This paper introduces Multi-Resolution Fusion (MuRF), a universal, training-free inference strategy that enhances Vision Foundation Models (VFMs) like DINOv2 and SigLIP2. By fusing features from multiple input resolutions (low-res for global context and high-res for local detail), MuRF achieves state-of-the-art performance across semantic segmentation, depth estimation, MLLM-based VQA, and unsupervised anomaly detection.
TL;DR
Vision Foundation Models (VFMs) like DINOv2 are typically used at a single scale during inference, which forces a compromise between global "recognition" and local "refinement." Multi-Resolution Fusion (MuRF) breaks this paradigm by processing images at multiple scales through a frozen encoder and concatenating the features. This simple, training-free strategy delivers significant SOTA boosts in segmentation, depth estimation, and anomaly detection.
The "Recognition vs. Refinement" Dilemma
In the current VFM landscape, we often assume that "higher resolution is better." However, MuRF identifies a fundamental trade-off:
- Low Resolution: Larger relative patch sizes mean the model sees the "big picture," leading to better global semantic recognition.
- High Resolution: Fine-grained details are preserved, which is essential for precise boundaries/refinement, but the model can become "distracted" by noise or lose the object's interior context (the "hole" problem).
 Figure 1: Notice how the interior of the sheep in the high-res PCA (right) becomes noisier, while the low-res (left) is smoother but blurry at the edges.
Figure 1: Notice how the interior of the sheep in the high-res PCA (right) becomes noisier, while the low-res (left) is smoother but blurry at the edges.
Methodology: Synergy through Concatenation
MuRF's approach is deceptively simple but grounded in a key insight regarding feature space. Instead of modifying the model or its weights, MuRF acts as a feature extraction wrapper:
- Input Pyramid: Resize the input image into multiple scales (e.g., 0.5x, 1.0x, 1.5x original).
- Frozen Encoding: Pass each scale through the SAME frozen VFM (DINOv2, SigLIP2, etc.).
- Spatial Alignment: Bilinearly upsample all feature maps to a shared resolution.
- Channel Fusion: Concatenate the maps along the channel dimension.
Why Concatenate? The authors argue that summation or pooling causes "destructive interference." By concatenating, scale-specific activations (macroscopic vs. microscopic) stay independent, allowing the lightweight task-head to learn which scale to prioritize for which pixel.
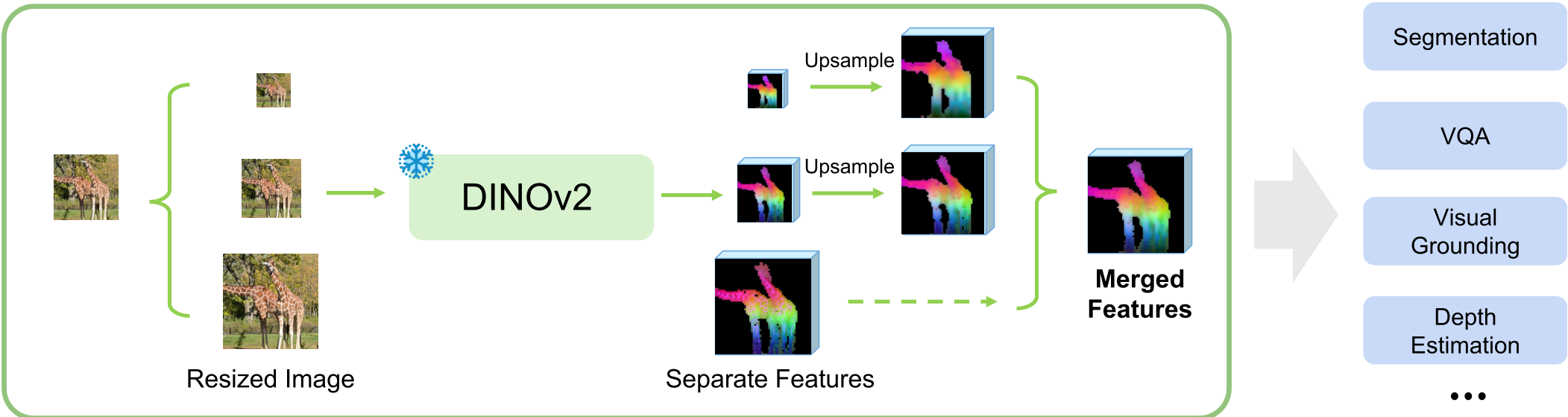 Figure 2: The MuRF pipeline. Multiple resolutions enter; one unified, scale-robust representation comes out.
