The paper introduces MPDiT, a Multi-Patch Global-to-Local Diffusion Transformer that optimizes DiT architectures using a hierarchical design. It processes large patches in early blocks to capture global context and small patches in later blocks for local refinement, achieving SOTA results with significantly reduced computation.
Executive Summary
TL;DR: MPDiT (Multi-Patch Diffusion Transformer) breaks the isotropic tradition of DiT architectures by introducing a hierarchical global-to-local design. By processing coarse global structures with large patches and refining details with smaller patches, the model reduces GFLOPs by up to 50% and accelerates convergence by over 11x, achieving superior FID scores on ImageNet-256 and 512.
Background: While Transformers have superseded UNets in generative tasks, the quadratic cost of self-attention remains a bottleneck for high-resolution synthesis. MPDiT is a structural SOTA-bound modification that rethinks how spatial information should flow through a Diffusion Transformer.
Problem & Motivation: The Isotropic Tax
Existing Diffusion Transformers (e.g., DiT, SiT) are isotropic: they treat all tokens equally from the first layer to the last. This is computationally wasteful because:
- Early layers primarily focus on global layout and coarse structures, which don't require high-resolution token grids.
- Late layers refine textures and local edges, which do require density.
Furthermore, the authors identified that standard time embeddings (linear MLPs) and class embeddings (single tokens) are too "shallow" to capture the complex ODE/SDE dynamics of flow matching.
Methodology: The Global-to-Local Architecture
The core innovation is the Multi-Patch Transformer pipeline. Instead of fixed tokenization, the model employs a two-stage strategy:
- Global Stage (N-k blocks): Uses a large patch size (p=4), resulting in only 64 tokens for a latent grid. This drastically cuts the quadratic attention cost.
- Upsample & Refine (k blocks): An "Upsample Block" expands tokens to a finer resolution (p=2, 256 tokens). A skip connection from the original latent ensures no fine-grained detail is lost. Only the last few blocks (k=6) operate at this high-density token count.
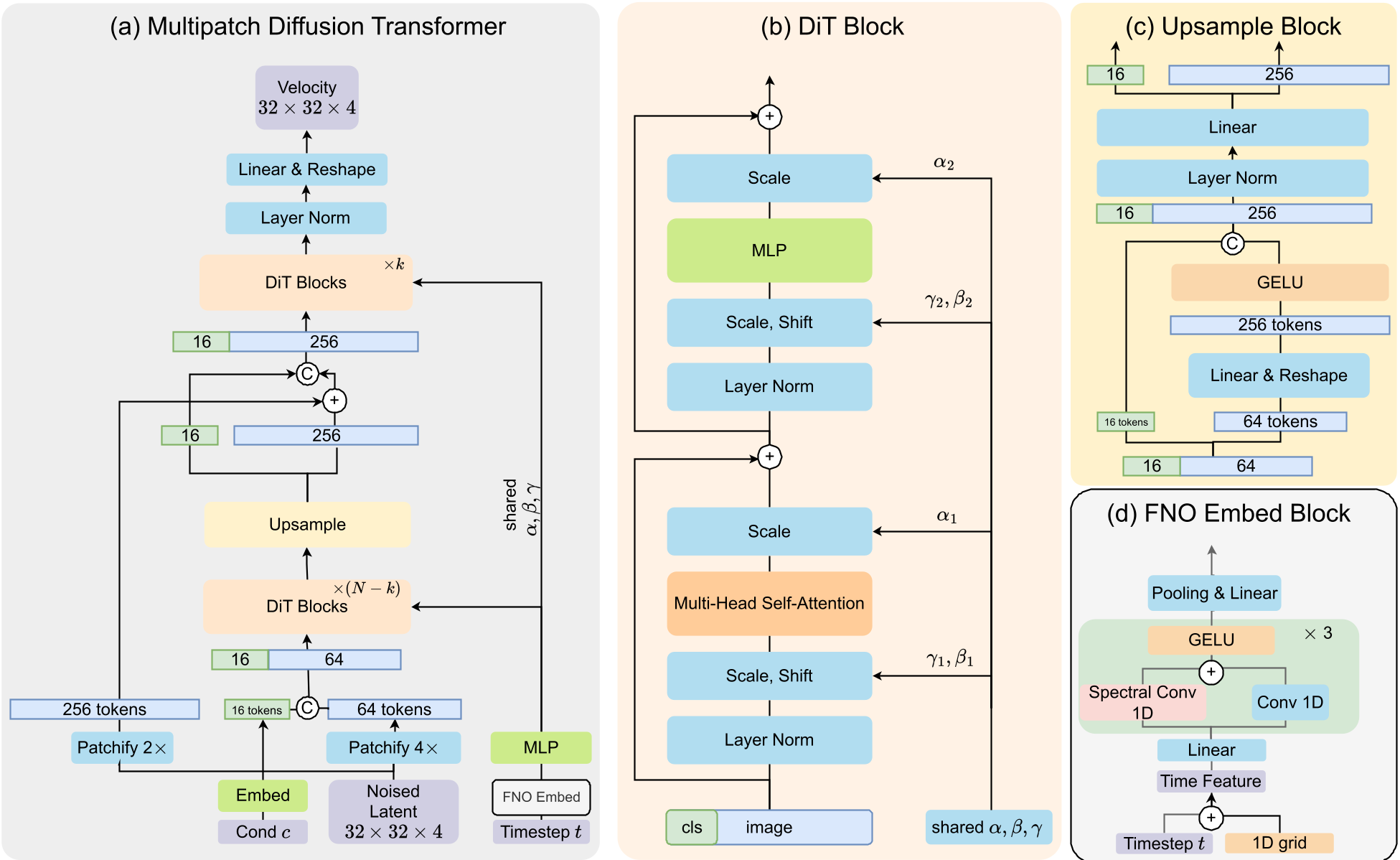
Advanced Conditioning
- FNO Time Embedding: Inspired by Neural Operators, the authors use a 1D spectral convolution (MixedFNO) to learn smooth transitions across timesteps, providing a more continuous representation of the flow field.
