本文提出了 NavOne,一种针对视觉语言导航 (VLN) 的一阶段全局规划框架。该方法将导航任务重新表述为在预建多模态俯视图(RGB、占据空间、语义)上的路径预测问题,实现了 SOTA 性能及极高的推理速度。
TL;DR
在 Embodied AI 领域,Vision-Language Navigation (VLN) 一直被视为一个复杂的序列决策问题。然而,NavOne 打破了这一惯例。它不再要求机器人“走一步看一步”,而是通过预建的 Top-Down Map(俯视图),像人类查看地图规划路线一样,在单次前向传播中直接生成完整的导航路径。该方法不仅在精度上达到 SOTA,更在效率上实现了 80 倍 的降维打击。
1. 痛点深挖:为什么“边走边看”不是唯一解?
传统的 VLN 代理通常采用以自我为中心 (Egocentric) 的视角,这种“第一人称”模式面临三大痛点:
- 误差累积 (Error Accumulation):每一步决策的微小偏差都会随时间放大,导致最终偏离目标。
- 空间感缺失:缺乏全局视野,难以理解复杂的拓扑结构(如“绕过喷泉进入第三个房间”)。
- 计算昂贵:频繁的动作预测(Step-by-step)极大地消耗了边缘设备的算力。
作者认为,在现代工业机器人场景中,SLAM 预建图(Map-based)已经非常成熟。既然有了“上帝视角”的地图,为何不把导航看作一个端到端的图像生成或规划问题?
2. Methodology:Path Former 的魔法
NavOne 的核心架构由三个关键模块组成:
- Top-Down Map Fuser:将 RGB、占有率 (Occupancy) 和语义 (Semantic) 三种地图层通过通道拼接的方式融合,为模型提供丰富的物理语义信息。
