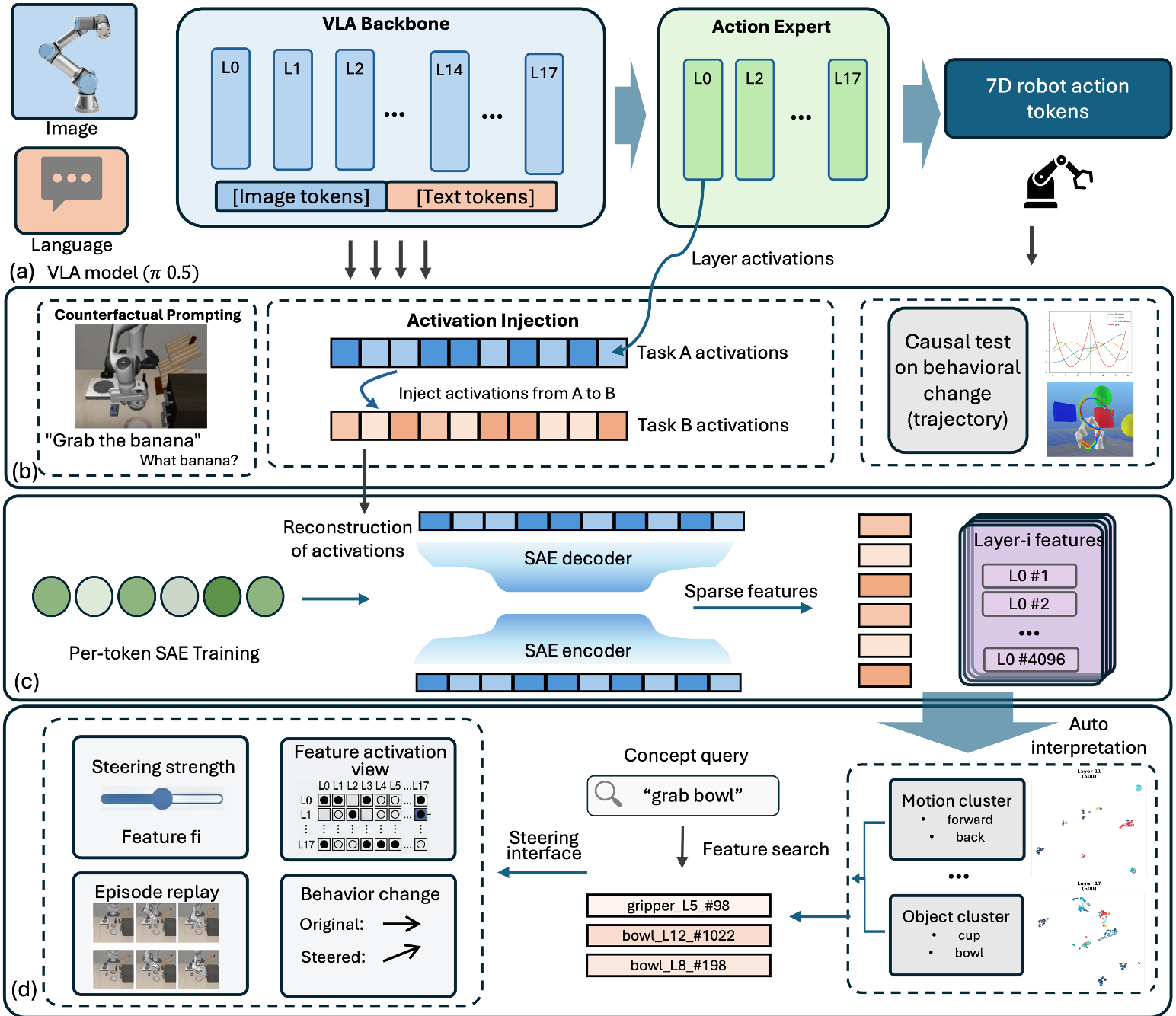
The paper presents a large-scale mechanistic interpretability study across six Vision-Language-Action (VLA) models (80M to 7B parameters), including π0.5 and OpenVLA. It introduces "Action Atlas," a platform for analyzing VLA internal representations using activation injection, sparse autoencoders (SAEs), and linear probes.
TL;DR
Researchers from Case Western Reserve University have conducted the first systematic mechanistic study of Vision-Language-Action (VLA) models, spanning six major architectures (π0.5, OpenVLA, GR00T, etc.). Their findings are a reality check for the field: VLA models are primarily driven by visual pathways and spatial motor priors, often ignoring language prompts when the visual scene is clear. By using Sparse Autoencoders (SAEs) and activation injection, they’ve mapped the "Action Atlas," revealing how specialized pathways handle the "what" (goal) versus the "how" (motor execution).
