This paper introduces neuralCAD-Edit, the first expert-level benchmark for multimodal 3D CAD model editing. It utilizes a dataset of 192 requests and 384 edits collected from professional engineers using speech, mouse interactions, and sketching, revealing that GPT-5.2—the current top-performing foundation model—still lags significantly behind human experts.
TL;DR
While AI has mastered 2D image editing and basic 3D generation, the realm of professional Computer-Aided Design (CAD) editing remained an unconquered fortress—until now. neuralCAD-Edit is a groundbreaking benchmark that moves beyond simple text boxes, challenging AI with the way human engineers actually work: by talking, pointing, and sketching directly on 3D models. The results? Even the most advanced models like GPT-5.2 are still significantly outperformed by human experts in a professional engineering context.
The "Text-Box" Limitation in 3D Engineering
In the professional world of mechanical engineering, instructions like "make this part slightly bigger" are frustratingly ambiguous. Designers naturally use a mix of modalities—they circle a specific fillet while saying "increase this radius," or they gesture toward a surface while describing a structural change.
Prior research focused heavily on Text-to-CAD generation, but generation is only half the battle. Editing—the iterative refinement to meet tolerances or fix errors—is where the real work happens. Current benchmarks failed to account for:
- Modality Interleaving: The temporal alignment of speech and mouse movement.
- B-Rep Geometry: The industry-standard "Boundary Representation" which is far more precise than the "noisy" meshes or point clouds AI usually handles.
Methodology: How to Test an AI Designer
The researchers recruited 10 expert designers to create "Easy, Medium, and Hard" editing requests. They didn't just type instructions; they recorded themselves using Autodesk Fusion, capturing screen video, audio, and drawing interactions.
To evaluate AI, the team built a sophisticated harness. Instead of asking the AI to "draw" a 3D model (which usually results in broken geometry), they allowed the AI to write and execute CadQuery scripts (Python-based CAD kernels). This essentially gives the AI a "CAD brain" that can iterate, catch errors, and visually inspect the results.
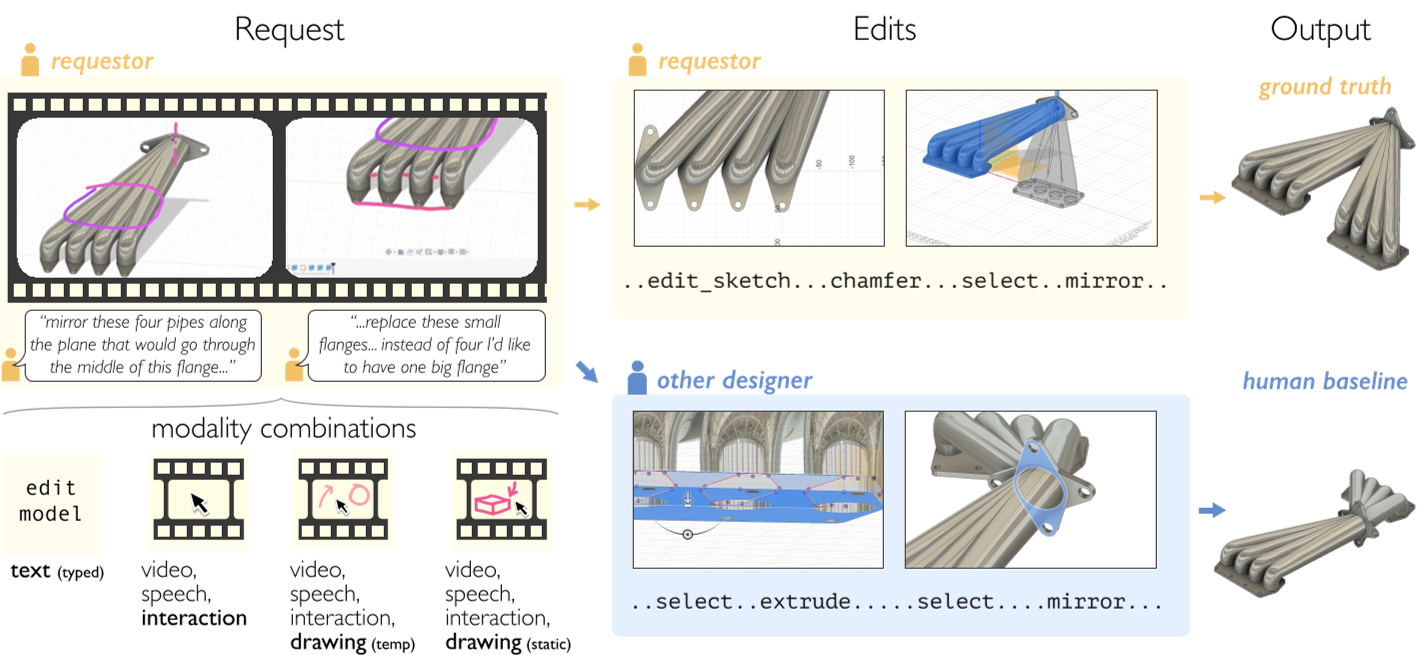 Figure 1: The neuralCAD-Edit workflow, showing how multimodal expert requests lead to a comparison between human and AI-generated outputs.
Figure 1: The neuralCAD-Edit workflow, showing how multimodal expert requests lead to a comparison between human and AI-generated outputs.
The Performance Gap: Data Doesn't Lie
The benchmark tested three frontier models: GPT-5.2, Gemini 3 Pro, and Claude Sonnet 4.5. The findings were a wake-up call for the industry:
- The Acceptance Gap: Human experts have an acceptance rate of 82%. GPT-5.2, the best model, only reached 25%.
- Efficiency: Humans are not only more accurate; they are faster. AI models often struggled with "visual reasoning," such as placing components in the wrong 3D coordinates because they couldn't "see" relative positions accurately.
- Multimodal Advantage: The study found that requests involving drawing (sketching) led to higher quality edits from humans, as they provided more spatial precision. However, current AIs actually struggled more with these complex inputs, showing that their ability to "sync" audio and visual cues is still immature.
 Figure 2: Qualitative comparison. Notice how the AI (Gemini/GPT) struggles with compositional reasoning—placing rotor blades at impossible angles or disconnected from the drone body.
Figure 2: Qualitative comparison. Notice how the AI (Gemini/GPT) struggles with compositional reasoning—placing rotor blades at impossible angles or disconnected from the drone body.
Deep Insight: Why is this so Hard for AI?
The paper identifies "Compositional Visual Reasoning" as the Achilles' heel. While an LLM might know the Python code for a "fillet," it doesn't truly understand the 3D topology of an assembly. It sees a 2D projection of a 3D object and often loses the sense of depth or structural connectivity (e.g., adding spokes that don't actually touch the wheel hub).
Furthermore, the benchmark revealed that VLM-based evaluation is currently biased. When asked to grade their own work, models like Gemini tended to be over-optimistic, whereas human experts were much stricter, focusing on whether the part could actually be manufactured.
Conclusion and Future Outlook
neuralCAD-Edit sets a new standard for embodied AI in the engineering space. It proves that for AI to become a true "co-pilot" for engineers, it needs:
- Better spatial-temporal grounding (linking the word "this" to a specific pixel in a specific video frame).
- An improved understanding of B-Rep topology vs. simple visual appearance.
- A "test-time scaling" approach where the model spends more "thinking time" on complex 3D edits.
This benchmark is a significant step toward moving AI from a "text-box" curiosity to a productive, multimodal partner in the high-stakes world of industrial design.