- Path Former:这是模型的核心。它采用了带有一种改进的 Attention Residuals 的 ViT。
- 物理直觉:传统的 Transformer 每层只能看到上一层的输出。作者引入了“空间感知深度查询 (Spatial-Aware Depth Query)”,这允许模型在地图的不同位置,根据局部特征的需求,动态地从神经网络的不同深度(Abstraction Levels)抓取信息。
- Path Extractor:将模型输出的路径概率图和目标点分布,通过 A* 算法转化为机器人可执行的离散坐标。
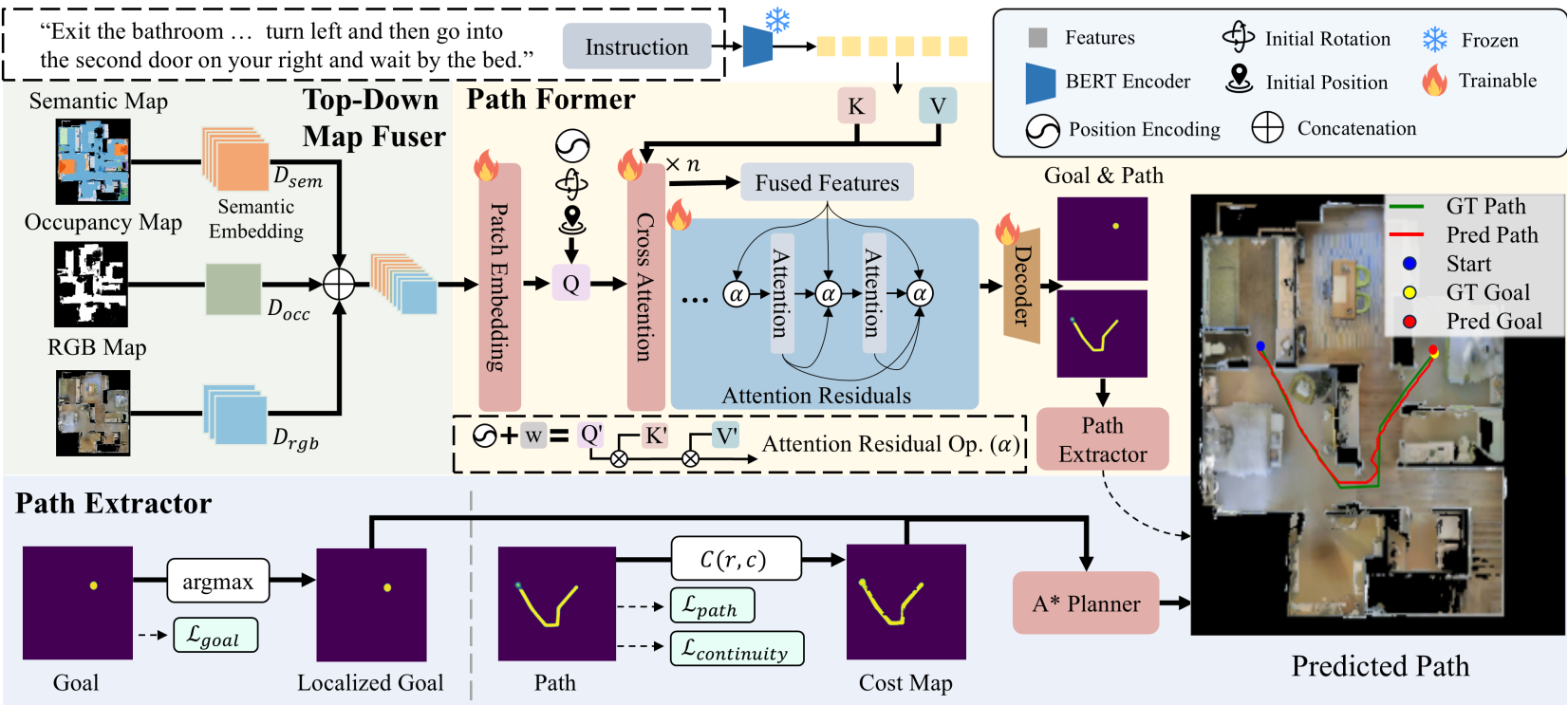 图 1:NavOne 架构概览,展示了从多模态地图输入到最终路径提取的全流程。
图 1:NavOne 架构概览,展示了从多模态地图输入到最终路径提取的全流程。
3. 实验战绩:速度与精度的双重飞跃
NavOne 在新构建的 R2R-TopDown 数据集上证明了其优越性。
3.1 性能对比 (Val Unseen)
在机器人从未见过的环境中,NavOne (AR-Full+SQ 变体) 表现出色:
- 成功率 (SR):0.47,明显优于早期的 WS-MGMap (0.39) 和 MapNav (0.40)。
- 效率对比:这是最令人惊叹的部分。在同一张 NVIDIA 4090D 显卡上,NavOne 的推理时间仅为 37ms,而经典的 ETPNav 需要 2970ms。这意味着 NavOne 能够支持极高频率的实时重规划(Re-planning)。
