FrameCrafter is a novel view synthesis (NVS) framework that repurposes pretrained video diffusion models (e.g., Wan2.1) as powerful multi-view priors. By formulating sparse NVS as a permutation-invariant video completion task, it achieves SOTA performance on benchmarks like DL3DV and Mip-NeRF 360 using significantly less multi-view supervision.
TL;DR
FrameCrafter challenges the status quo of Novel View Synthesis (NVS) by demonstrating that video diffusion models make better 3D priors than image models. By modifying a pretrained video transformer (Wan2.1) to treat frames as an unordered set rather than a sequence, the authors achieve SOTA results with 80x less training data than previous leading methods.
Background: Why Videos over Images?
The quest for high-fidelity Novel View Synthesis from sparse inputs () has recently gravitated toward generative models. While image diffusion models (like Stable Diffusion) provide great textures, they are "3D-blind" by nature. To make them work for NVS, researchers usually have to "force-feed" them massive amounts of multi-view data.
The authors of FrameCrafter suggest a more elegant path: Video models are naturally 3D-aware. A video of a room is essentially a sequence of views with temporal consistency. The "world understanding" required to generate a stable video is remarkably similar to the geometric reasoning needed for NVS.
The Core Challenge: The "Time" Bias
If video models are already 3D-aware, why hasn't this been done effectively before? The answer lies in permutation invariance.
- Video Models expect a strict temporal order (Frame 1 2 3) and use causal VAEs that compress temporal data.
- Sparse NVS provides an unordered set of "witness" images. There is no meaningful "time" between five random photos of a chair.
To bridge this gap, FrameCrafter "teaches" the video model to forget time.
Methodology: Repurposing the Transformer
The team introduced three critical modifications to transform a video generator into a multi-view reasoner:
1. Per-View VAE Encoding
Standard video VAEs use 3D convolutions that blend frames together. FrameCrafter forces the encoder to process each input view independently as a "single-frame video." This prevents the model from mixing features of unrelated views prematurely and ensures that changing the order of inputs doesn't change the latent representation.
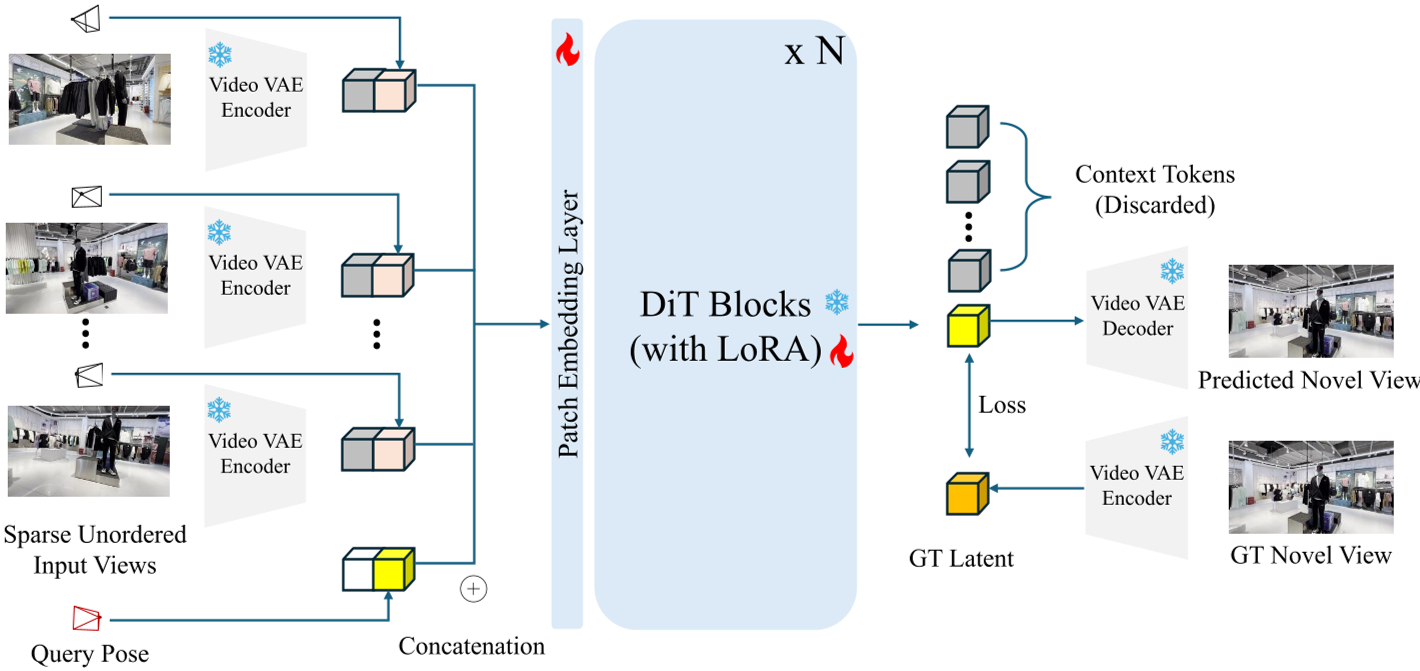 Fig 1: The FrameCrafter pipeline. Note how input views and target rays are concatenated in the latent space.
