视频走两步就“串味”?
在之前的研究中,AI 视频模型在处理“回头看(Revisit)”场景时经常崩溃,主要原因有两个:
- 显式记忆(如 GEN3C)的僵硬性:就像给场景建了一个 3D 模型,背景很稳,但人不会动了,且 3D 重建误差会随时间不断积累。
- 隐式记忆(如 CaM)的随机性:虽然动态效果好,但由于缺乏硬约束,生成模型在几次相机移动后就会彻底忘记背后的场景,产生严重的“空间漂移”。
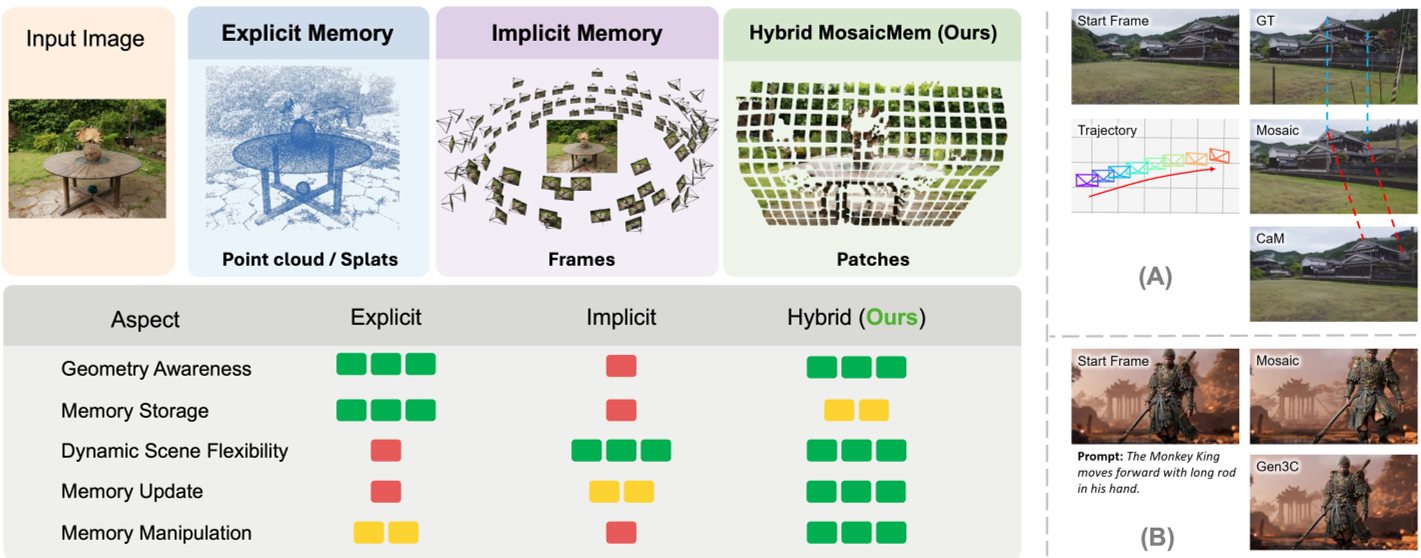
核心方法:MosaicMem 的“拼贴”艺术
MosaicMem 的核心直觉在于:将记忆分解为独立的 3D Patch。
1. Patch-and-Compose 接口
系统不再存储整帧图像,而是利用 3D 估计器将每一个视频小块(Patch)投影到 3D 空间。当相机移动到新视角时,模型会根据当前的 3D 坐标,精准地从“记忆库”中提取出对应的 Patch 拼贴在画布上。未覆盖的区域则交由扩散模型进行 Inpainting,实现动态更新。
2. 双重对齐机制
为了解决 VAE 压缩导致的精度损失,作者设计了两种对齐策略:
- Warped RoPE:在位置编码层面,利用重投影逻辑(Perspective Projection)调整其在注意力机制中的坐标。
- Warped Latent:在特征层面,直接对记忆 Patch 进行双线性插值采样,确保物理位置的绝对重合。

3. PRoPE 相机控制
作者引入了投影位置编码(PRoPE),将相机投影矩阵直接注入 DiT 的 Self-Attention 模块。这使得模型能精确感知“我正从哪个角度看这个世界”。
实验与结果:全方位的 SOTA
研究团队在自建的 MosaicMem-World 基准测试集上(包含游戏、真实世界及 UE5 模拟数据)进行了压测。
| 指标 | 显式基线 (GEN3C) | 隐式基线 (CaM) | MosaicMem (Ours) | | :--- | :--- | :--- | :--- | | 相机旋转误差 (RotErr ↓) | 1.61° | 4.65° | 0.51° | | 位移误差 (TransErr ↓) | 0.13 | 0.43 | 0.06 | | 一致性评分 (SSIM ↑) | 0.64 | 0.49 | 0.75 |
深度洞察
- 动态物体的胜利:相比显式方法只能渲染静态背景,MosaicMem 能在回头时依然生成“ medieval knight riding a horse”等复杂的动态叙事。
- 实时性飞跃:通过 Mosaic Forcing(自回归蒸馏技术),模型在保持高一致性的同时,达到了 16 FPS 的实时生成速度。

场景编辑:上帝视角的手动干预
由于记忆是基于 3D Patch 存储的, MosaicMem 展现了极强的可操控性。用户可以直接删除、复制甚至重新定位记忆中的 Patch(如将地面建筑“垂直翻转”到天空中),从而创造出如《盗梦空间》般的超现实视频效果。

总结与局限 (Takeaway)
MosaicMem 成功将 3D 近似与生成式注意力机制融合。其贡献不只是刷榜,更在于证明了**局部 3D 约束(Patch-based)优于全局 3D 重建(Global Constrained)**的灵活性。
局限性:尽管 Patch 拼贴效果惊人,但在极端大范围场景(如从室内到整座城市)的 Patch 索引效率仍有待提升。此外,对于高度非刚性变形(如流体)的 3D 提升精度仍受限于底层 depth 估计器的水平。
未来,这一框架有望成为自动驾驶仿真、交互式 3D 游戏生成的核心组件。