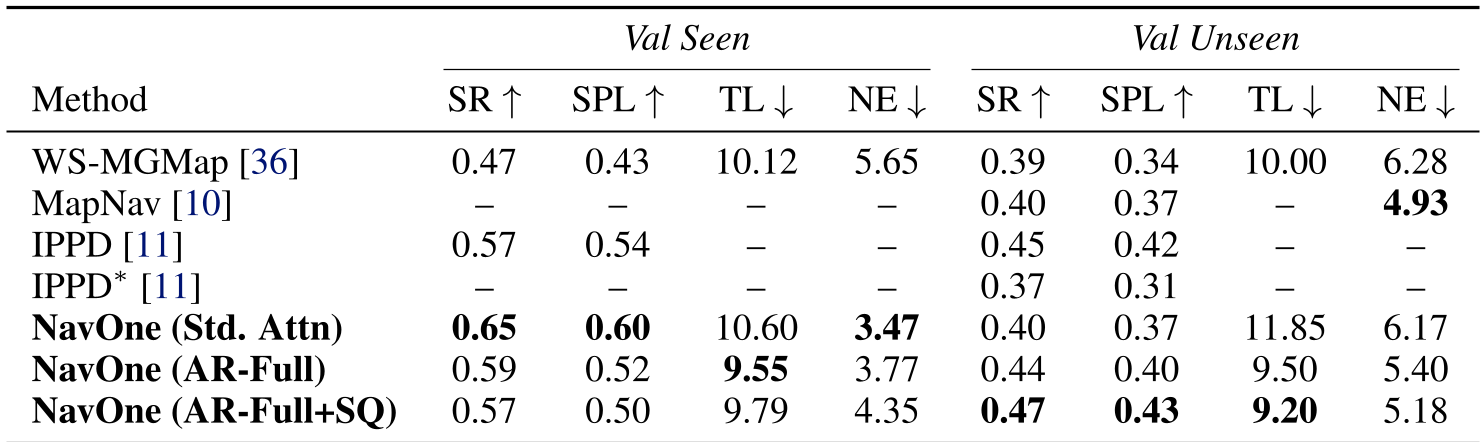 表 1:NavOne 与其他地图基座导航方法的量化对比。
表 1:NavOne 与其他地图基座导航方法的量化对比。
3.2 可视化分析
如图 5 所示,NavOne 生成的概率图 (Path Probability Map) 非常清晰地勾勒出了可行驶区域。即使在跨越多个房间、包含复杂指令(如“穿过双开门”、“在冰箱前停止”)的情况下,模型依然能精准锁定目标位置(红色星号)。
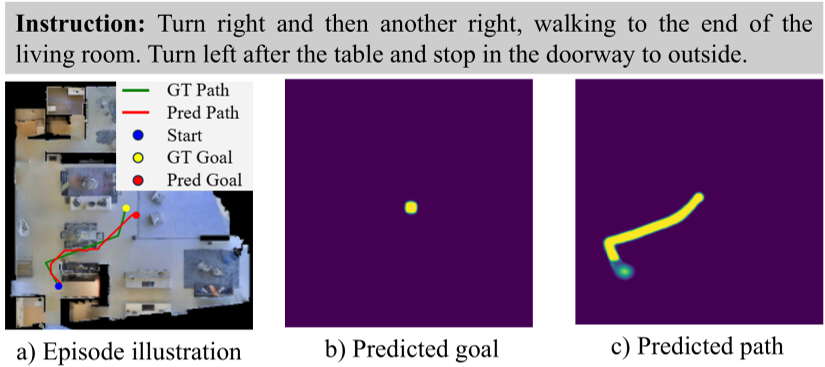 图 2:定性分析。可以看出模型输出的路径概率分布与 Truth 轨迹高度吻合。
图 2:定性分析。可以看出模型输出的路径概率分布与 Truth 轨迹高度吻合。
4. 深度洞察:特征的正交性 (Feature Orthogonality)
一个有趣的发现是,NavOne 将位置(Pose)信息直接通过逐元素加法注入到视觉 Token 中。在传统的深度学习中,这有时被认为过于简单,但在高维空间,视觉、指令、位置特征往往是近乎正交 (Orthogonal) 的。作者通过特征分析证明,这种简单的加法能够保持不同模态信息的互不干扰,实现了极简且有效的多模态融合。
5. 局限与展望
尽管 NavOne 表现强劲,但它目前依赖于静态地图。在现实世界中,走廊里可能会有突然出现的行人。作者在讨论中提到,未来的进化方向是在线地图更新 (Online Map Update) 与反应式规划的结合。
总结:NavOne 展示了当我们将导航问题转化为全局概率图预测时,所能获得的巨大效率收益。它不仅是一次模型结构的改进,更是对“机器人如何理解环境”这一命题的深刻思考。