本文提出了 MSR-HuBERT,一个自监督语音预训练框架,旨在解决现有模型(如 HuBERT)在大规模混合采样率数据下存在的“分辨率失配”问题。该方法通过引入多采样率自适应下采样 CNN,实现了 16kHz 至 48kHz 音频的统一表示学习。
TL;DR
在语音处理领域,自监督学习(SSL)已成为主流。然而,HuBERT、WavLM 等经典模型一直深受“采样率歧视”之苦:它们通常只能处理 16kHz 音频。本文提出的 MSR-HuBERT 通过一种巧妙的自适应下采样 CNN 架构,首次在不进行重采样(Resampling)的前提下,实现了对 16kHz 到 48kHz 多样化采样率音频的统一预训练与微调,在语音识别(ASR)和全频段语音重建(SR)任务上均取得了显著提升。
痛点深挖:消失的分辨率对齐
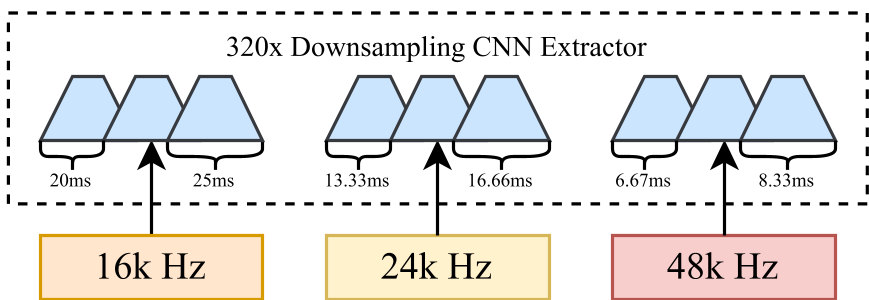
现有的语音 SSL 模型设计中存在一个潜规则:320 倍下采样。
- 对于 16kHz 音频,320x 下采样对应 20ms 的帧移(Frame Shift);
- 但如果输入 48kHz 音频,同样的 320x 下采样会导致帧移变为 6.67ms。
这种**分辨率失配(Resolution Mismatch)**导致模型在处理非 16kHz 音频时,特征序列的时间轴被拉长或缩短,使得预训练学到的 Transformer 参数完全失效。传统做法要么强行重采样(导致 48kHz 的高频细节永久丢失),要么为每个采样率单独练模型(成本爆炸)。
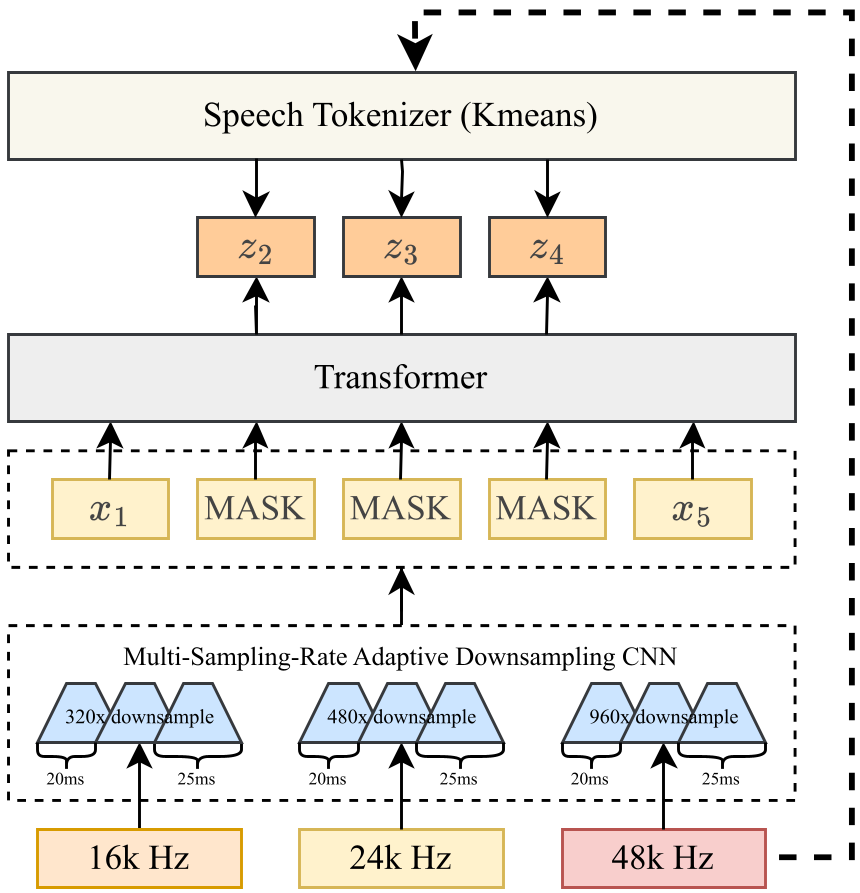
核心思路:多采样率自适应下采样
MSR-HuBERT 的核心直觉非常纯粹:让前端 CNN 去适应采样率,而不是让采样率去适应 CNN。
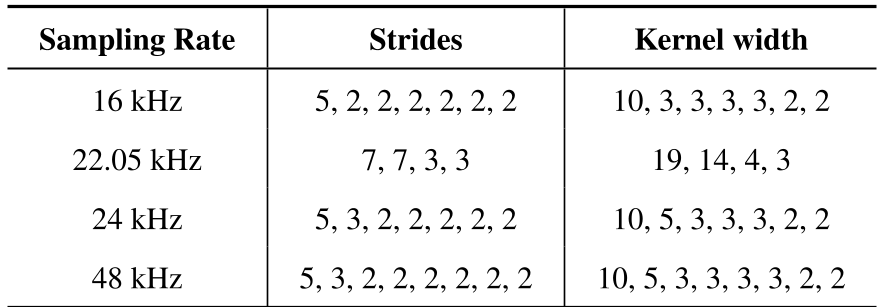
1. 动态步长设计
作者通过精细设计不同分支的 Stride 和 Kernel Width(如下表所示),确保无论输入是 16k、22.05k、24k 还是 48k,经过卷积层后的特征序列都严格锁定在 20ms 这一物理时长单位上。