Fig 1: The FrameCrafter pipeline. Note how input views and target rays are concatenated in the latent space.
2. Query-Centered Plücker Rays
Geometric control is injected through Plücker ray maps. Crucially, the authors align the world coordinate system to the target query view. This makes the system invariant to the global orientation of the input set.
3. Killing the "Clock": Zero-Temporal RoPE
Modern transformers use Rotary Positional Embeddings (RoPE) to keep track of time. FrameCrafter simply removes the temporal component of RoPE. Without a "time stamp," the model is forced to rely solely on camera geometry (the rays) to understand where each view is in 3D space.
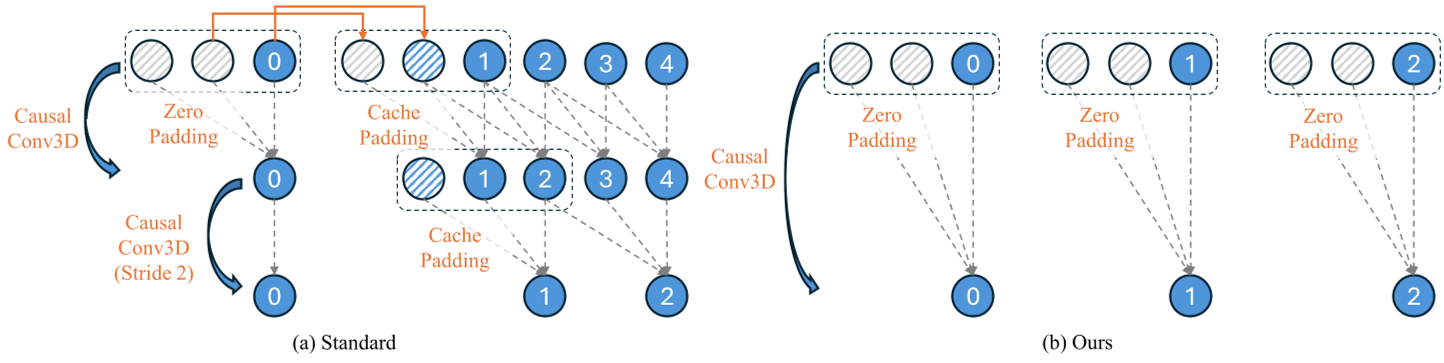 Fig 2: Comparison between standard causal encoding and FrameCrafter's independent encoding.
Fig 2: Comparison between standard causal encoding and FrameCrafter's independent encoding.
Results: Efficiency is King
The most striking result is the scaling effort.
- SEVA (Prior SOTA): Trained on 80,000 scenes + 340,000 objects.
- FrameCrafter: Trained on only 1,000 scenes.
Despite the fraction of data, FrameCrafter (using the Wan2.1-14B backbone) outperformed SEVA across almost all perceptual and pixel-level metrics. It also showed incredible zero-shot generalization on the Mip-NeRF 360 dataset.
 Fig 3: Qualitative comparison showing FrameCrafter's superior geometric consistency over SEVA and Aether.
Fig 3: Qualitative comparison showing FrameCrafter's superior geometric consistency over SEVA and Aether.
Critical Insight & Conclusion
One of the most provocative claims of this paper is how easily these "World Models" can unlearn time. The authors found that removing temporal ordering didn't degrade performance—it actually improved it for multi-view tasks. This suggests that current video models might actually be "3D Scene Models" in disguise, capturing the static geometry of the world more effectively than they capture the true dynamics of motion.
Takeaway for the Industry: For AI teams working on 3D reconstruction or digital twins, the fastest route to high-fidelity results may no longer be massive 3D datasets, but rather the lightweight adaptation of large-scale video foundation models.