本文提出了 Motion-o,一个专注于动态推理(Motion Reasoning)的视频理解框架。通过引入“运动思维链”(Motion Chain of Thought, MCoT),该模型在 spatio-temporal 证据链中显式加入追踪物体的方向、速度和比例变化标签,在 V-STAR 和 VideoMME 等基准测试中刷新了 SOTA 性能。
TL;DR
尽管现有的视频理解模型(如 GPT-4o, Qwen2-VL)已经能精准定位物体(Where)和时间点(When),但它们对于物体如何移动(How)的理解依然是模糊且不可观测的隐含过程。Motion-o 通过引入运动思维链(Motion Chain of Thought, MCoT),首次将物体的轨迹动态信息(方向、速度、缩放)转化为可验证的结构化标签。通过强化学习(RL)与双链验证机制,Motion-o 在不改变模型架构的前提下,显著提升了模型在复杂视频推理任务中的表现。
1. 痛点:被忽视的“空间-时间-轨迹”三位一体
在人类视觉感知中,运动是理解世界的灵魂。我们不仅看到车在 A 点和 B 点,更能感知它是“快速加速”还是“平滑转弯”。
然而,目前的证据型视频模型(Evidence-based Models)存在严重缺陷:
- 静态先验依赖:模型通过 A 帧和 B 帧的语义信息猜测中间过程,而非真正观察动态。
- 轨迹隐性化:模型输出的证据链仅包含离散的 Bounding Box 快照,缺乏描述动态演进的“语义胶水”。
- 验证困难:无法判断模型给出的“物体向左移动”是基于像素流的观察,还是基于“人通常向左走”的文本概率。
2. 核心贡献:Motion Chain of Thought (MCoT)
为了解决上述问题,作者提出了 Spatial-Temporal-Trajectory (STT) 推理框架,其核心是 <motion/> 标签。
显式运动算子
在模型的推理流(Think 标签内)中,每当对同一物体完成两次及以上的定位后,必须插入一个 <motion/> 标签:
- dir (Direction):8 方向罗盘指引 + 静止态。
- speed:静止、慢速、中速、快速。
- scale:接近(Approaching)、稳定、远离(Receding)。
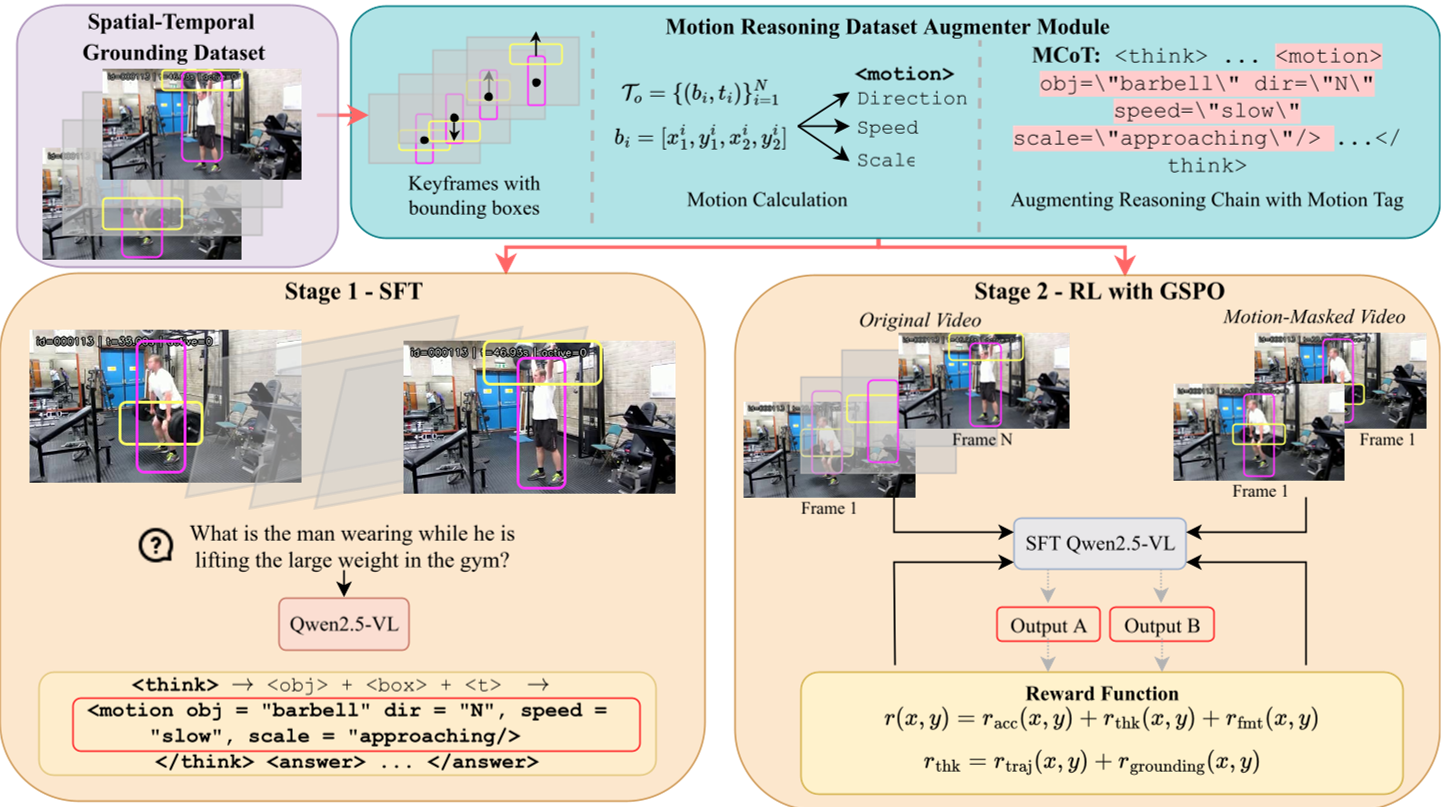