Figure 2: The MuRF pipeline. Multiple resolutions enter; one unified, scale-robust representation comes out.
Experimental Wins: A Universal Upgrade
The researchers tested MuRF across a massive spectrum of tasks. The results were consistently superior to single-scale baselines.
1. Dense Prediction (Segmentation & Depth)
On ADE20K and PASCAL VOC, MuRF outperformed single-scale DINOv2 by large margins. In depth estimation, RMSE dropped by 6.6% on NYU Depth V2. The fusion essentially "fills the holes" created by high-res noise while sharpening the blurs created by low-res inputs.
2. Multimodal LLMs (VQA)
By using MuRF features as tokens for LLaVA, the model showed better "cognitive" performance. Crucially, they upsampled the features before the projection layer, ensuring the LLM received the same number of tokens as the baseline—meaning zero extra LLM computational cost for a significant intelligence boost.
3. Anomaly Detection (Industrial Inspection)
In a training-free setting on MVTec AD 2, MuRF-AD achieved state-of-the-art results. It solves the classic industrial problem where you need to detect both tiny scratches (high-res) and large structural missing parts (low-res) simultaneously.
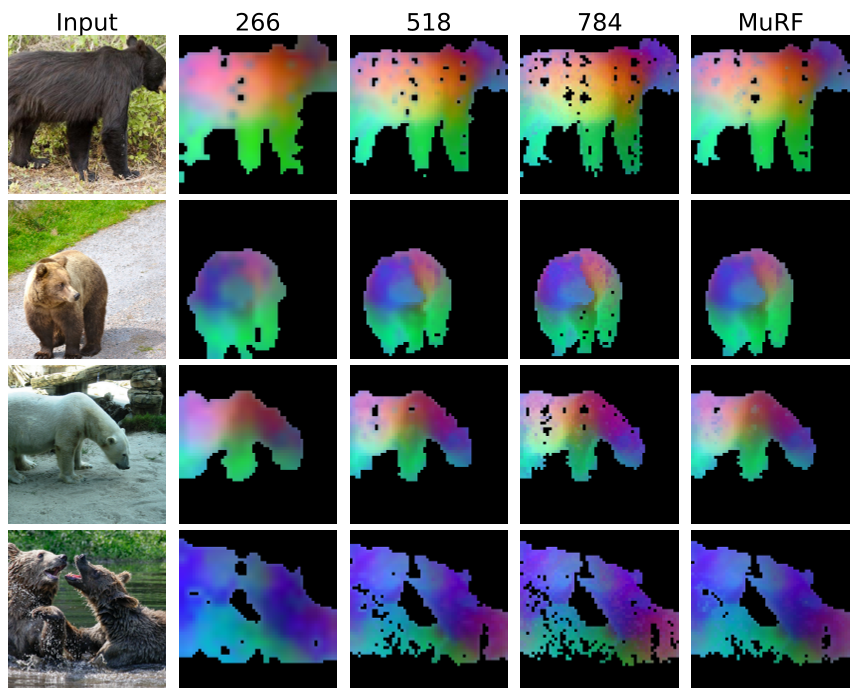 Figure 3: The "Merged" (MuRF) mask captures the full extent of the defect while maintaining sharp edge precision.
Figure 3: The "Merged" (MuRF) mask captures the full extent of the defect while maintaining sharp edge precision.
Deep Insight: Multi-Resolution > Multi-Layer?
Interestingly, the paper compares MuRF to "Multi-Layer" concatenation (using middle layers of a Transformer). MuRF performed better at capturing fine-grained structural detail (Metric Depth), while multi-layer features were slightly better at zero-shot generalization. However, the best results came from combining both, proving that scale and depth are orthogonal axes of information.
Conclusion & Limitations
MuRF is a powerful reminder that inference strategy is just as important as training architecture. By simply changing how we feed data into frozen VFMs, we can achieve gains that usually require expensive retraining.
- Limitations: The primary cost is increased VRAM and FLOPS during the encoding stage (processing the image multiple times). However, because the VFM is frozen, this is a linear cost and is often negligible compared to the downstream LLM or complex heads.
- Future Impact: As MLLMs move toward higher-resolution vision, MuRF provides a more robust alternative to simple "tiling" or "upsampling" methods.