- Multi-token Class Embedding: Prepending multiple learnable tokens (m=16) instead of one allows the model to capture richer semantic relationships between labels and spatial features.
Experiments & Results: 11x Faster Convergence
MPDiT was benchmarked extensively on ImageNet. The results are striking because they improve both quality and speed simultaneously.
- ImageNet-256: MPDiT-XL achieves a cfg-FID of 2.05 in just 240 epochs. For comparison, SiT needs 1,400 epochs to reach similar quality.
- ImageNet-512: The efficiency gains are even more pronounced. MPDiT-XL reaches an FID of 2.47 using only ~43.5% of the GFLOPs of DiT-XL/2.
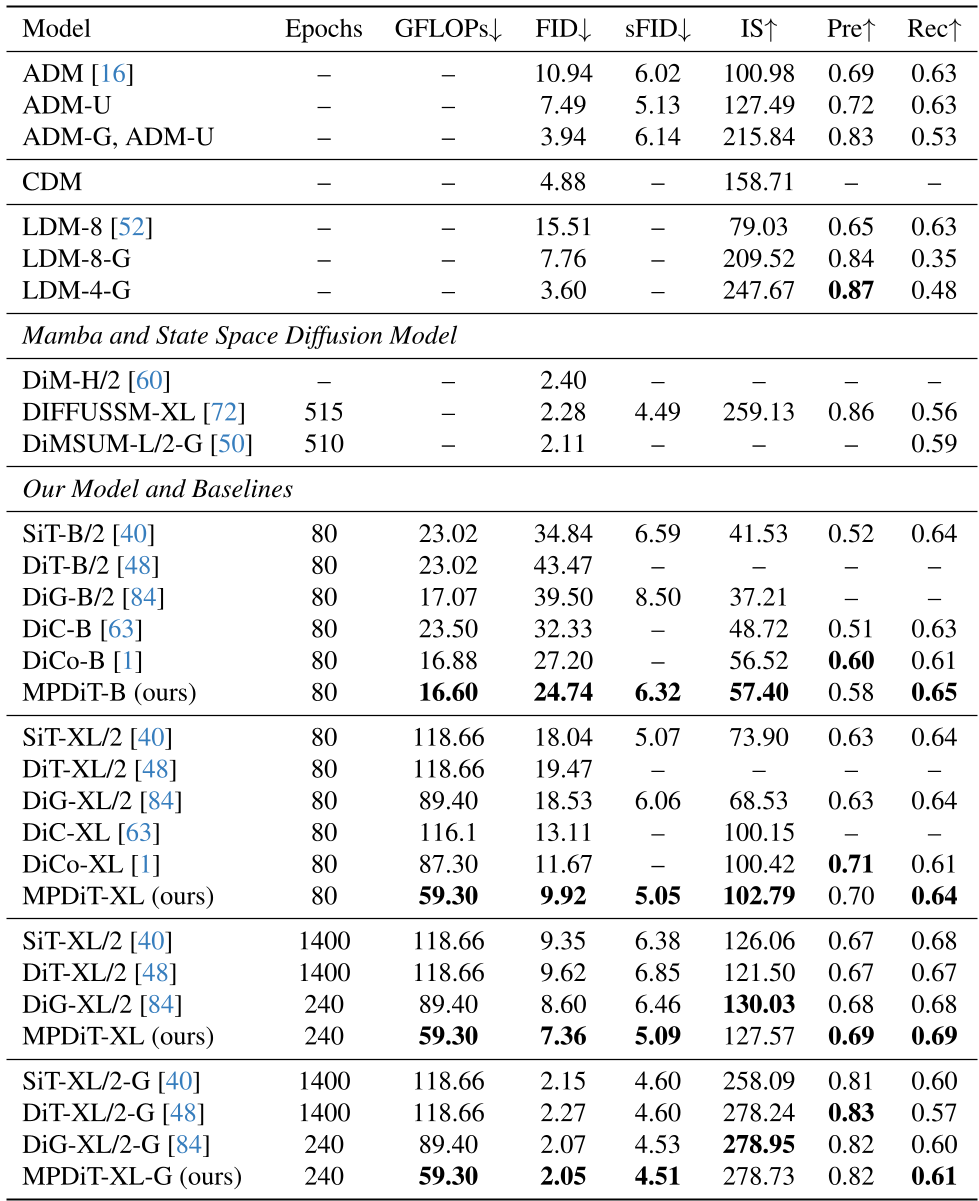
Ablation Insights
The ablation study highlights that the Multi-patch strategy (GFLOPs reduction) and the FNO/Multi-token conditioning (FID improvement) are complementary. Switching to multiple class tokens alone provided a massive ~7 point FID drop, while FNO added another ~4 points.
Critical Analysis & Conclusion
Takeaway: MPDiT proves that we don't need "all tokens all the time." By aligning the architectural resolution with the natural generative process (coarse-to-fine), we can slash training budgets without sacrificing SOTA performance.
Limitations: While the efficiency gains are clear on ImageNet, the application to massive-scale Text-to-Video models (like Sora or Flux) is mentioned as future work. These "ultra-long" sequence tasks will truly test the limits of the Upsample Module’s ability to maintain coherence.
Future Outlook: We expect to see this hierarchical approach become the standard for high-resolution latent models (1K and beyond), where full-token attention is otherwise prohibitive.