The "Black Box" of Robotic Control
We are seeing a surge in VLA models that can supposedly "understand" a command like "Open the middle drawer" and execute it. But is the robot actually listening? Or is it just seeing a cabinet and replaying a learned "drawer-opening" motion?
The authors argue that current VLA debugging is purely behavioral—watching the robot fail—whereas classical robotics allowed for the inspection of kinematics. To bridge this gap, they apply Mechanistic Interpretability, seeking to decompose dense neural activations into human-interpretable "concepts."
Methodology: Peeking Under the Hood
The team utilized four primary techniques across 394,000+ rollout episodes:
- Activation Injection: Replacing the internal state of a "null-prompt" robot with the states from a successful rollout to see if it recovers the behavior.
- Per-Token Sparse Autoencoders (SAEs): Breaking down the model's "black box" into sparse, monosemantic features. Crucially, they found that mean-pooling (averaging) activations across action tokens destroys the temporal structure needed for complex tasks.
- Pathway Analysis: Specifically in multi-component models like π0.5 and GR00T, they isolated which parts of the brain handle instructions versus movement.
Key Finding 1: Visual Pathway Dominance
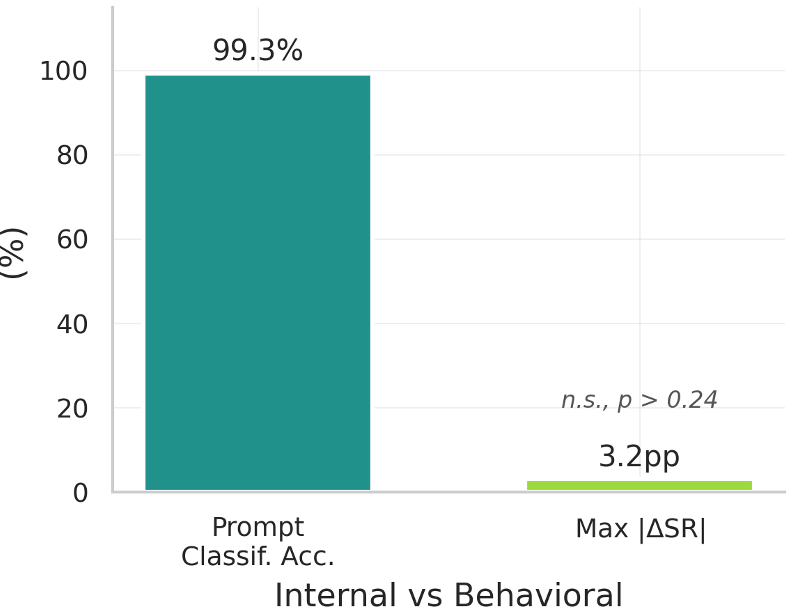
The most striking discovery is that the visual pathway almost entirely dictates behavior. In π0.5, injecting activations from a successful run into a robot with no prompt (null string) recovered 99.9% of the original behavior.
The robots aren't forming abstract task concepts; they are executing spatially bound motor programs. When researchers injected "Task A" activations into a scene for "Task B," the robot reached for the coordinates where the Task A object would have been, even if that space was now empty.
Key Finding 2: Language is the "Tie-Breaker"
Is language useless? Not quite. Its importance is suite-dependent:
- Low Ambiguity: If there's only one drawer to open, the robot ignores the text and just opens it.
- High Ambiguity: If there are multiple identical objects, language becomes the essential selector. In X-VLA, swapping prompts in a "Goal" suite caused success to plummet from 94% to 10%, whereas in "Object" suites, it remained resilient at 60% because the visual context was sufficient.
Key Finding 3: Pathway Specialization
In dual-pathway models (like π0.5), the roles are clearly divided:
- The VLM Pathway: Encodes goal semantics (the "What").
- The Action Expert: Encodes motor programs (the "How").
Injecting the "Expert" pathway activations causes the robot to move toward the wrong place (active error), while injecting the "VLM" pathway merely causes it to stall (passive error). This provides a new diagnostic tool for roboticists: if your robot stalls, check the VLM; if it moves wildly, check the Expert.
Causal Analysis & "Kill-Switches"
By ablating specific SAE features, the team identified 82+ manipulation concepts. They found "kill-switch" features—single neurons or latent directions where ablation causes 100% task failure. Interestingly, these features are usually located in the early layers, where the model first "binds" objects to coordinates.

Conclusion: A Roadmap to Robustness
The study highlights that VLAs are rich in representations but brittle in execution. The fact that behavior is so tethered to absolute spatial coordinates explains why current robots fail so easily when an object is moved slightly (the "position shift" collapse).
For the robotics community, the Action Atlas (available at action-atlas.com) serves as a vital resource for understanding why these models fail and how we might design future VLAs that are more responsive to language and more adaptable to changing environments.