这种设计将连续的像素运动抽象为离散的、模型易理解的符号,使得视觉动态成为了推理链的一部分。
3. 训练策略:轨迹增强与强化学习
高性能的运动推理离不开高质量的数据与精准的奖惩机制。
轨迹接地数据集(Trajectory-Grounding Artifact)
现有的数据集标注过于稀疏(Sparse Keyframes)。作者设计了一种扩增方法,通过对 Perception-LM 等数据集进行插值和稠密化,生成连续的物体轨迹(Tracks),计算出真实运动属性并注入 SFT 语料库。
强化学习:双链验证(Dual-Chain Verification)
这是 Motion-o 最具洞察力的设计。为了防止模型“偷懒”(即不看视频只靠猜),作者引入了两种奖励:
- 轨迹奖励 (r_traj):预测标签与真实物理轨迹的匹配度。
- 视觉接地奖励 (r_ground):将同一视频的冻结帧版本输入模型。如果模型在没有动力的视频中依然预测出相同的运动标签,则给予惩罚。这种“反事实”训练强制模型必须提取视觉时间差信息。

4. 实验战绩:让 VLM 更像“物理学家”
Motion-o 在多个权威榜单上展现了极强的泛化能力:
- V-STAR (Spatio-temporal Grounding):全面超越 GPT-4o 和专业模型 Sa2VA。特别是视觉 IoU(Where)指标,相比基础模型提升了近一倍。
- VideoMME:在综合视频理解能力上提升了 6.1 分。
- 消融实验显示:
- 离散化 vs 连续值:使用离散标签(如 "fast")效果远好于连续数值坐标(如 "0.14m/s"),因为后者对语言模型而言过于抽象,难以收敛。
- 标注密度:稀疏标注会导致模型无法理解复杂的非线性运动。

5. 局限与未来
尽管 Motion-o 推理能力出众,但它对 Bounding Box 的定位精度仍受限于底层 VLM 的 Backbone(本论文使用 Qwen2-VL-7B)。作者诚实地指出,在某些复杂场景下,虽然预测的运动趋势(方向/速度)是正确的,但 Box 框得不够紧凑。
总结:Motion-o 证明了,视频理解不应仅是对像素的判别,更应是对物体演进逻辑的显式重构。通过 MCoT 这种轻量级扩展,我们离“拥有物理直觉的 AI”又近了一步。
关键词:Video Reasoning, Motion-o, Reinforcement Learning, MCoT, Trajectory-Grounded