Motion-o is a trajectory-grounded video reasoning framework that introduces a "Motion Chain of Thought" (MCoT) to vision-language models. It bridges discrete spatio-temporal observations using explicit, verifiable motion tags, achieving SOTA performance on V-STAR (36.6 mAM) and VideoMME (69.7 overall).
TL;DR
While state-of-the-art Video-LLMs are getting better at spotting objects in specific frames, they remain remarkably "blind" to the dynamics of how objects move between those frames. Motion-o fixes this by introducing Motion Chain of Thought (MCoT)—an explicit reasoning step that forces models to articulate velocity, direction, and scale changes. By training with a unique "Dual-Chain Verification" reward, the model learns to actually watch the video rather than hallucinating plausible trajectories.
The Problem: Implicit Dynamics and "Static Priors"
In traditional video reasoning, a model might say: "The man is at point A at 1.0s and at point B at 2.0s." While spatially correct, the underlying motion remains a "black box" of internal interpolation. Models often take shortcuts:
- Textual Priors: Guessing a car is "moving fast" simply because it's a car on a highway.
- Implicit Interpolation: Failing to recognize complex arcs or sudden accelerations because they only look at frozen snapshots.
The authors identify this as a lack of Spatial-Temporal-Trajectory (STT) reasoning. Without explicit trajectory modeling, we cannot verify if a model truly understands the physics of the scene.
Methodology: The Motion Chain of Thought (MCoT)
Motion-o extends the standard reasoning trace (think-block) with a structured <motion/> operator. After observing an object across multiple timestamps, the model must output:
<motion obj="duck" dir="E" speed="moderate" scale="stable"/>
The STT Framework
The architecture focuses on three pillars of evidence:
- Spatial: Where is it? (Bounding boxes)
- Temporal: When is it? (Timestamps)
- Trajectory: How did it get from to ? (Direction, Speed, Scale change)
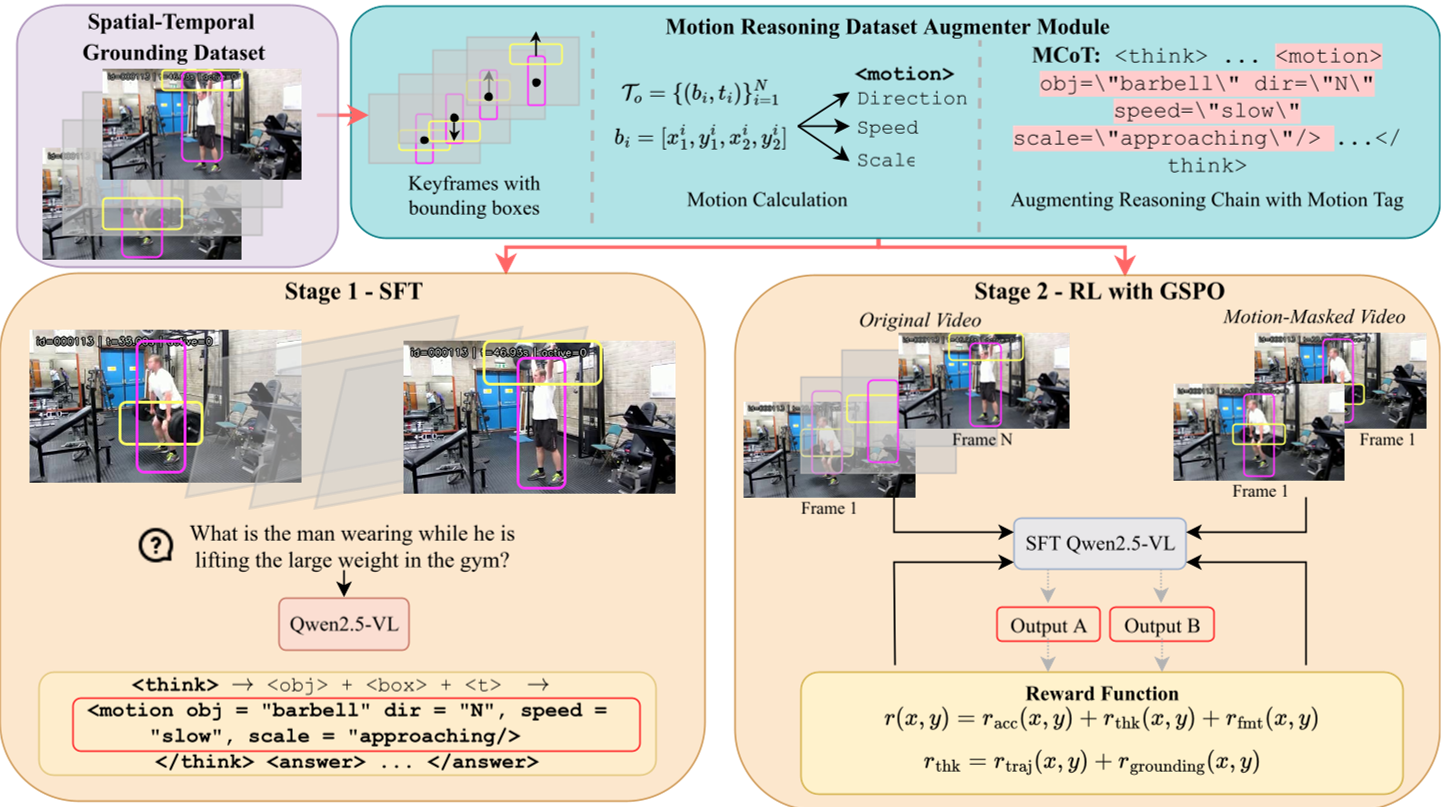
Training with Reinforcement Learning
To ensure these motion tags aren't just guesses, the authors use Group Sequence Policy Optimization (GSPO) with a clever Dual-Chain Verification reward:
- Trajectory Reward: Cross-references predicted tags with ground-truth bins derived from dense tracks.
- Visual Grounding Reward: The model is fed a "motion-masked" video (frozen frames). If the model's motion description remains the same when the video is frozen, it is penalized for relying on priors rather than visual evidence.
Experiments: Crushing Motion-Specific Benchmarks
The results show that making motion explicit doesn't just help with "motion questions"—it boosts general video understanding.

- V-STAR Improvement: Achieving 36.6 mAM, significantly outperforming GPT-4o (26.8) and specialized models like Sa2VA.
- MotionBench: A massive leap to 63.0, nearly doubling GPT-4o's score (33.0).
- Efficiency: This is achieved without architectural changes to the base Qwen2.5-VL model, proving that structured reasoning is a software-level breakthrough.
Critical Analysis: The Qualitative Shift
In the qualitative examples, Motion-o demonstrates an ability to distinguish between actual motion and camera motion. Because it grounds multiple points, it can tell if an object is stationary even if the camera is panning (viewpoint change robustness).

Limitations & Potential
- Spatial Jitter: The authors acknowledge that since the base model isn't a native object detector, the bounding boxes can sometimes be "noisy," even if the motion reasoning is correct.
- Complexity: Currently, the model handles linear/simple trajectories well. Future work is needed for complex, non-linear interactions (e.g., a ball bouncing multiple times).
Conclusion: Making Video "Video" Again
Motion-o reminds us that a video is not just a collection of images—it is a continuous manifold of movement. By forcing Large Multimodal Models to articulate the vectors of existence, we move closer to AI that perceives the world with the same causal and physical continuity that humans do.
Key Takeaway: Don't just ask your model what is in the video; train it to explain how it's moving, and use motion-masking to prove it's actually looking.