2. 共享特征空间
为了让 Transformer 能够同时理解来自不同分支的特征,作者在每个 CNN 路径后添加了 Layer Normalization (LN)。这一步至关重要,它独立地归一化各分支的均值和方差,消除了因采样率不同带来的特征量纲差异,使得混合采样率数据可以共享一套 Codebook 和 Encoder。
实验战绩:既能“听懂”,也能“画好”
论文对比了 MSR-HuBERT 与传统 HuBERT 在两种截然不同的任务上的表现:
- ASR(语音识别):关注低频语义结构。
- SR(语音重建):关注高频声音细节。
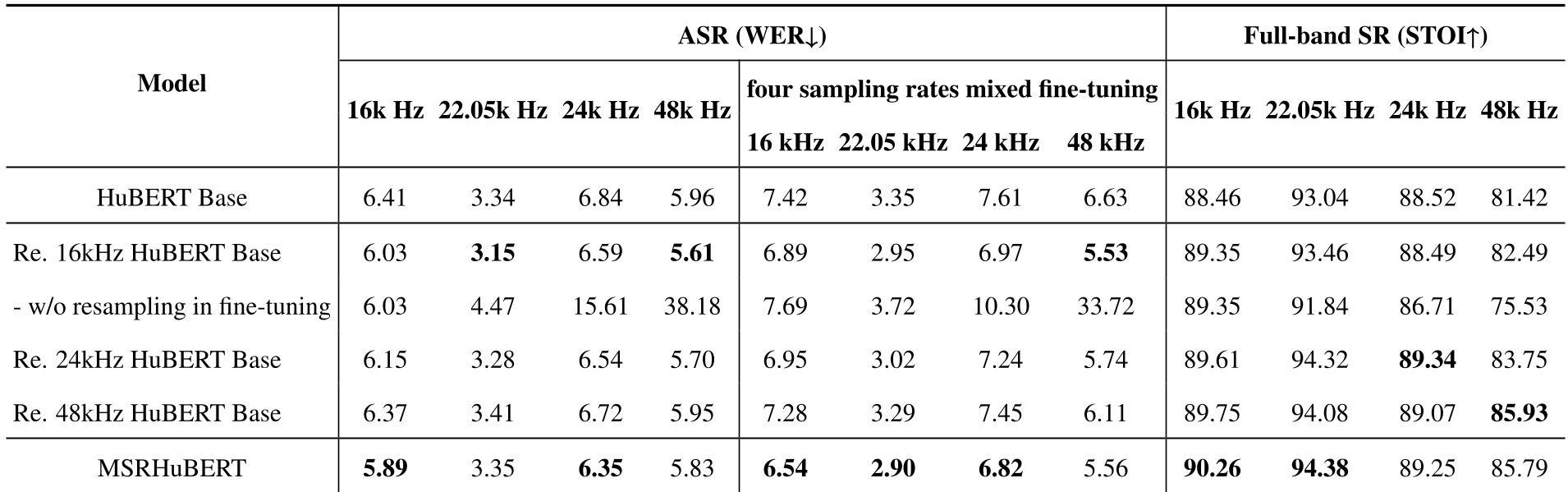
关键发现:
- 高频信息的力量:此前人们认为 16kHz 足够 ASR 使用,但实验证明保留高频信息(不重采样)能提供更好的归纳偏置,MSR-HuBERT 在 24kHz 下的 WER(词错率)比 16kHz 模型更低。
- 跨率稳健性:当发生采样率失配(即用 16k 模型处理 48k 测试集且不重采样)时,性能会发生毁灭性跌落(WER 从 6% 飙升至 38%);而 MSR-HuBERT 完全免疫此类问题。
- 兼容性:MSR-HuBERT 完美继承了 HuBERT 的中间层特性,直接插拔现有的优化技术(如 Intermediate Layer Supervision)依然能获得额外增益。
深度洞察
MSR-HuBERT 的成功在于它识破了语音信号处理中的一个误区:我们不应该为了适配模型而牺牲数据的原始分辨率(Shannon 采样定律带来的信息增益)。通过在前端增加极其轻量(参数量仅增 3%)的分支,它换取了模型对整个音频频谱的感知能力。这对于未来构建统一的、支持高保真音频处理的多模态大模型具有重要的参考价值。
局限性:虽然目前覆盖了常见的 16k-48k 采样率,但对于任意非标准的采样率,仍需手动配置其 CNN 步长。未来的方向可能是引入更具通用性的重采样核(Resampling Kernel)学习机制。